![[Home]](http://www.bayleshanks.com/cartoonbayle.png)
Table of Contents for Programming Languages: a survey
http://www.strchr.com/x86_machine_code_statistics
distribution by instruction length: 1 4.77% 2 17.67% 3 18.72% 4 12.28% 5 13.78% 6 15.60% 7 13.30% 8 2.46% 9 0.01% 10 1.02% 11 0.41%
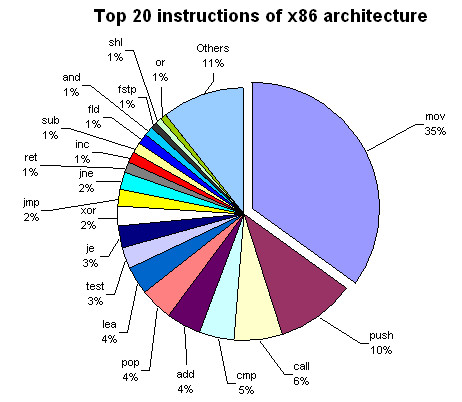
top 20 instructions: mov 35% push 9.99941228328% call 6.01175433441% cmp 4.62415515721% add 4.31295915369% pop 4.08257419924% lea 3.85953570379% test 2.79400528945% je 2.74316779312% xor 2.44255069057% jmp 2.22421392889% jne 2.19541580958% ret 1.45224801646% inc 1.36320893329% sub 1.32677049662% fld 1.29180135175% and 1.10843373494% fstp 1.03967087864% shl 0.84748751102% or 0.738172200999% Others 10.5436379665%
number of operands: 0 3% 1 37% 2 60%
addressing modes: immediate 20% register 56% absolute address 1% indirect address 23%
instruction formats (note the destination comes first in the following): register-memory 35.4% register-register 26.5% register-immediate 16% memory-register 15.2% memory-immediate 6.8%
" The most popular instruction is MOV (35% of all instructions). Note that PUSH is twice more common than POP. These instructions are used in pairs for preserving EBP, ESI, EDI, and EDX registers across function calls, and PUSH is also used for passing arguments to functions; that's why it is more frequent. CALLs to functions are also very popular.
More than 50% of all code is dedicated to moving things between registers and memory (MOV), passing arguments, saving registers (PUSH, POP), and calling functions (CALL). Only 4th instruction (CMP) and the following ones (ADD, LEA, TEST, XOR) do actual calculations.
From conditional jumps, JE and JNE (equal and not equal) are the most popular. CMP and TEST are commonly used to check conditions. The percentage of the LEA instruction is surprisingly high, because MS VC++ compiler generates it for multiplications by constant (e.g., LEA eax, [eax*4+eax]) and for additions and subtractions when the result should be saved to another register, e.g.:
LEA eax, [ecx+04] LEA eax, [ecx+ecx]
The compiler also pads the code with harmless forms of LEA (for example, the padding may be LEA edi, [edi]). As is easy to see, the top 20 instructions include all logical operations (AND, XOR, OR) except NOT.
Though LAME encoder uses MMX technology instructions, their share in the whole code of the program is very low. Two FPU instructions (FLD and FSTP) appears in the top 20.
But what about other instructions? It turns out that multiplication and division are very rare: IMUL takes 0.13%, IDIV takes 0.04%, and both MUL and DIV do 0.02%. Even string operations such as REPZ SCASB or REPZ MOVSB are more common (0.32%) than all IMULs and IDIVs. On the contrary, FMUL is more common than FADD (0.71% versus 0.27%). "
also at [1]
Table 3:Most used x86 instructions...in DOS application
mov reg reg shl push add inc pop jz les shl 2 arg mov reg mem mov reg mem
Rank instruction # of MOP execution frequency 1 mov r16 r16 1 12.5% 2 shl r16 1 6.8% 3 push r16 2 5.1% 4 add r16 r16 1 5.1% 5 inc r16 1 4.1% 6 pop r16 2 4.0% 7 jz i8 1 3.6% 8 les r16 m16d8 4 3.3% 9 shl r16 i8 1 3.0% 10 mov r16 m16d0 1 2.9% 11 mov r16 m16d8 1 2.7% 12 jge i8 1 2.0% 13 wait 1 1.8% 14 cmp m16d16 i8 2 1.7% 15 jnz i8 1 1.6% 16 dec r16 1 1.5% 17 jmpn i8 1 1.5% 18 cmp m16d16 r16 2 1.5% 19 jl i8 1 1.3% 20 calln i16 ? 1.3% 21 mov r16 i16 1 1.2% 22 mov r8 r8 1 1.1% 23 mov r16 m16d16 1 1.1% 24 jle i8 1 1.0% 25 or r16 r16 1 1.0% 26 cmp r16 m16d8 2 1.0% 27 mov m16d0 r16 1 0.9% 28 mov r8 m8d0 1 0.9% 29 retn ? 0.8% 30 push m16d8 3 0.7% 31 cmp r16 m16d0 2 0.7% 32 jae i8 1 0.7% 33 cmp r16 i8 1 0.7% 34 stosb 2 0.6% 35 mov m16d8 r16 1 0.6% 36 scasb 3 0.6% 37 mov m16d16 r16 1 0.6% 38 movsw 4 0.6% 39 sub r16 r16 1 0.6% 40 movsb 4 0.6% 41 cmp m8d0 i8 2 0.5% 42 retf ? 0.5% 43 jb i8 1 0.5% 44 xchg r16 r16 1 0.4% 45 xor r16 r16 1 0.4% 46 add r16 i8 1 0.4% 47 clc 1 0.3% 48 cmp r8 m8d0 2 0.3% 49 jmpn i16 1 0.3% 50 jg i8 1 0.3% 51 cmp i16 r16 1 0.3% 52 stosw 2 0.3% 53 loop i8 2 0.3% 54 imul r16 r16 i16 1 0.3% 55 cmp m16d0 i8 2 0.3% 56 add r16 m16d8 2 0.3% 57 cmp r16 m16d16 2 0.3% 58 or r8 r8 1 0.3% 59 imul r16 r16 i8 1 0.3% 60 les r16 m16d0 4 0.3% 61 mov m8d0 r8 1 0.3% 62 fld m32d0 3 0.3% 63 xor r16 m16d16 2 0.2% 64 cmp r8 i8 1 0.2% 65 leave 3 0.2%
TOTAL 90.8%
Table 4: Most used x86 instructions...in Windows95 applications
push mov reg mem jz pop mov reg reg inc mov reg mem xor jnz calln
Rank instruction # of MOP execution frequency 1 push r32 2 8.4% 2 mov r32 m32d8 1 7.1% 3 jz i8 1 5.7% 4 pop r32 1 4.2% 5 mov r32 r32 1 4.0% 6 inc r32 1 3.0% 7 mov r32 m32d0 1 2.9% 8 xor r32 r32 1 2.7% 9 jnz i8 1 2.7% 10 calln i32 ? 2.2% 11 cmp r32 r32 1 2.2% 12 mov r16 m16d8 1 2.1% 13 test r32 r32 1 2.1% 14 retn i32 ? 1.9% 15 jl i8 1 1.9% 16 mov r8 m8d8 1 1.7% 17 cmp r32 i32 1 1.6% 18 add r32 r32 1 1.5% 19 add r32 i8 1 1.3% 20 cmp m32d32 i8 2 1.3% 21 jz i32 1 1.3% 22 lea r32 m32d0 1 1.3% 23 lea r32 m32d8 1 1.3% 24 cdq 1 1.3% 25 mov m32d8 r32 1 1.3% 26 cmp r8 i8 1 1.2% 27 sub r32 r32 1 1.2% 28 cmp m32d8 i8 2 1.1% 29 jmpn i8 1 1.1% 30 sub r32 m32d8 1 1.1% 31 and r32 i8 1 1.0% 32 test r8 i8 1 0.9% 33 jnz i32 1 0.9% 34 mov r16 m16d0 1 0.8% 35 mov r8 m8d0 1 0.8% 36 mov m16d8 r16 1 0.7% 37 cmp m32d0 i8 2 0.7% 38 mov m32d0 r32 1 0.7% 39 jae i8 1 0.7% 40 mov r32 m32d32 1 0.6% 41 movzx r32 r32 1 0.6% 42 call m32d0 ? 0.6% 43 sub r32 i8 1 0.5% 44 mov r32 i32 1 0.5% 45 shr r32 i8 1 0.5% 46 movsw 4 0.5% 47 jle i8 1 0.5% 48 imul r32 r32 i32 1 0.5% 49 movsb 4 0.4% 50 jg i8 1 0.4% 51 and r8 i8 1 0.4% 52 and r16 i16 1 0.4% 53 push m32d8 3 0.4% 54 cmp r16 i16 1 0.4% 55 sub r32 i32 1 0.4% 56 movzx r8 m8d0 1 0.4% 57 mov m8d0 r8 1 0.3% 58 dec r32 1 0.3% 59 test r8 r8 1 0.3% 60 jmpn i32 1 0.3% 61 retn ? 0.3% 62 call r32 ? 0.3% 63 cmp m32d0 r32 2 0.3% 64 push i8 2 0.3% 65 cmp m16d8 r16 2 0.3%
TOTAL 90.5%
Table 5: Micro-operation frequencies
Rank Micro-operation Frequency 1 ld 19.7% 2 mov 9.6% 3 st 9.5% 4 subin 5.5% 5 movm (masked mov) 4.7% 6 shl 4.5% 7 asidn 4.1% 8 cmp 3.6% 9 addin 3.5% 10 add 3.4% 11 inc 2.9% 12 cmpi 2.7% 13 jiz 2.5% 14 wrseg 2.3% 15 ji 2.1% 16 shli 1.8% 17 movi 1.3% 18 jinl 1.2% 19 dec 1.2%
ld mov st subin movm (masked mov) shl asidn cmp addin add inc cmpi jiz 20 jinz 1.1%
(bayle: i have no idea what movm and asidn do; see below for some of the others)
" The micro operations are based on the superscalar model Table 5 lists the most used micro operations. The most significant micro operations are ld (load from memory), st (store to memory) and mov (register-to- register data movement).
...
Optimization for frequently executed instructions: PUSH and POP "
The subin MOP subtracts the register sp with an immediate value (2) and stores the result back to the register sp "
PUSH = subin; st POP = ld; addin
" SHL is simply shift left. SHL is cool because it's a quick way to multiply (amongst other things) a value by 2,4,8, etc because every time you SHL you double the value. "
" measurements on the VAX show that these addressing modes (immediate, direct, register indirect, and base+displacement) represent 88% of all addressing mode usage. • similar measurements show that 16 bits is enough for the immediate 75 to 80% of the time • and that 16 bits is enough of a displacement 99% of the time. " -- http://www.sdsc.edu/~allans/cs141/L2.ISA.pdf
Table 6.1. Dynamic Instruction Execution Frequencies for important Forth primitives.
