![[Home]](http://www.bayleshanks.com/cartoonbayle.png)
--
if you take a descendent of the root node, and put it in its own variable, but if you change that variable you want to change the original graph, then you have to use references;
def f(bob): &a = &bob.age &a = 32 &bob.age == 32
(note that even though you got a bob, you could use it as &bob; but that you are required to say &bob.age down below when reading it later in the same lexical context, to remind you that bob may have been mutated via a side effect)
otoh if you just want to change a node in one lvalue, you dont need a reference, even though there may be side-effects (including cross-perspective side effects) within the node:
def f(bob): bob.age = 32 bob.age == 32
btw i'm not actually sure that the first case is totally a good idea; i sort of feel that as this is only a 'local side effect', that you should be able to just say bob.age == 32 in the last line, without a reference (hence without an ampersand).
after all, what if later you want to make a copy of bob.age. &bob.age would seem to say that you are taking another reference. so you shouldn't have to use an ampersand on later r-values.
and also, what if you want to copy a, and not take a reference of it? hmm.
how about:
&a = &bob.age &a = 32 bob.age == 32 b = a b = 30 &c = &b &c = 40 b == 40 a == 32 bob.age == 32
so the rules are:
hmm.. maybe it would make more sense to do this:
a = &bob.age &a = 32 bob.age == 32 b = a b = 30 c = &b &c = 40
bob.age == 32 a == 32 b == 40 c == 40
c = 50 c = 23 c == 23 b == 40
so:
what about when calling functions? if you call the function with an ampersand on the argument, like f(&x), and f()'s signature expects a reference, then assignments into this reference act actually assign into the reference. However, if f()s signature expects a non-reference, this is an error; you should pass as f(x).
if otoh you are calling a function for mutation in-place, then use the ampersand to assign the result into the reference; in this case not using the ampersand is illegal to prevent mistakes
a = 30 b = &a c = &a d = a
a++
hmmm this is kinda dumb because "a++" and "&c++" do the same thing. So really a should have to be a reference too!
so maybe you can only take a reference of something that is already a reference
a = 30 b = &a
&a = 30
maybe we have to use C notation, with two operators for ref and deref, after all?
or just always use ampersands for reference vars, and dont let links be broken?
or.. i guess this is how Python references work.. a top-level reassignment breaks the link, but accessing a member goes thru the ref. e.g.:
alice.age = 10 bob.age = 20 &a = alice.age &b = &a &c = bob.age &d = alice &e = &d &f = bob &b = &c &e = &f
&a = 30 &b = 40 &c = 50 &d.age = 60 &e.age = 70 &f.age = 80
alice.age == 10 bob.age == 20 &a == 30 &b == 40 &c == 50 &d.age == 60 &e.age == 80 &f.age == 80
hmm..
how about:
so &a = b assigns b into the reference a; &a = &b either copies b and takes a reference to the copy, or if b is a reference, copies b into a (links the references)
the only thing we lose is the ability to take a reference to a reference..
If we want to do that, C's notation might be clearer:
alice.age = 10 bob.age = 20
alice.age == 10 bob.age == 20
huh.. that's interesting.. we never used &.. that's because we're not allowed to take references of non-references..
--
--
maybe we should use * for deref and use & for something else, to match C (see ootDataNotes1):
alice.age = 10 bob.age = 20
alice.age == 10 bob.age == 20
since we aren't allowed to take a ref to a non-ref (that would cause side effects)
hmm.. then again what if we want to create a handle? oh.. i got it..:
alice.age = 10 bob.age = 20
hmm i dunno if that's good b/c
handle_a = 30
i fear we may be looking at this in the wrong way.. we want a sigil to represent a warning that a variable might be changed by a side effect from elsewhere. If one node has a reference to another, then the deref of the first node can be changed by changing the second, and the second can be changed by changing the deref of the first. Whether one node references another, or the other references the first, is besides the point. Both of them need this sigil.
Furthermore, we do NOT need the sigil if the side effect exposure is only to another node in the same graph.
Perhaps instead of talking about references we should talk about binding and unbinding nodes across graphs.
References can be a different, more complicated concept (i think they can just be represented in arcs between structures...hmmm...arcs between graphs...).