NAMES FRAC LIFE MATH COMPILE AVE CALL 11.16% 12.73% 12.59% 12.36% 12.21% EXIT 11.07% 12.72% 12.55% 10.60% 11.74% VARIABLE 7.63% 10.30% 2.26% 1.65% 5.46% @ 7.49% 2.05% 0.96% 11.09% 5.40% 0BRANCH 3.39% 6.38% 3.23% 6.11% 4.78% LIT 3.94% 5.22% 4.92% 4.09% 4.54% + 3.41% 10.45% 0.60% 2.26% 4.18% SWAP 4.43% 2.99% 7.00% 1.17% 3.90% R> 2.05% 0.00% 11.28% 2.23% 3.89% >R 2.05% 0.00% 11.28% 2.16% 3.87% CONSTANT 3.92% 3.50% 2.78% 4.50% 3.68% DUP 4.08% 0.45% 1.88% 5.78% 3.05% ROT 4.05% 0.00% 4.61% 0.48% 2.29% USER 0.07% 0.00% 0.06% 8.59% 2.18% C@ 0.00% 7.52% 0.01% 0.36% 1.97% I 0.58% 6.66% 0.01% 0.23% 1.87%
AND 0.17% 3.12% 3.14% 0.04% 1.61% BRANCH 1.61% 1.57% 0.72% 2.26% 1.54% EXECUTE 0.14% 0.00% 0.02% 2.45% 0.65%
Instructions: 2051600 1296143 6133519 447050
Table 6.2. Static Instruction Execution Frequencies for important Forth primitives.
6.3.2 Static instruction frequencies
NAMES FRAC LIFE MATH COMPILE AVE CALL 16.82% 31.44% 37.61% 17.62% 25.87% LIT 11.35% 7.22% 11.02% 8.03% 9.41% EXIT 5.75% 7.22% 9.90% 7.00% 7.47% @ 10.81% 1.27% 1.40% 8.88% 5.59% DUP 4.38% 1.70% 2.84% 4.18% 3.28% 0BRANCH 3.01% 2.55% 3.67% 3.16% 3.10% PICK 6.29% 0.00% 1.04% 4.53% 2.97% + 3.28% 2.97% 0.76% 4.61% 2.90% SWAP 1.78% 5.10% 1.19% 3.16% 2.81% OVER 2.05% 5.10% 0.76% 2.05% 2.49% ! 3.28% 2.12% 0.90% 2.99% 2.32% I 1.37% 5.10% 0.11% 1.62% 2.05% DROP 2.60% 0.85% 1.69% 2.31% 1.86% BRANCH 1.92% 0.85% 2.09% 2.05% 1.73% >R 0.55% 0.00% 4.11% 0.77% 1.36% R> 0.55% 0.00% 4.68% 0.77% 1.50% C@ 0.00% 3.40% 0.61% 0.34% 1.09%
Instructions: 731 471 2777 1171
Table 6.3. Dynamic Instruction Execution Frequencies for RTX 32P Instruction types.
FRAC LIFE MATH AVEOP 57.54% 46.07% 49.66% 51% CALL 19.01% 26.44% 19.96% 22% EXIT 10.80% 12.53% 16.25% 13% OP+CALL 0.00% 0.00% 0.00% 0% OP+EXIT 0.00% 0.00% 0.00% 0% CALL+EXIT 0.00% 0.00% 0.00% 0% OP+CALL+EXIT 0.00% 0.00% 0.00% 0% COND 5.89% 9.95% 6.56% 7% LIT 6.76% 5.01% 7.57% 6% LIT-OP 0.00% 0.00% 0.00% 0% VARIABLE-OP 0.00% 0.00% 0.00% 0% VARIABLE-OP-OP 0.00% 0.00% 0.00% 0%
Instructions: 8381513 1262079 940448
OP-OP 0.00% 0.00% 0.00% 0%
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.230.9543&rep=rep1&type=pdf The Common Case in Forth Programs (also at www.complang.tuwien.ac.at/papers/gregg+01euroforth.ps.gz ) Figure 5: Dynamically frequent instructions for large benchmarks:
prims2x gray brew brainless benchgc pentomino lit 15.26 ;s 15.08 lit 22.31 lit 19.77 lit 8.20 lit 24.57 @ 12.79 @ 14.88 @ 19.13 @ 15.79 ;s 8.05 + 12.07 ;s 12.18 call 14.07 ;s 11.18 ;s 8.86 call 7.94 ?branch 12.05 call 11.13 lit 12.17 call 10.00 call 8.38 @ 7.09 dup 11.03 ?branch 4.78 ?branch 3.89 + 7.28 + 7.80 and 6.14 c@ 10.24 swap 3.89 + 3.82 ?branch 3.94 ?branch 4.63 dup 5.90 0= 8.89 + 3.34 useraddr 3.18 ! 3.52 cells 4.18 over 5.67 c! 5.93 0= 2.76 dup 2.44 dup 3.11 dup 4.11 i 5.47 over 4.96 dup 2.31 ! 2.41 +! 1.61 and 2.63 (loop) 4.75 1+ 3.64 r> 1.77 over 2.13 swap 1.32 = 2.43 = 4.55 @ 2.27 >r 1.77 swap 1.73 execute 1.30 over 2.17 c@ 4.40 > 1.81
c@ 1.60 >r 1.69 = 1.12 swap 1.47 swap 3.48 ;s 0.44 and 1.41 execute 1.49 cells 1.11 ?dup 1.46 >r 3.00 execute 0.37 >l 1.26 0= 1.32 mod 0.98 i 1.04 + 2.72 drop 0.36 useraddr 1.25 and 1.12 i 0.96 * 0.99 r> 2.11 call 0.07 count 1.10 cell+ 1.11 drop 0.93 drop 0.97 - 1.35 (loop) 0.04 cells 1.06 = 1.04 branch 0.82 (loop) 0.84 rshift 1.33 i 0.02 ! 1.04 2dup 0.97 >r 0.78 or 0.80 0= 1.26 emit-file 0.02 over 1.03 ?dup 0.84 r> 0.71 useraddr 0.72 drop 1.25 * 0.02
PICOJAVA-I: THE JAVA VIRTUAL MACHINE IN HARDWARE:
Table 1. Dynamic opcode distributions. Instruction class Dynamic frequency (percentage) Local-variable loads 34.5 Local-variable stores 7.0 Loads from memory 20.2 Stores to memory 4.0 Compute (integer/floating-point) 9.2 Branches 7.9 Calls/returns 7.3 Push constant 6.8 Miscellaneous stack operations 2.1 New objects 0.4 All others 0.6
local-variable loads: 34.5% local-variable stores: 7% loads from memory: 20.2% stores to memory: 4% compute (integer/floating point): 9.2% branches: 7.9% calls/returns: 7.3% push constant: 6.8% misc stack ops: 2.1% new objects: 0.4% all others: 0.6%
memory reference: 34% (LOAD (load and push to top of stack) 18%, STOR (store from top of stack) 7%, LDX (load into index register) 3%) immediate: 17% branches: 16% stack ops: 16% privileged memory reference: 5% field & bit: 5% linkage & control: 5% shifts: 1%
Table 3. Distribution of memory references (note: by addressing mode) address type nominal use of address mode percent of LOADs, percent of STORs DB+ global scalar 7 7 DB+, I, X global array 3 10 Q- LOAD: value parameter 20 Q- STOR: return value 17 Q-, I reference parameter scalar 4 5 Q-, I, X array parameter 5 6 Q+ local scalar 27 44 Q+, I, X local array 7 4 S- temporary 2 1 P+- constant 12 not allowed direct array (no indirection) 13 6
note: the DB register points to globals; X is the index register; the Q register points to locals; S points to the stack; P is the program counter; I presumably means indirection/dereferencing.
branches: 68% conditional upon status flags 19% unconditional 13% conditional upon the first bit on top of the stack
81% of conditional branches and 86% of unconditional were direct P-relative; the rest are indirect (the operand specifies a location L which itself contains a 16-bit displacement from L; L plus the displacement is the branch target)
branch distances (of direct branches only): distance % of direct BR % of direct BCC 128-225 5 64-127 3 32-63 3 16-31 42 20 8-15 10 30 4-7 12 26 2-3 15 23 1 9
"
Stackops. The stack operators are those whose operands are implicitly at the top of the stack. Their operation was demonstrated by Ackermann's function. One result of the measurement was that 5 percent of all instructions executed were paired stackops. Paired stackops reduce memory traffic to the CPU and improve the code com- pression otherwise inherent in the stack architecture. Of the most common stackops, only one is an arithmetic operator as shown in Table 5.
Table 5. Dominant stackops.
DUP 3% Duplicate top of stack STAX 3% Store top of stack in index reg and delete ZERO 2% Push a zero onto the top of stack CMP 1% Compare top two words, set conditon code XCH 1% Exchange top two words DECA 1% Subtract one from the top of stack
Again, percentages are expressed as a fraction of all instructions executed. Much of the use of DUP could probably be eliminated by including a nondestructive STOR instruction, which does not pop the stack, but merely copies it to the specified DB-, Q-, or S-relative location. "
" Immediates. One quarter of the immediate group were executions of LDXI (load X immediate).
...
Table 6. Dominant immediates (aside from LDXI).
CMPI 3% Compare immediate value with TOS ADDI 2% Add immediate value to the TOS LDI 2% Load immediate value to the TOS SED 2% Enable, disable external interrupts ANDI 1% And immediate with the TOS
Table 7. Ten most frequent instructions in a multiprogramming benchmark.
LOAD 18% Load word onto the top of stack BCC 10% Branch on status condition STOR 7% Store word off the top of stack LDXI 4% Load immediate value into index register DUP 3% Duplicate the top of stack STAX 3% Store top of stack into index register BR 3% Unconditional branch CMPI 3% Compare immediate value with top of stack LDX 3% Load index register from memory EXF 3% Extract bit field from the top of stack
addressing mode usage (3 programs avg, 17% to 43%):
Register deferred (indirect): 13% avg, 3% to 24%) scaled 7% avg, 0% to 16% memory 3% avg, 1% to 6% misc 2% avg, 0% to 3%
"data addressing modes that are important: displacement, immediate, register indirect. Displacement size should be 12 to 16 bits. Immediate size should be 8 to 16 bits"
"
Typical Operations
Data Movement load/store (from/to memory) memory-to-memory move register-to-register move input/output (from/to I/O device) push/pop (to/from stack)
Arithmetic integer (binary + decimal) or FP add, subtract, multiply, divide
Logical not, and, or, set, clear
Shift shift left/right, rotate left/right
Control (Jump/Branch) unconditional, conditional
Subroutine Linkage call, return
Interrupt trap, return
Synchronization test&set (atomic read-modify-write)
String search, translate "
"
Addressing Modes Addressing mode Example Meaning Register Add R4,R3 R4 R4+R3 Immediate Add R4,#3 R4 R4+3 Displacement Add R4,100(R1) R4 R4+Mem[100+R1] Register indirect Add R4,(R1) R4 R4+Mem[R1] Indexed Add R3,(R1+R2) R3 R3+Mem[R1+R2] Direct or absolute Add R1,(1001) R1 R1+Mem[1001] Memory indirect Add R1,@(R3) R1 R1+Mem[Mem[R3]] Auto-increment Add R1,(R2)+ R1 R1+Mem[R2]; R2 R2+d Auto-decrement Add R1,-(R2) R2 R2-d; R1 R1+Mem[R2] Scaled Add R1,100(R2)[R3] R1 R1+Mem[100+R2+R3*d]
"
www.ece.iupui.edu/~johnlee/ECE565/lecture/ECE565.Ch2-ISA.pdf:
"
Top ten 80x86 instructions Rank Instruction % total execution 1 load 22% 2 conditional branch 20% 3 compare 16% 4 store 12% 5 add 8% 6 and 6% 7 sub 5% 8 move reg-reg 4% 9 call 1% 10 return 1%
Total 96%
From five SPECint92 program "
http://cmsc411.com/topics/instruction-set-architectures-action
" Support these simple instructions, since they will dominate the number of instructions executed: load, store, add, subtract, move register-register, and shift Compare equal, compare not equal, compare less, branch (with a PC-relative address at least 8 bits long), jump, call, and return "
" Use fixed instruction encoding if interested in performance, and use variable instruction encoding if interested in code size "
" Operand Size Usage
Frequency of reference by size
0% Doubleword (64-bit): integer: 0% floating point: 69%
Word: integer: 74% floating point: 31%
Halfword: integer: 19% floating point: 0%
Byte: integer: 7% floating point: 0%
Support these data sizes and types: 8-bit, 16-bit, 32-bit integers and 32-bit and 64-bit IEEE 754 floating point numbers
" -- http://www.ece.northwestern.edu/~kcoloma/ece361/lectures/Lec04-mips.pdf
A Few of the Most Frequent Instructions Complier % Sum VlsiCheck? % Sum Jump If !=0 10.30 10.3 Load Local Double-Word 7.04 7.04 Load LO 8.96 19.26 Load LO 6.39 13.43 Read Field 7.50 26.76 Store Local Double-Word 5.15 18.58 Load Immed 16-bit 5.51 32.27 Recover Stack Item 4.93 23.51 Add 4.94 37.21 Load Immed 8-bit 4.60 28.11 Read Indirect 4.6 41.81 Load Immed. 0 3.92 32.03 Recover Stack Item3.51 45.32 Read Indirect 3.11 35.14 Index Off Pointer Load GO 2.99 48.31 Jump If !=O 3.03 38.17
for two programs, a compiler (complier in chart; sic) and VlsiCheck?
" Statistics For "Standard" Partition Compiler VlsiCheck? Group % Sum Group % Sum LdlStore? 32.97 32.97 LdlStore? 35.15 35.15 RIW 19.59 52.57 RIW 14.14 49.29 CondJumps? 16.82 69.39 Stack Ops 12.23 61.52 Ld Immed 11.43 80.82 ALU Ops 10.76 72.28 ALU Ops 8.14 88.96 Ld Immed 10.53 82.81 Stack Ops 3.87 92.84 CondJumps? 8.42 91.23 Xfers 3.55 96.39 Xfers 5.31 96.54 Jumps 2.25 98.64 Jumps 1.75 98.29 Mise 1.35 99.99 Mise 1.67 99.96 Processes 0.01 100.0 Processes 0.04 100.0
Branches, Xfers, and Jumps Compiler VlsiCheck? Group % Sum Group % Sum CondJumps? 16.82 16.82 CondJumfs? 8.42 8.42 Xfers 3.55 20.37 Xfers 5.3 13.73 Jumps 2.25 22.62 Jumps 1.75 15.48
The tables ·and figures below show the most frequently executed instructions within each group of the Standard Partition. For the sake of brevity, only the first three or four instructions in each group are shown. Note that within each group only a few instructions account for most of the activity in that group, and that bounds and NIL checking (in Stack Ops group) cost only 5.14% of all instructions, even in a program like VlsiCheck?, that extensively reads and writes memory.
Opcode mnemonics are provided in the appendix.
Compiler VlsiCheck? Instr Group Over all Sum Instr Group Over all Sum
LdlStore?=32.97% Over All LdlStore?=35.15% Over All LLO 27.16 8.96 8.96 LLDB 20.04 7.04 7.04 LGO 9.06 2.99 11.95 LLO 18.17 6.39 13.43 LL1 7.29 2.40 14.35 SLDB 14.65 5.15 18.58 LL2 5.02 1.76 20.34
R/W=19.59% Over All R/W=14.14% Over All RF 38.23 7.49 7.49 RILP 21.96 3.11 3.11 RO 23.68 4.64 12.13 RO 13.00 1.84 4.95 RXLP 6.86 1.34 13.47 RDBL 10.38 1.47 6.42 RSTR 9.66 1.37 7.79
CondJumps?= 16.82% Over All Stack Ops = 12.23% Over All JZNEB 61.18 JZNEB 61.57 10.29 10.29 PUSH 40.30 4.93 4.93 JZEQB 7.87 1.32 11.61 NILCKL 21.78 2.66 7.59 JEQB 5.71 .96 12.57 BNDCK 10.37 1.33 8.92 NILCK 9.42 1.15 10.07
Ld Immed = 11.43% Over All ALU Ops=10.76% Over All LIW 47.31 5.41 5.41 MUL 24.16 2.60 2.60 LIB 13.95 1.59 7.00 ADD 21.62 2.33 4.93 LIO 13.49 1.54 8.54 SUB 12.98 1.40 6.33 LIl 9.79 1.12 9.66 INC 11.33 1.22 7.55
"
Appendix: Instruction Descriptions LLi, LGi, SLi, SGi Load or Store from the Local or Global Frame the i th variable LLB, LLDB, SLB, SLOB RF Ri Load or Store from the Local or Global Frame given a byte offset "0" indicates a double- word quantity Read a bit field from a 16-bit value Read the i th word from the pointer on the top of the stack RXLP,RILP Read a value, indexed or indirect with post indexing JZNEB, JZEQB, JEQB Conditional branches with a byte offset for the PC LIW, LIB, Li Load immediate values (word, byte, small constant) RECOVER Recover the previous top of stack by incrementing the stack pointer without modifying the contents of the stack MUL, ADD, SUB, INC Arithmetic operations BNDCK, NILCK, NILCKL Boundary and pointer check instructions
"
"
Statistics For "Memory Components" Partition Compiler VlsiCheck? Group % Sum Group % Sum Mem1 19.18 19.16 Meml 10.94 10.94 Mem2 16.78 35.94 Mem2 24.81 35.75
Statistics For "Instruction Length" Partition Compiler VlsiCheck? Group % Sum Group % Sum Length1 55.22 55.22 Length1 56.72 56.72 Length2 38.64 93.86 Length2 41.66 98.38 Length3 6.14 100.0 Length3 1.62 100.0 Average Length 1.51 1.45
"
there's more data in that paper that i didn't bother to copy to here
" Statistics about Control Flow Change
"
" Performance effect of various levels of optimization measurements from Chow[1983] for 12 small FORTRAN and PASCAL programs
Optimizations performed Percent faster Procedure integration only 10% Local optimizations only 5% Local optimizations + register allocations 26% Global and local optimizations 14% Local and global optimizations + register allocation 63% Local and global optimizations + procedure integration + register allocation 81%
"
Addressing mode usage frequencies:
tex:
displacement: 32 immediate: 43 register deferred: 24 scaled: 16 memory indirect: 1
spice:
displacement: 55 immediate: 17 register deferred: 3 scaled: 16 memory indirect: 6
gcc:
displacement: 40 immediate: 39 register deferred: 11 scaled: 5 memory indirect: 1
immediate size: 50% to 60% fit within 8 bits, 75% to 80% fit within 16 bits
" Linux C library on x86:
Instruction usage breakdown (by popularity): 42.4% mov instructions 5.0% lea instructions 4.9% cmp instructions 4.7% call instructions 4.5% je instructions 4.4% add instructions 4.3% test instructions 4.3% nop instructions 3.7% jmp instructions 2.9% jne instructions 2.9% pop instructions 2.6% sub instructions 2.2% push instructions 1.4% movzx instructions 1.3% ret instructions ...
This makes a little more sense broken into categories:
Load and store: about 50% total 42.4% mov instructions 2.9% pop instructions 2.2% push instructions 1.4% movzx instructions 0.3% xchg instructions 0.2% movsx instructions
Branch: about 25% total 4.9% cmp instructions 4.7% call instructions 4.5% je instructions 4.3% test instructions 3.7% jmp instructions 2.9% jne instructions 1.3% ret instructions 0.4% jle instructions 0.4% ja instructions 0.4% jae instructions 0.3% jbe instructions 0.3% js instructions
Arithmetic: about 15% total 5.0% lea instructions (uses address calculation arithmetic) 4.4% add instructions 2.6% sub instructions 1.0% and instructions 0.5% or instructions 0.3% shl instructions 0.3% shr instructions 0.2% sar instructions 0.1% imul instructions
So for this piece of code, the most numerically common instructions on x86 are actually just memory loads and stores (mov, push, or pop), followed by branches, and finally arithmetic--this low arithmetic density was a surprise to me! You can get a little more detail by looking at what stuff occurs in each instruction:
Registers used: 30.9% "eax" lines (eax is the return result register, and general scratch) 5.7% "ebx" lines (this register is only used for accessing globals inside DLL code) 10.3% "ecx" lines 15.5% "edx" lines 11.7% "esp" lines (note that "push" and "pop" implicitly change esp, so this should be about 5% higher) 25.9% "ebp" lines (the bread-and-butter stack access base register) 12.0% "esi" lines 8.6% "edi" lines
x86 does a good job of optimizing access to the eax register--many instructions have special shorter eax-only versions. But it should clearly be doing the same thing for ebp, and it doesn't have any special instructions for ebp-relative access.
Features used: 66.0% "0x" lines (immediate-mode constants) 69.6% "," lines (two-operand instructions) 36.7% "+" lines (address calculated as sum) 1.2% "*" lines (address calculated with scaled displacement) 48.1% "\[" lines (explicit memory accesses) 2.8% "BYTE PTR" lines (char-sized memory access) 0.4% "WORD PTR" lines (short-sized memory access) 40.7% "DWORD PTR" lines (int or float-sized memory) 0.1% "QWORD PTR" lines (double-sized memory)
So the "typical" x86 instruction would be an int-sized load or store between a register, often eax, and a memory location, often something on the stack referenced by ebp with an immediate-mode offset. Something like 50% of instructions are indeed of this form! "
this is forth, not assembly:
http://users.ece.cmu.edu/~koopman/stack_computers/sec6_3.html
Dynamic instruction frequencies
NAMES FRAC LIFE MATH COMPILE AVE CALL 11.16% 12.73% 12.59% 12.36% 12.21% EXIT 11.07% 12.72% 12.55% 10.60% 11.74% VARIABLE 7.63% 10.30% 2.26% 1.65% 5.46% @ 7.49% 2.05% 0.96% 11.09% 5.40% 0BRANCH 3.39% 6.38% 3.23% 6.11% 4.78% LIT 3.94% 5.22% 4.92% 4.09% 4.54% + 3.41% 10.45% 0.60% 2.26% 4.18% SWAP 4.43% 2.99% 7.00% 1.17% 3.90% R> 2.05% 0.00% 11.28% 2.23% 3.89% >R 2.05% 0.00% 11.28% 2.16% 3.87%
where CALL is subroutine call, EXIT is exit at the end of a subroutine, VARIABLE is presumably a variable reference, @ is a load of a location in memory, 0BRANCH is a branch if the value is 0, LIT is an integer constant (push constant onto stack), + is addition, SWAP is swap, R> is pop, i don't know what >R is.
Table B.8: Executed Instruction Counts
(i'll only list the entries for the top instructions, in terms of C/I, the fraction out of total instructions for at least one of the two tasks listed, Ext. and VM):
Ext VMLIT .127 .158 + .103 .077 >A .126 .125 2/ 0 .126 @A .064 .082 CALL .064 .050 RET .064 .075 @A+ .064 .008 XOR .064 .021 A> .060 .009 FOLDS .042 .074
(FOLDS is something about "instructions...executed concurrently (’FOLDS’) with a PC@.")
-- http://www.eecg.utoronto.ca/~laforest/Second-Generation_Stack_Computer_Architecture.pdf
B.2.4 Instruction Types
instruction class, instructions: Ext frequency, VM frequency
Stack Manipulation: DUP, DROP, OVER, >R, R>, >A, A> 0.292, 0.233 Arithmetic & Logic: XOR, AND, NOT, 2*, 2/, +, +* 0.169 , 0.277 Fetches: PC@, LIT 0.168, 0.180 Load/Store: @A, @A+, !A, !A+, @R+, !R+ 0.156 , 0.138 Subroutine: CALL, RET, JMP 0.150, 0.152 Conditionals: JMP+, JMP0 0.061, 0.011 Conditionals (Taken): JMP+ TAKEN, JMP0 TAKEN 0.005, 0.010 NOP/UND: NOP, UND[0-3] 0, 0
-- http://www.eecg.utoronto.ca/~laforest/Second-Generation_Stack_Computer_Architecture.pdf
" Table 9.1: Counts from the BCPL self compilation test
Operation: Executions Static count
" -- ([2] page 157, PDF page 164)
---
http://pepijndevos.nl/2016/08/24/x86-instruction-distribution.html
top ones by count:
RISC-V RVC most frequent/compressed static instructions, from most frequent to least, from Table 14.7 in section 14.8 of [3], page 93, PDF page 103:
C.MV C.LWSP C.LDSP C.SWSP C.SDSP C.LI C.ADDI C.ADD C.LW C.LD C.J C.SW C.JR C.BEQZ C.SLLI C.ADDI16SP C.SRLI C.BNEZ C.SD C.ADDIW C.JAL C.ADDI4SPN C.LUI C.SRAI C.ANDI C.FLD C.FLDSP C.FSDSP C.SUB C.AND C.FSD C.OR C.JALR C.ADDW C.EBREAK C.FLW C.XOR C.SUBW C.FLWSP C.FSW C.FSWSP
RISC-V RVC most frequent dynamic instructions, from most frequent to least, from Table 5.8 in Chapter 5 of Design of the RISC-V Instruction Set Architecture, page 77, PDF page 90:
C.ADDI C.LW C.MV C.BNEZ C.SW C.LD C.SWSP C.LWSP C.LI C.ADD C.SRLI C.JR C.FLD C.SDSP C.J C.LDSP C.ANDI C.ADDIW C.SLLI C.SD C.BEQZ C.AND C.SRAI C.JAL C.ADDI4SPN C.FLDSP C.ADDI16SP C.FSD C.FSDSP C.ADDW C.XOR C.OR C.SUB C.LUI C.JALR C.SUBW C.EBREAK C.FLW C.FLWSP C.FSW C.FSWSP
Note that "Five RVC instructions expand to ADDI alone, reflecting its frequent idiomatic usage: increment (C.ADDI), increment stack pointer (C.ADDI16SP), generate stack-relative address (C.ADDI4SPN), load immediate (C.LI), and C.NOP".
Twenty most common RV64IMAFD instructions, statically and dynamically, in SPEC CPU2006, from Table 5.1 in Chapter 5 of Design of the RISC-V Instruction Set Architecture, page 56, PDF page 59:
static:
ADDI LD SD JAL ADD LW LUI FLD BEQ SLLI SW ADDIW BNE JALR FSD BGE FMUL.D FMADD.D BLT ADDW
dynamic:
ADDI LD FLD ADD LW SD BNE SLLI FMADD.D BEQ ADDIW FSD FMUL.D LUI SW JAL BLT ADDW FSUB.D BGE
"The most common instruction, ADDI, accounts for almost one-quarter of instructions statically and one-seventh dynamically."
Note that "ADDI’s outsized popularity is due not only to its frequent use in updating induction variables but also to its two idiomatic uses: synthesizing constants and copying registers...the degenerate forms of several RISC-V instructions express common idioms. For example, the ubiquitous ADDI instruction is used to synthesize small constants when its source register is x0, or to copy a register when its immediate is 0.".
Dynamic profiling of the most common bytecodes may be found in Table 5, pdf page 5 of [4].
toread:
http://aceshardware.freeforums.org/most-admired-cpu-in-history-t285.html http://people.cs.clemson.edu/~mark/admired_designs.html http://booksite.mkp.com/9780123838728/references/appendix_k.pdf http://www.herrera.unt.edu.ar/arqcom/Descargas/webext3.pdf http://ubuntuforums.org/showthread.php?t=1070157 http://www.assemblergames.com/forums/showthread.php?20561-Best-Worst-Assembly-Language-Instruction-Set http://www.softpanorama.org/History/cpu_history.shtml
indirect-indexed (take an address, retrieve the value there, add an offset, the result is your effective address) is more common than indexed-indirect (take an address, add an offset, retrieve the value there, that's your effective address). ([5] vs [6])
High-Performance Extendable Instruction Set Computing
http://researchbank.rmit.edu.au/eserv/rmit:2517/n2001000381.pdf discusses various profiling results. Among their conclusions:
"
" load/store instructions that reference the Stack Pointer and the Index Register tend to exhibit very different operand lengths. For Stack Pointer use, the offset needs to be more than 5 bits, while the majority (77%) of the Index Register load/store operations can utilize a 3-bit operand "
---
http://www2.informatik.uni-stuttgart.de/iste/ps/AdaBasis/pal/sei/dvk/risc.ps
RISC vs. CISC from the perspective of compiler/instruction set interaction, Daniel V. Klein.
(i rounded all numbers; i rounded .5 down)
" This paper compares the utilization of a number of different computer instruction sets by a collection of compilers. Wherever possible, several compilers were used for each architecture. This paper demonstrates that CISC instruction sets are underutilized by compilers, while RISC instruction sets are nearly completely utilized..
3.1 Analysis of the MIPS R2000 C Compiler
Table 1 - R2000 Instruction Use ((by instruction class)) ((static frequency)) ((shifts are 'arithmetic' but bitwise and or xor are 'logical')) ((benchmarks use integers only; floating point instructions are not included here))
...In those cases where no suitable instruction can be moved into the delay state, a nop instruction is used. This accounts for the high precentage of nop instructions...
...the compiler user 84% of the instruction set, and would indicate that the compiler and instruction set are well matched..Of the 8 instructions which the MIPS compiler does not generate, 3 are associated with operating system functions, another 3 are used only when arithmetic overflow checking is necessary (which C ((the language of the benchmarks)) does not require, but other languages do), and yet another is used only when a branch target is farther from the source than any of our tests allowed. If these are eliminated from our count, the R2000 C compiler is able to use all but one operation of the instruction set!...Of the 51 instructions on the R2000...
Table 3 - R2000 Addressing Mode Use
Looking at the addressing modes... all of them are used...with a reasonable frequency. Although absolute addressing is infrequently used, it is essential for accessing global variables (and its function cannot be easily duplicated by any combination of any other addressing mode).
3.2 Analysis of Motorola 88100 C Compilers
Table 4 - 88100 Instruction Use
Green Hills compiler:
Gnu compiler:
...For this processor, the number of move instructions is somewhat low, and the logical instructions are rather high. One reason for this is that there is no "move" instruction... this function is assumed by an 'or' with the zero register...If the or instructions used for this purpose...are counted as load instructions, the ratio of Move : Compute : Control ... becomes 52 : 16 : 31 for the Green Hills compiler and 54 : 12 : 34 for the GNU compiler, figures which are much closer to the norm we will see thorughout this paper. ...Unlike the R2000 and the SPARC, the 88100 does not use nop instructions to fill in delay slots...this accounts for the lower fraction of control operations...
...The Green Hills compiler used 38 of the integer instructions..As with the R2000, some of the never used instructions are designed for operating system use, or are used for array bounds checking. If these instructions are eliminated from our count, the percentage used...70% for the Green Hills compiler (69% for the Gnu compiler).
Table 6 - 88100 Addressing Mode Use
...The Condition and Bit Field modes are really just mnemonic devices for specifying single bits or collections of bits, and are another form of Immediate operand. They are included only for completeness, but should be counted as immediate operands.
The Green Hills compiler des not use Register Indirect Index mode. One reason for this is that when it needs an index of zero, it uses Register Indirect Immediate mode with an immediate operand of 0. On the other hand, the Gnu compiler accomplishes this by using Register Indirect Index with the zero register. These are essentially equivalent when the index value is zero...
Green Hills compiler:
Gnu compiler:
The addressing modes on the 88100 almost all involve registers, and syntactically appear quite similar. The differentiation is found in the instruction to which the registers are applied. The three register indirect modes are only use with the load, store, and memory exchange instructions.
Again, we see that the modes used (and as we will see later, most frequently used by complex architectures) are immediate, register, absolute, and some form of register indirect. In the 88100, some instructions automatically use registers as a source of an indirect address, so Register mode is counted rather high. In truth, a large fraction of this mode cound be counted with Scaled mode (a special type of indirection which is explictly called out in the assembler).
3.3 Analysis of SPARC C Compilers
Sun compiler:
Gnu compiler:
A familiar pattern is seen in the SPARC pattern of instruction usage. For the Gnu compiler for this processor (as with both compilers for the 88100), the number of move instructions is somewhat low, and the compute instructions are rather high. One reason... is that there is no "load address" instruction on the SPARC. This function is broken up into two instructions: sethi, which loads the high 22 bits of the address, and an or instruction which loads the low bits of the address. If the or instructions used for this purpose (...9.5% of the total instruction count) ... are counted as load instructions, the ratio of Move : Compute : Control ... for the Gnu compiler becomes 47 : 10 : 43, which is much closer to the norm we have seen previously.
...
Table 9 - SPARC Addressing Mode Use
...One the SPARC, there are actually only 5 addressing modes. Register-1 is a special case of Register-2, where is zero register is used as the second register..Similarly, Indirect-1 is a special case of Indirect-2...
Sun:
Gnu:
With the SPARC, we see the same 4 basic modes being used with roughly the same frequency as the other two RISC architectures. The dual register mode - Indirect-2 - is used infrequently in a static count. This mode is very useful for stepping through arrays and structures, and we feel that this mode would be used extensively in a dynamic analysis.
As shall be shown in the subsequent analysis, the four addressing modes that are shared by the three RISC architectures are the same as those modes which are used most frquently by the CISC architectures we shall now examine.
...
4.1 Analysis of the VAX C Compilers
Berkeley compiler:
Tartan Labs compiler:
DEC (VMS) compiler:
...of the 210 integer instructions on the VAX, over 100 are never used by either of the three compilers, and another 33 (on the average) are used <0.05% of the time...between 65%-72%...why are these instructions present in the architecture?... One wonderful example is the ediv instruction, which calculates both quotient and remainder for an integer division...unfortunately, ((none of the compilers tested)) take advantage of this..and use this instruction only for calculating remainders (the division being performed by other means)..((in theory)) compilers should probably have some special case processing to recognize when both a quotient and remainder are being calculated, and use the ediv instructions...((but in fact none of them bother))
Table 12 - VAX addressing mode use
Berkeley compiler:
Tartan Labs compiler:
DEC (VMS) compiler:
...The usage of... Immediate, Literal, Relative, Register, and Displacement... comprises between 96.4% and 97.8% of all the addressing mode usage on the VAX!
...Many VAX instructions allow the programmer to specify three operands instead of two... many compilers go to great length to try to use this 3 operand mode, since it results in smaller and more efficient code. However, in spite of all this effort on the part of the compilers, the 3 operand mode is greatly underutilized:
Table 13 2 Operand vs. 3 Operand Addressing
Berkeley compiler:
Tartan Labs compiler:
DEC (VMS) compiler:
4.2 Analysis of MC68020 Compilers
Sun compiler:
Gnu compiler:
...of the 140 instructions, ... 71% is not used
Table 16 - 68020 Addressing Mode Use
Sun compiler:
Gnu compiler:
... the three modes which are used most frequently are (again): immediate, absolute, and register. Displacement mode and register indirect mode (the latter being a special case of the former..) fille the remainder of the main usage...
4.3 Analysis of 80386 C Compilers
Sun compiler:
Gnu compiler:
as with the other two CISC machines, the 80386 compilers are unable to effectively etilize the instruction set...op the 146 instructions..., 105 ... are never used... roughly 75%... is not used...
Table 19 - 80386 Addressing Mode Use ((only modes used by one of the compilers are listed))
Sun compiler:
Gnu compiler:
...predominant addressing modes used by the 80386 compilers are (yet again): immediate, register, absolute, and offset... these...account for 99%...
5. Comparing object code size
...30-65% increase in program size on the RISC architectures
6. What do the Results Tell Us?
...within each architecture...instruction...and address mode coverage...did not vary substantially...
...between architectures...the use of...move, compute, control...is also very similar
...(especially in the case of Ada and Pascal, which would almost certainly use the "bounds check" instructions - the chk and chk2 instructions on the 68020, the tbnd instruction of the 88100, and the bound instruction of the 80386 - to test the validity of array indices). "
---
https://home.gwu.edu/~mlancast/CS6461Reference/RISC/patterson85.RISComputers.pd.pdf
"Only two simple addressing modes, indexed and PC-relative, are provided"
Figure 7. The call-Return behavior of Programs "We have found that about eight windows hits the knee of the curve and that locality of nesting is found in programs written in C, Pascal, and Smalltalk.
---
https://www.computer.org/csdl/proceedings/afips/1983/5090/00/50900503.pdf
Analysis of the M6809 instruction set by Joel Boney
STATIC ANALYSIS OF THE M6809
TABLE I-Top 10 most frequently appearing M6809 opcodes
Total: 37.40%
TABLE II-Top 10 classes of M6809 instructions
Total: 66.69%
TABLE IV-M6809 static addressing mode usage
Table V-Static indexed addressing data
Average additional bytes for indexed = 1.17
DYNAMIC ANALYSIS OF THE M6809
Table VI-Union of the top ten classes (dynamic) showing % of executed instructions
Class Chess Editor Monitor Mopet M6839 Load 8-bit 19.20 11.87 10.10 8.04 8.76 Branch if equal 9.93 6.56 1.44 12.07 .59 Load 16-bit 7.81 8.80 10.41 7.35 2.05 Load eff. addr. 5.06 4.82 3.72 10.95 2.92 Store 8-bit 4.85 5.01 1.49 2.19 4.22 Store 16-bit 4.23 3.58 3.29 4.26 1.88 Branch if not = 4.21 9.32 2.68 6.99 3.80 Bit test 3.49 0 .59 .32 .01 Branch if minus 3.22 .06 .06 .04 .03 Increment 2.89 .46 1.48 .32 .92 Compare 8-bit 2.74 13.18 6.56 8.68 9.35 Jump to subr. 2.64 6.45 3.29 2.60 .05 Push 2.19 3.37 4.20 1.45 1.55 Return from subr. 1.97 3.04 4.90 2.48 2.30 Pull 1.84 2.49 3.90 .77 .95 Compare 16-bit 1.40 5.62 1.39 11.63 1.25 Decrement 1.21 0 .08 .44 4.97 Branch always .95 6.47 .64 4.64 6.20 Branch less than .19 .09 0 .01 5.62 Branch higher/same .11 .27 .30 3.10 1.68 Branch lower .07 .41 3.56 1.68 .27 Long branch subr. .04 .73 5.15 1.78 1.15 Rotate left .02 .08 .06 .09 10.96 Rotate right 0 0 3.77 0 10.63 Other 19.74 7.32 26.94 8.12 16.01
Table VII-Union of the top three largest classes (dynamic)
Class Chess Editor Monitor Mopet M6839 Load 27.01 20.67 20.51 15.40 10.81 Cond. branch 21.81 21.12 9.24 24.76 15.86 Store 9.08 8.59 4.78 6.46 6.10 Cmpltest 6.07 18.97 8.32 22.14 12.63 Call 3.18 7.18 10.66 5.54 2.97 Shifts 0.33 0.16 9.50 0.45 23.33
Table VIII-Dynamic addressing mode usage Mode Chess Editor Monitor Mopet M6839 Indexed 40.79 33.74 29.76 31.05 41.46 Short relative 22.23 27.48 12.09 30.46 23.78 Immediate 14.23 18.47 15.46 12.12 11.49 Inherent 7.21 9.77 23.19 5.77 6.73 Extended 3.90 8.93 3.29 2.90 0.24 Direct 8.33 0.00 0.00 14.29 0.00 Long relative 1.08 0.88 5.18 1.98 1.27 Accumulator a 1.51 0.09 10.33 0.84 9.07 Accumulator b 0.72 0.64 0.70 0.59 5.95 Indirect 0.69 0.00 0.00 0.04 0.15
Table IX-Dynamic indexed addressing statistics Addr Mode Chess Editor Monitor Mopet M6839 No offset 17.03 23.34 7.47 45.95 10.96 5-bit offset 62.00 39.80 37.82 37.35 62.32 8-bit offset 2.30 0.01 0.00 0.22 2.55 16-bit offset 6.77 0.01 0.00 1.21 0.00 8-bit off. on PC 0.00 0.06 11.21 0.02 0.14 16-bit off. on PC 0.00 0.02 0.00 0.23 1.53 Auto incr. by 1 2.70 34.76 21.26 6.78 1.68 Auto incr. by 2 1.57 1.46 0.00 3.06 0.06 Auto decr. by 1 1.15 0.02 0.05 4.26 0.19 Auto decr. by 2 1.60 0.00 0.00 0.00 0.38 a acc. offset 3.34 0.08 11.06 0.37 3.91 b acc. offset 0.35 0.00 0.00 0.26 15.93 d acc. offset 0.42 0.43 11.13 0.27 0.35 Extended indirect 0.77 0.00 0.00 0.00 0.00
SUMMARY
Three new M6809 instructions headed up the list of the most frequently appearing single opcodes. They were long branch to subroutine, load effective address, and push on the S stack.
The rest of the top 20 was composed of loads, stores, branches, compares, subroutine calls, and subroutine returns.
In larger classes of instructions, the following statistics were the approximate static values for the top five classes:
...
The static addressing-mode data indicate that the most common addressing mode is indexed (30%), followed by rel-ative (24%), and by immediate (20%). The number of direct and extended instructions combined was only 10%. Indirect was practically never used. In the static indexed addressing data we find that 5-bit and no-offset indexed account for 66% of all indexed instructions. Including the 8-bit, 16-bit, 8-bit program counter relative mode and the 16-bit program counter relative mode, we find 86% of the indexed instructions are constant offset or have no offset. . This indicates to future architects that having several effi-cient, simple offset indexed forms is beneficial. The M6809 has six such forms as compared to the M6800's one.The average number of bytes added for each indexed in-struction is 1.17 bytes.
...in the dynamic data...
By classes, the conditional branches all combined to form the second most-executed group, second only to the loads and stores. The other large classes were compare and test, the calls, and the shifts. In dynamic execution the indexed addressing mode ac-counts for approximately 35% of all addressing modes. Short relative is about 25%, and immediate is 15%. Long relative addressing usage is fairly low. Indirect is the big loser again. In indexed addressing, the offset varieties accounted for 72%. This is down from the static data, but is stilljmpressive. Auto increment and the accumulator offsets make up most of the rest of the indexed data. The dynamic data reinforce the conclusions from the static analysis that a good measure of the overall efficiency of an architecture is best found in the loads, stores, conditional branches, subroutine calls, and addressing modes. This coin-cides with the modern view that computers spend most of their time in moving data around and making decisions based on the data rather than in number crunching. "
---
https://pdfs.semanticscholar.org/5a4f/81f835ac6a5381cec90637f66dabe9ac5188.pdf
Relating Static and Dynamic Machine Code Measurements Jack W. Davidson, MEMBER, IEEE , John R. Rabung, and David B. Whalley, MEMBER, IEEE
" Table V. Prediction Intervals and Results for PA-RISC
Measurement Static Dynamic
iiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii Instructions iiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii call 6.38 2.41 compare 7.97 10.50 cond jmp 7.95 10.45 uncond jmp (B) 4.31 2.03 return (B) 1.17 1.57 move 49.24 49.96 int add 27.45 25.55 int subtract 0.62 2.33 float add 0.09 0.24 float subtract 0.08 0.04 float multiply 0.10 0.15 float divide 0.05 0.06 shift 1.31 4.51 bitwise and 0.92 0.60 bitwise or 0.27 0.06
iiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii Address Modes iiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii register 58.50 62.40 immediate 21.33 18.77 reg-deferred 4.24 5.94 displacement 10.67 6.87 iiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii
...
Table VI. Static and Dynamic Percentages on the Motorola 68020
Measurement Static Dynamic
iiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii Instructions iiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii
call 8.14 2.31 compare 9.28 12.03 cond jmp 10.93 13.86 uncond jmp 5.97 2.54 return 1.61 2.06 move 43.79 42.90 int add 3.13 7.49 int subtract 1.57 2.10 int multiply 0.50 1.84 int divide 0.43 0.24 float add 0.12 0.32 float subtract 0.09 0.04 float multiply 0.14 0.20 float divide 0.07 0.09 shift 0.44 1.48 bitwise and 1.94 2.12 bitwise or 0.37 0.08
iiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii Address Modes iiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiiii register 41.42 50.81 immediate 17.22 14.14 reg-deferred 2.49 3.27 displacement 6.85 7.24 direct 14.21 7.14
...
Studies of instruction usage of specific architectures have been performed. MacGregor? and Ruben- stein measured the dynamic usage of instructions of a 68000-based machine [13]. The top four categories by dynamic percentage were:
These categories account for over 80% of all instruction executions. Inspection of Table VI reveals similar rankings. The top groups by dynamic percentage were:
Again, the top four instruction categories account for over 80% of all instruction executions
...
For this machine, the dynamic percentage of call instructions is less than 1 ⁄ 3 of the static percentage...Functions are often written to abstract some common set of operations that are used repeatedly in a program. Consequently, in computing the static percentage of call instructions, the instructions comprising the body are only counted once. When computing the dynamic percentage, however, on each call the instructions in the function that are executed are counted. This greatly increases the total number of instructions executed while only slightly increasing the number of call instructions executed. The result is a significantly lower dynamic percentage of call instructions. This effect is further magnified because statically 16.9% of the functions in the test suite used for this study were leaves (functions that make no calls to other functions), while a full 55 percent of the executed functions were leaf functions...
...
The difference in the measurements for conditional and unconditional jumps reveals an interesting behavior. For all machines, the dynamic percentage of conditional jumps was higher than the static percentage, while for unconditional jumps the opposite was true. For the 68020, the dynamic percentage of unconditional jumps was less than 1 ⁄ 2 the static percentage. Detailed inspection of the code generated for the test suite programs showed that the dominant factor that raised the dynamic percentage of conditional jumps was loops. The code for the termination condition of a loop generally involves a conditional jump. This jump is executed each time through the loop. Statically on the 68020, the conditional jumps associ- ated with the termination condition of loops were 14.6% of the total number of conditional jumps. The dynamic measurements indicated that these conditional jumps accounted for 30.0% of the total. Conse- quently, it is not surprising that the dynamic percentage is higher than the static. With respect to unconditional jumps, there were two situations that seemed to account for the differ- ence in the static and dynamic percentages. In switch statements, each case within the switch usually ends with an unconditional jump instruction to the end of the switch statement. With a switch state- ment that has many cases, there will be many instances of unconditional jumps, but when the switch is executed only one case is selected and therefore only one unconditional branch is executed. Correspondingly, with if-then-else constructs, a conditional jump is generated to evaluate the if portion of the statement, while an unconditional jump is generated at the end of the then block. At run-time, if the if-then-else construct is executed, the conditional jump is always executed (the branch may or may not be taken), while the unconditional jump may not be executed. "
---
"...the static measurements for the 68020 indicated that instructions in leaf functions comprised 7.0% of the total number of instructions, while dynamic measurements showed they accounted for 30.3%." [7]
---
"Figure 12 also indicates that a two operand instruction format (where the value in one operand register would be replaced with the result value) would only be used in 12.79% of data processing instructions, and the more general three operand format is therefore useful in over 87% of Data Processing instructions and completely justified. " [8]
note that this contrasts with Table 13 of [9] on the VAX, which found that there, the three operand forms were rarely used.
---
https://ir.canterbury.ac.nz/bitstream/handle/10092/9405/jaggar_thesis.pdf
all numbers rounded; .5 rounded down. I believe the following frequencies/statistics are all dynamic, not static, but i'm not 100% sure.
" Figure 10: Relative Instruction Usage
...
The twelve available registers are usually enough to hold all live variables and temporary values, but in about 3% of occasions three more registers could be effectively utilised by the register allocator (3% of all instructions were used to spill and reload registers over short instruction sequences), and as many as eight more could sometimes be utilised to hold values.
...
The bitwise operators seem of little use inC code, but the figure is rather misleading. The programs "sum", "unpack", "od" and "compress" are responsible for almost all bitwise operations in the twenty-two programs (bit operations account for about 8% of the instructions in these programs), so their inclusion in the instruction set is necessary. Furthermore these instructions may be more prominent in programming languages like Pascal where they would be used for operations on sets and arrays of boolean values.
...
Figure 11: Data Processing Instructions (percent of all instructions)
...
Figure 12: Data Processing Operands
(note: i don't think these categories are exclusive; eg large immediates is a subset of immediates, i believe)
...
On average the barrel shifter increases the execution speed of programs by 2.5%, with a maximum of 14% for the program "sum".
...
Figure 13: Data Processing Immediate Operands
...
Altering the immediate field to hold a simple twelve bit constant would degrade the performance of C code by 2%, mainly because the current rotated immediate operands are useful for loading the addresses of global variables and data structures
...
Figure 14: Conditional Non-Branch Instructions ...as percentages of all instructions...
TOTAL: 11
...
Figure 14 shows the distribution of conditional non Branch instructions (as percentages of all instructions). Nearly 11% of instructions were conditional, and the condition failed in 58% of these instructions. The average number of conditional instruction in sequence is 1.4. If conditional instructions are not utilised, the code size increases by 8% because of the extra branch instructions required and execution time increases by 25% (because taken branches are more frequent and take more cycles than non-taken branches). On top of this saving a further 2% of instructions were conditional procedure calls (one quarter of all procedure calls), another feature of the ARM architecture. If the four bits used to hold the condition in each instruction are not more useful for some other feature (which is unlikely considering the large performance increase) then conditional execution of all instructions is a useful feature.
...
Forward branches (used for IF statements) are nearly 4 time more frequent than backward branches (used for looping constructs). On average 2.9 instructions were guarded by an IF branch instruction, which is rather high because nearly all branches around one or two instructions are removed and replaced with a conditional instruction sequence (not allshortbranches are removed because some are required in complex boolean expressions to branch around a second compare and branch). On average just thirty two instructions were executed between procedure calls, underlining the need for efficient procedure entry and exit mechanisms.
Almost all conditional branch instructions branch around fewer than one thousand instructions, and the proportion of conditional branch instructions that are preceded by compare instructions is over 95%. If a single cycle compare and branch instruction can be implemented a 10% performance increase could be made due to the vast reduction in the number of compare instructions used before branches. The feasibility of such an instruction is discussed later.
Nearly 70% of subroutine branches were made to Operating System libraries, underlining the importance of register allocation at link time. Modern UNIX systems are tending towards shared Operating System libraries, where many processes share the same library code, so this code dictates the register usage in programs which call these libraries.
...
Figure 15: Addressing Modes
...
The scaled index and auto increment and auto decrement addressing modes are well utilised by the compiler, and together provide a 7% performance increase by saving shift instructions and addition/subtraction instructions (or both).
The twelve bit immediate offset field caters for all immediate offsets, an eight bit rotated immediate operand (as in the Data Processing instructions) would not be beneficial.
Load instructions are responsible for 73% of single register memory access instructions, stores are the remaining 27%. This distribution is the same across all addressing modes.
On average 6.3 registers are saved by each multiple transfer instruction, making them responsible for over fifty percent of the total memory traffic. Most of these instructions (97%) use the decrement-before (DB) addressing mode to access the procedure call stack, the rest replace sequential single register memory accesses. Fifty-three percent of multiple register memory accesses were loads. These instructions are responsible for a 34% performance increase.
...
...
Figure 16: Cache Strategies % of main memory bandwidth used ((main memory bandwidth decrease, i think? ))
...As can be seen a write buffer provides the most significant decrease, yielding nearly 5%.
...
Together the unusual architectural features of ARM increase performance by 73.5% compared to a more traditional RISC architecture like MIPS. The most significant performance losses are caused by the lack of delayed loads, the lack of delayed branches and the high proportion of branch instructions that are preceded by compare instructions.
...
The absence of delayed load instructions is a result of the strict von Neumann memory system, which cannot deliver a new instruction (to keep the pipeline full) and a word of data (loaded by a load instruction) in the same cycle, causing a load delay of one cycle. This delay is also incurred by the store instructions. The complex addressing modes utilise this wasted cycle to provide a 7% performance increase. The multiple register transfer instructions ensure consecutive load or store instructions to consecutive memory addresses only incur one pipeline delay (rather than one for each word transferred), to provide a 34% performance increase.
...
Implementing delayed loads increased performance by 14.8%. The multiple register transfer instructions are of little use in this modified architecture, providing less than 1% more performance, and could be removed. The multiple register transfer instructions are the main reason that the architecture has just sixteen registers, where thirty-two would be more useful. Unfortunately to encode 3 five bit register numbers in a data processing instruction would require the removal of the condition field, which would imply a 25% performance loss, outweighing the 3% performance increase the extra registers could be expected to provide.
...
Adding delayed branches to the architecture increased performance by 12.3%, and reduced the performance increase of conditional instructions to about 4% (because the delay slots after branches around one or two instructions are very easy to fill), which makes their removal in favour of thirty-two registers much more controversial.
...
Adding a general purpose, single cycle compare and branch instruction to the ARM architecture would increase performance by 10.34%, because most (95%) of branch instructions are preceded by a compare instruction. It is not possible to fit all the information necessary into 32 bits for an instruction to replace all compare and branch instructions, but using one of the undefined instruction formats it is possible to add an instruction with two registers or a register and a four bit integer, a (second) four bit compare condition field, and an 1024 instruction offset (1024 instructions could be branched both forwards and backwards). Adding this less general instruction improved performance 9.84%. A problem with this instruction is the extra hardware required for a second subtract unit to calculate the compare result (as the shifter and the main ALU would be required for the branch target calculation).
It is possible to restrict the type of branch to just equal and not-equal, which do not require a full carry propagating subtraction unit for the comparison, and the branch offset can be increased to 8192 instructions. This option increased performance by 8. 72%, and does require as much extra hardware, changes to the instruction field extraction unit, to remove the branch offset and send it directly to the ALU, and to the ALU buses to support the two calculations at once...The assembly mnemonic is also rather strange due to the two condition fields (one for the entire instruction, the other for the branch), but this instruction is probably best produced automatically by the assembler anyway, as only at this stage is the magnitude of a branch offset known to decide if it can be utilised. This feature was probably not included in the ARM architecture because it does not follow the RISC discipline, as there would be two ways to perform some tasks, complicating the architecture.
...
The compact encoding of ARM's instruction set increases cache performance by a large extent. The lack of many branch instructions, the shift operations that are combined with data processing instructions, the complex addressing modes, and the multiple memory transfer instructions that replace several single register transfers all contribute to a 45% decrease in the instruction memory bandwidth used (and hence increase the effectiveness of the cache) compared to more typical RISC architectures, justifying their inclusion in the architecture, even if delayed branches and/or delayed loads had been implemented. Programs with a high number of procedure calls benefit more (up to 55%) from the compact instructions (due to the increase in the proportion of multiple register transfer instructions used), making this feature more efficient at lowering the memory bandwidth used by the processor than the SPARC architecture's register windows [Morr88]. "
---
John L. Hennessy; David A. Patterson. Computer Architecture: A Quantitative Approach. p. 104. "The C54x has 17 data addressing modes, not counting register access, but the four found in MIPS account for 70% of the modes. Autoincrement and autodecrement, found in some RISC architectures, account for another 25% of the usage. This data was collected form a measurement of static instructions for the C-callable library of 54 DSP routines coded in assembly language."
from [10]
---
" oldandtired on May 1, 2017 [-]
IEEE Spectrum in the early 80's had an article on minimal instruction sets. The author made a salient point that 7 instructions did most of the heavy lifting, another 7 did the most of the rest required. He did highlight that one mistake made with instruction sets was not separating the addressing modes from the instruction itself.
There have also been various projects looking at the micro-instruction based machines and noting that extremely complex instruction sets could be designed so that the actual requirements of a programmer or project be placed in microcode. One example was an instruction to search a tree structure for a required value (as a single machine instruction).
Not that I can do anything about it, my conclusion over nearly 4 decades is that we have failed to take advantage of the increasingly denser silicon to make higher level machines, in particular machines that recognise the difference an instruction and a data element.
We can write very high level software languages but all have to be run on extremely low level hardware. Too much commodity and not enough variability.
oldandtired on May 2, 2017 [-]
I have managed to rummage around and found the article. It was actually in IEEE Micro May 1982, "A Unique Microprocessor Instruction Set" Dennis A Fairclough.
The article looked at the statistical usage of instructions and placed them into 8 broad groups, Data Movement, Program Modifying, Arithmetic, Compare, Logical, Shift, Bit and I/O & Misc groups.
The result of the analysis was as follows:
For groups data movement and Program Modifying, 1 Instruction - MOVE [Cummulative usage 75%]
For group Arithmetic, 4 Instructions - ADD, SUB, MULT, DIV [Cumulative usage 87.5%]
For group Compare, 1 previous Instruction - SUB [Cumulative usage 93.75%]
For group Logical, 3 Instructions - AND, OR, XOR [Cumulative usage 96.88%]
For group Shift, 1 Instruction - SHIFT [Cumulative usage 98.44%]
For group Bit, 1 Instruction - MOVEB [Cumulative usage 99.22%]
For group I/O & Misc, depends on whether i/o is memory mapped or otherwise, so either 0 or 1 Instruction.
Some possible extended instructions included INC, DEC, I/DBRC and MOVEM.
The address fields (and in some cases additional flags) determine source and destination, etc.
So, in relation to the VLIW question, the instruction length is determined more by the addressing modes allowed than by the specific instruction itself (which is encoded in say 4 bits). "
-- [11]
---
not quite the same thing, but here are admired machine architectures: https://people.cs.clemson.edu/~mark/admired_designs.html https://news.ycombinator.com/item?id=21988096
---
Design of the RISC-V Instruction Set Architecture by Andrew Waterman
see Figure 5.2: Cumulative frequency of integer register usage in the SPEC CPU2006 benchmarksuite, sorted in descending order of frequency
---
The Need for Large Register Files in Integer Codes
---
Code Density Concerns for New Architectures hand-optimizes some assembly code for density and then compares its size on different architectures. They find that the gain from hand-optimization is about a factor of 2, whereas the gain from moving to a CISC architecture from a RISC one is about 25%. They did a simple correlation of architectural features to code size (not a multivariate correlation, apparently), and got the following correlations:
Correlation Architectural Parameter 0.9381 Minimum possible instruction length 0.9116 Number of integer registers 0.7823 Virtual address of first instruction 0.6607 Architecture has a zero register 0.6159 Bit-width 0.4982 Number of operands in each instruction 0.3129 Year the architecture was introduced -0.0021 Branch delay slot -0.0809 Machine is big-endian -0.2121 Auto-incrementing addressing scheme -0.2521 Hardware status flags (zero/overflow/etc.) -0.3653 Unaligned load/store available -0.3854 Hardware divide in ALU
So, the factors with a correlation over 1/3, in descending order of correlation magnitude, were:
(where 'better' means more dense; but in reality density is often a trade-off against speed, or against other things)
Note that since this was a simple, not a multivariant correlation, some of these factors could disappear if multivariate correlation were taken into account.
21 architectures were examined. Looking at rank orderings, in terms of total benchmark size (fig. 2; includes some platform-specific code, so does not strictly reflect code density), the 5 least dense were (from least dense to most) ia64 alpha parisc sparc mblaze mips m88k, and the 7 most dense were (from most dense to least) pdp-11 crisv32 avr32 z80 thumb i386 m68k. Figs. 3-6 show various parts of the code which are presumably less platform-specific; here x86 (i386) and x86_64 make a better showing (in fact, i386 comes in 1st in 3 categories, and 4th in the other one), and pdp-11 does much worse on some; crisv2 does well except when a hardware divide is called for; avr32 does well although slightly worse in the string concatenation code category (8th place; the paper says "machines with auto-increment addressing modes and dedicated string instructions perform better" with string concatenation); z80 does well except in LZSS decompression code (8th place); thumb is okay (2 10th places and an 8th place).
but see https://people.eecs.berkeley.edu/~krste/papers/EECS-2016-1.pdf, which says that x86 and x86_64 is not very dense (staticly, although it is dynamically): "As we show in Chapter 5, what could otherwise be a very dense instruction encoding is not at all: IA-32 is onlymarginally denser than the fixed-width 32-bit ARMv7 encoding, and x86-64 is quite a bitless dense than ARMv8. Despite all of these flaws, x86 typically encodes programs in fewer dynamic instruc-tions than RISC architectures, because the x86 instructions can encode multiple primitive operations. For example, the C expressionx[2] += 13might compile in MIPS to the three-instruction sequencelw r5, 8(r4); addiu r5, r5, 13; sw r5, 8(r4), but the single in-structionaddl 13, 8(eax)suffices in IA-32. This dynamic instruction density has some advantages: for example, it can reduce the instruction fetch energy cost. But it compli-cates implementations of all stripes. In this example, a regular pipeline would exhibit two structural hazards, since the instruction performs two memory accesses and two additions"
---
"Instructions express great spatial locality of register reference.RISC-V provisions anample register set to minimize register spills and facilitate register blocking, but evenso, most accesses are to a small number of registers. Figure 5.1 shows the staticfrequency of register reference in the SPEC CPU2006 benchmarks, sorted by registerclass. Three special registers—the zero registerx0, the link registerra, and the stackpointersp—collectively account for one-quarter of all static register references. Thefirst argument register a0 alone accounts for one-sixth of references" [12]
figure 5.1, Frequency of integer register usage in static code in the SPEC CPU2006 bench-mark suite, shows:
figure 5.3, Frequency of floating-point register usage in static code in the SPEC CPU2006benchmark suite, shows:
"Figure 5.2 renders the static and dynamic frequencies of register reference as a cu-mulative distribution function. Notably, just one-quarter of the registers account fortwo-thirds of both static and dynamic references" [13]
my note: 1/4 of 32 registers is 8
"Statically, floating-point register accesses exhibit a similar degree of locality (see Fig-ures 5.3 and 5.4), with the exception that there are no special-purpose registers toexploit. Dynamically, an even smaller number of registers dominates: the eight mostcommonly used registers account for three-quarters of accesses"
---
"Instructions tend to have few unique operands.Some instruction sets, such as the Intel80x86, provide only destructive forms of many operations: one of the source operandsis necessarily overwritten by the result. This ISA decision substantially increases in-struction count for some programs, and so RISC-V provides non-destructive forms ofall register-register instructions. Nevertheless, destructive arithmetic operations arecommon: 47% of static arithmetic instructions in SPEC CPU2006 share at least onesource operand with the destination register.Additionally, the degenerate forms of several RISC-V instructions express commonidioms. For example, the ubiquitous ADDI instruction is used to synthesize smallconstants when its source register isx0, or to copy a register when its immediate is 0."
---
"Immediate operands and offsets tend to be small.Roughly half of immediate operandscan be represented in five bits (see Figure 5.5)." [15]
my note: the figure shows that this holds both staticly and dynamically.
my note: the figure shows that 8 bits would be over 2/3s, both staticly and dynamically.
---
"Figure 5.6 shows the distribution of branch and jump offsets. Statically, branch andjump offsets are often quite large; dynamically, however, almost 90% fit within eightbits, reflecting the dominance of relatively small loops." [16]
my note: figure 5.6 shows that staticly, 50% of offsets have a width of 9 bits or less, and dynamically, 50% of offsets have a width of 6 bits or less; I think this includes the extra bit for sign, but not sure
almost no offsets, either static or dynamic, have a width 3 bits or less. From 3 bits to 20 (the static max), the static data points are roughly linear, but the dynamic ones has a steep slope between 3 and 8 bits (8 bits/90%), after which the slope decreases dramatically.
---
"A small number of unique opcodes dominates.The vast majority of static instructionsin SPEC CPU2006 (74%) are integer loads, adds, stores, or branches. As Table 5.1indicates, the twenty most common RISC-V opcodes account for 91% of static in-structions and 76% of dynamic instructions. The most common instruction, ADDI,accounts for almost one-quarter of instructions statically and one-seventh dynamically
Table 5.1: Twenty most common RV64IMAFD instructions, statically and dynamically, inSPEC CPU2006. ADDI’s outsized popularity is due not only to its frequent use in updatinginduction variables but also to its two idiomatic uses: synthesizing constants and copyingregisters
(the list of instructions in Table 5.1 is already copied above, search this file for RV64IMAFD)
---
" Arguably the most important job of an instruction-set architect is deciding what featuresshould be left out. In defining RVC, the most difficult choice we made was whether toincludeload-multipleandstore-multipleinstructions, which load or store consecutive wordsin memory to or from a block of registers. Other compressed RISC ISAs, like microMIPS andThumb, have included these instructions, primarily to reduce callee-saved register spill andfill code at procedure entry and exit. By our measurements, these can result in considerablecode size savings: for example, the RVC Linux kernel text would become about 8% smallerwith the use of these instructions in function prologues and epilogues.
Yet, after careful consideration, we opted against including them in RVC. The main rea-son was that they would violate our design constraint that each RVC instruction expand intoa RISC-V instruction, thereby requiring compilers be RVC-aware and complicating proces-sor implementations. They are also likely to be implemented with low performance in somesuperscalar microarchitectures, which would prohibit the issue of other instructions dur-ing the multi-cycle execution of the load- or store-multiple. Further reducing performance,especially for statically scheduled microarchitectures, is the inability of the compiler to co-schedule prologue and epilogue code with other code in the body of the function. Finally,in machines with virtual memory, these instructions can trigger page faults in the middle oftheir execution, complicating the implementation of precise exceptions or requiring a newrestart mechanism.
The final nail in their coffin came with the realization that, when static code size mattersmore than runtime performance, we can obtain most of the benefit of load-multiple and store-multiple with a purely software technique. Since prologue and epilogue code is generally thesame between functions, modulo the number of registers saved or restored, we can factorout this code into shared prologue and epiloguemillicoderoutines11. These routines musthave an alternate calling convention, since the link register must be preserved during theirexecution. Fortunately, unlike ARM and MIPS, RISC-V’s jump-and-link instruction canwrite the return address to any integer register, rather than clobbering the ABI-designatedlink register. Other than that distinction, these millicode routines behave like ordinaryprocedures " [17]
---
" Table 5.3: RV32C and RV64C instruction listing
Instruction Format Base Instruction Meaning C.ADD CR add rd, rd, rs2 Add registers C.ADDI CI addi rd, rd, imm[5:0] Increment register C.ADDI16SP CI addi x2, x2, imm[9:4] Adjust stack pointer C.ADDI4SPNC IW addi rd', x2, imm[9:2] Compute address of stack variable C.ADDIW CI addiw rd, rd, imm[5:0] Increment 32-bit register (RV64) C.ADDW CR addw rd, rd, rs2 Add 32-bit registers (RV64) C.AND CS and rd', rd', rs2' Bitwise AND registers C.ANDI CI andi rd', rd', imm[5:0] Bitwise AND immediate C.BEQZ CB beq rs1', x0, offset[8:1] Branch if zero C.BNEZ CB bne rs1', x0, offset[8:1] Branch if nonzero C.EBREAK CR ebreak Breakpoint C.FLD CL fld rd', offset[7:3](rs1') Load double float C.FLDSP CI fld rd, offset[8:3](x2) Load double float, stack C.FLW CL flw rd', offset[6:2](rs1') Load single float (RV32) C.FLWSP CI flw rd, offset[7:2](x2) Load single float, stack (RV32) C.FSD CL fsd rs2', offset[7:3](rs1') Store double float C.FSDSP CSS fsd rs2, offset[8:3](x2) Store double float to stack C.FSW CL fsw rs2', offset[6:2](rs1') Store single float (RV32) C.FSWSP CSS fsw rs2, offset[7:2](x2) Store single float to stack (RV32) C.J CJ jal x0, offset[11:1] Jump C.JAL CJ jal x1, offset[11:1] Jump and link (RV32) C.JALR CR jalr x1, rs1, 0 Jump and link register C.JR CR jalr x0, rs1, 0 Jump register C.LD CL ld rd', offset[7:3](rs1') Load double-word (RV64) C.LDSP CI ld rd, offset[8:3](x2) Load double-word, stack (RV64) C.LI CI addi rd, x0, imm[5:0] Load immediate C.LUI CI lui rd, imm[17:12] Load upper immediate C.LW CL lw rd', offset[6:2](rs1') Load word C.LWSP CI lw rd, offset[7:2](x2) Load word, stack C.MV CR add rd, x0, rs2 Copy register C.OR CS or rd', rd', rs2' Bitwise OR registers C.SD CL sd rs2', offset[7:3](rs1') Store double-word (RV64) C.SDSP CSS sd rs2, offset[8:3](x2) Store double-word to stack (RV64) C.SLLI CI slli rd, rd, imm[5:0] Shift left, immediate C.SRAI CB srai rd', rd', imm[5:0] Arithmetic shift right, immediate C.SRLI CB srli rd', rd', imm[5:0] Logical shift right, immediate C.SUB CS sub rd', rd', rs2' Subtract registers C.SUBW CS subw rd', rd', rs2' Subtract 32-bit registers (RV64) C.SW CL sw rs2', offset[6:2](rs1') Store word C.SWSP CSS sw rs2, offset[7:2](x2) Store word to stack C.XOR CS xor rd', rd', rs2' Bitwise XOR registers "
-- [18]
here is the same table, resorted by product of rank in tables 5.7 and 5.8 of the same paper, "RVC instructions in order of typical static frequency" and "RVC instructions in order of typical dynamic frequency", with the ranks prepended (static_rank, dynamic_rank, static_rank*dynamic_rank):
" Ranks Instruction Format Base Instruction Meaning 01 03 3 C.MV CR add rd, x0, rs2 Copy register 07 01 7 C.ADDI CI addi rd, rd, imm[5:0] Increment register 02 08 16 C.LWSP CI lw rd, offset[7:2](x2) Load word, stack 09 02 18 C.LW CL lw rd', offset[6:2](rs1') Load word 04 07 28 C.SWSP CSS sw rs2, offset[7:2](x2) Store word to stack 03 16 48 C.LDSP CI ld rd, offset[8:3](x2) Load double-word, stack (RV64) 06 09 54 C.LI CI addi rd, x0, imm[5:0] Load immediate 10 06 60 C.LD CL ld rd', offset[7:3](rs1') Load double-word (RV64) 12 05 60 C.SW CL sw rs2', offset[6:2](rs1') Store word 05 14 70 C.SDSP CSS sd rs2, offset[8:3](x2) Store double-word to stack (RV64) 18 04 72 C.BNEZ CB bne rs1', x0, offset[8:1] Branch if nonzero 08 10 80 C.ADD CR add rd, rd, rs2 Add registers 13 12 156 C.JR CR jalr x0, rs1, 0 Jump register 11 15 165 C.J CJ jal x0, offset[11:1] Jump 17 11 187 C.SRLI CB srli rd', rd', imm[5:0] Logical shift right, immediate 15 19 285 C.SLLI CI slli rd, rd, imm[5:0] Shift left, immediate 14 21 294 C.BEQZ CB beq rs1', x0, offset[8:1] Branch if zero 26 13 338 C.FLD CL fld rd', offset[7:3](rs1') Load double float 20 18 360 C.ADDIW CI addiw rd, rd, imm[5:0] Increment 32-bit register (RV64) 19 20 380 C.SD CL sd rs2', offset[7:3](rs1') Store double-word (RV64) 25 17 425 C.ANDI CI andi rd', rd', imm[5:0] Bitwise AND immediate 16 27 432 C.ADDI16SP CI addi x2, x2, imm[9:4] Adjust stack pointer 21 24 504 C.JAL CJ jal x1, offset[11:1] Jump and link (RV32) 22 25 550 C.ADDI4SPNC IW addi rd', x2, imm[9:2] Compute address of stack variable 24 23 552 C.SRAI CB srai rd', rd', imm[5:0] Arithmetic shift right, immediate 30 22 660 C.AND CS and rd', rd', rs2' Bitwise AND registers 27 26 702 C.FLDSP CI fld rd, offset[8:3](x2) Load double float, stack 23 34 782 C.LUI CI lui rd, imm[17:12] Load upper immediate 28 29 812 C.FSDSP CSS fsd rs2, offset[8:3](x2) Store double float to stack 31 28 868 C.FSD CL fsd rs2', offset[7:3](rs1') Store double float 29 33 957 C.SUB CS sub rd', rd', rs2' Subtract registers 34 30 1020 C.ADDW CR addw rd, rd, rs2 Add 32-bit registers (RV64) 32 32 1024 C.OR CS or rd', rd', rs2' Bitwise OR registers 37 31 1147 C.XOR CS xor rd', rd', rs2' Bitwise XOR registers 33 35 1155 C.JALR CR jalr x1, rs1, 0 Jump and link register 35 37 1295 C.EBREAK CR ebreak Breakpoint 36 38 1368 C.FLW CL flw rd', offset[6:2](rs1') Load single float (RV32) 38 36 1368 C.SUBW CS subw rd', rd', rs2' Subtract 32-bit registers (RV64) 39 39 1521 C.FLWSP CI flw rd, offset[7:2](x2) Load single float, stack (RV32) 40 40 1600 C.FSW CL fsw rs2', offset[6:2](rs1') Store single float (RV32) 41 41 1681 C.FSWSP CSS fsw rs2, offset[7:2](x2) Store single float to stack (RV32) "
I think the apostrophe (single-quote) after registers indicate that the register can only be one of the first 8 registers.
---
Not one of the most frequent instructions, but as an aside, if you've ever wondered what the popcount instruction is for:
https://vaibhavsagar.com/blog/2019/09/08/popcount/
---
discussion about the usefulness of conditional moves:
https://news.ycombinator.com/item?id=24958802
fulafel 1 day ago [–]
Have decent speedups been gotten by previous CPUs by the addition of conditional moves? IIRC for some the SPECcpu impact was negligible, amd many RISCs don't have it. RISC is about quantifying this kind of thing and skipping marginal additions after all.
reply
gergo_barany 1 day ago [–]
> Have decent speedups been gotten by previous CPUs by the addition of conditional moves?
This is not a direct answer to your question, but: I recently had to tune the conditional move generation heuristics in the GraalVM? Enterprise Edition compiler. My experience has been that you can absolutely get decent speedups of 10-20% or more with a few well-placed conditional moves. The cases where this matters are rare, but they do occur in some real-world software, where sticking a conditional move in some very hot place will have such an impact on the entire application. Conversely, you can get slowdowns of the same magnitude with badly placed conditional moves.
It's a difficult trade-off, since most branches are fairly predictable, and good branch prediction and speculative execution can very often beat a conditional move.
reply
PeCaN? 1 day ago [–]
I'm not sure about this "RISC way" stuff. From a uarch standpoint the RISC vs CISC distinction is moot and from an ISA standpoint the only real quantifiable difference seems to be being a load-store architecture.
ISAs without conditional moves tend to have predicated instructions which are functionally the same thing. I'm not actually aware of any traditionally RISC architectures that have neither conditional moves or predicated instructions. While ARMv7 removed predicated instructions as a general feature ARMv8 gained a few "conditional data processing" instructions (e.g. CSEL is basically cmov), so clearly at least ARM thinks there's a benefit even with modern branch predictors.
Conditional instructions are really, really handy when you need them. It's an escape hatch for when you have an unbiased branch and need to turn control flow into data flow.
reply
...
fulafel 1 day ago [–]
This prompted me to look through some RISC ISAs (+x86), there may be errors since I made just a cursory pass.
Seems the following have conditional moves: MIPS since IV, Alpha, x86 since PPRo, SPARC since SPARCv9
The following seem to omit conditional moves: AVR, PowerPC?, Hitachi SH, MIPS I-III, x86 up to Pentium, SPARC up to SPARCv8, ARM, PA-RISC (?)
PA-RISC, PowerPC?, ARM at least do a lot of predication and make a high investment to conditional operations (by way of dedicating a lot of bits in insn layout to it), but also end up using it a lot more often than conditional move tends to be used.
reply
brandmeyer 1 day ago [–]
ARMv7's Thumb2 has general predication of hammocks via "if-then", and ARM itself had general predication. ARMv8 has conditional select, which is quite a bit richer than conditional move. POWER has "isel". Seeing an ISA evolve a conditional move later in life is pretty strong evidence that it was useful enough to include. So would modify your list to be:
ISAs that evolved conditional move:
ISAs that started life with it:
reply
fulafel 23 hours ago [–]
Good list.
Observation re list of ISAs that evolved conditional move vs ISAs that omit conditional move: MIPS, POWER, x86, SPARC all targeted high power "fat core" applications at the point where it got added. AVR, Hitachi SH, PowerPC? didn't add it while being driven more by low power / embedded applications. And many ISAs continued to see wide use in the pre-cmov versions of the ISA in embedded space (eg MIPS) after the additions. (PowerPC? even removed it when being modeled after POWER)
reply
gsnedders 1 day ago [–]
To be clear for anyone not so up-to-speed on this: what AArch64 has (conditional select) is strictly less expressive than AArch32 (general predication).
The take away there is that general predication was found to be overly complex where the vast (vast!) majority of the benefit can be modelled with conditional select.
reply
brandmeyer 1 day ago [–]
Its less than general predication, but a little bit more than cmov/csel. The second argument can be optionally incremented and/or complemented. Combined with the dedicated zero register, you can do all sorts of interesting things to turn condition-generating instructions into data. A few interesting ones include:
y = cond ? 0 : -1; y = cond ? x : -x; x = cond ? 0 : x+1; //< look ma, circular addressing!
reply
pizlonator 1 day ago [–]
Yes. There are cases where cmov is a killer beast and for example it makes your browser faster.
JSC goes to great efforts to select it in certain cases where it’s a statistically significant overall speed up. I think the place where it’s the most effective for us is converting hole-or-undefined to undefined on array load. Even on x86 where cmov is hella weird (two operands, no immediates) it ends up being a big win.
reply
ncmncm 12 hours ago [–]
You get 2x speedup on Quicksort and all related algorithms using CMOV instructions, so: yes.
https://cantrip.org/sortfast.html
reply
---
https://www.cambus.net/assembly-instructions-distribution/
---