So maybe:
alice.age = 10 bob.age = 20 &a = alice.age bind(b,a) &c = bob.age unbind(b,a) bind(b,c)
&a = 30 &b = 40 &c = 50
alice.age == 10 bob.age == 20 &a == 30 &b == 50 &c == 50
hmmm...arcs between graphs... are bind and unbind merely operations on some metagraph which has the ability to refer to various other graphs? could such metagraphs be first class? are they side-effectful?
another way to look at it.. there is really only one graph in the whole program between all mutable objects (which also includes all of their immutable values). any stateful variables in the program are just a subset of this graph. when two nodes are bound, that just means that there is really only one node in this graph, but that there are multiple other nodes that point to it. when two nodes in different variables are bound, that just means that each of these variables contains an arc to the one node; in the larger graph, these two variables are just subsets. So, in this viewpoint, &x just means that &x is a subset of the total graph such that (a) it is mutable, and (b) it contains or might contain at least one arc to a node outside of itself.
so, instead of 'bind' and 'unbind', we just point arcs from two other nodes at the same node (we could still provide bind and unbind for convenience). we have operations to take a part of the total graph defined by boundaries and put it in its own variable; we have operations to combine the graphs in two variables into a third; we have operations to make copy-on-write copies of the part of a graph in a variable.
do the variables have any independent notion of what subset of the graph they correspond to? maybe it would be better if not. So, when i say you take 'part of a graph', either you just literally assign a node to a variable and the variable 'contains' everything reachable from there, or you have some operation to copy-on-write and sever below a boundary. In any case, functions on a graph often take a boundary argument. But then isn't this an argument for having the root node 'know' the current boundary and apply it before functions get to look, rather than placing the burden on every other function to take one?
so maybe each variable has a 'boundary mode' which is a choice of boundary label. we can also have 'anonymous boundary creation' which creates a boundary with an unknown label but immediately assigns that label to the specified variable's boundary mode.
should we have a different sigil for mutable variables that have side-effects on others but that cannot themselves experience side effects from others?
actually i think those shouldn't need a & at all. if you pass in an array to something that thinks it got a pure value and sorts it in place, but you maintain a reference to each element and their original array position so that after sorting you can calculate an argsort, what's the problem there?
--
haskell runST: lets you do a computation with state then after you're done throw away the state and have a pure result "Encapsulating it all" -- http://research.microsoft.com/en-us/um/people/simonpj/papers/haskell-retrospective/HaskellRetrospective-2.pdf
--
nimrod has var/const/let, rust has mut/static/let
idea is mutable variable, compile-time evaluated constant (error if cannot be evaluated at compile time), single-assignment variable
-- section 2.2 of http://www.lysator.liu.se/c/bwk-on-pascal.html complains that a system without closures, in which you only have variables with lexical scope, so in place of closures you must define a persistent semi-global variable, is annoying.
--
mb have not just one but TWO sigils for impure data, e.g. one for 'others can affect this' (this may be aliased) and one for 'this can affect others' (this holds an alias or pointer to others). both are like impure functions, the first is nondeterministic, the second is side effects
--
mb each data has an 'home base' node in one net, and the sigils are 'input' or 'output' from/to other nets
in this case maybe there is only one sigial, not too, representing when the node is merely a 'symlink' to, or equivalently, 'alias' of, another, real node. note that 'partials' are aliases, e.g. if N is a net, then if you do y = N.a, y can either be a C.O.W. copy of N.a, or an alias into N.
--
if you have an alias, can you still put in a boundary without affecting the original?
--
perhaps alias-ness and boundary should be per-perspective
--
if alias-ness is per-perspective, then the compiler can't do some optimizations on pure functions without statically knowing the perspectives, e.g. in the presence of dynamic choices of perspective
--
see 'Pure functions' in http://dlang.org/function.html
--
whether or not data is aliased depends on the current object boundaries in effect
e.g. every variable in scope will be included on some list like Python's locals() or globals(). But the references from the list of in-scope variables shouldn't 'count' as aliasing.
--
could use the Plan 9/Inferno 'everything is a file' approach to APIs:
" Filesystems, again!
There are some things that Acme can do that other editors would require a series of hacks for, though. Since the focus in Inferno is on filesystem-based interfaces, Acme does, of course, provide one. Running Acme’s win command, or just executing wm/sh& from inside Acme, will give you a shell that can see /mnt/acme. Like any other piece of the namespace, you can export(4) the /mnt/acme filesystem as well.
What can you do with this filesystem? Since Acme exposes anything one might care to do as part of the filesystem, really you can do anything you can do in Acme: highlight text, undo changes, execute a search, etc. You can completely control the editor from the shell, or even remotely from across the internet. The editor as a whole can be controlled from the top level of the filesystem, and there is a directory for each open Acme window, for controlling that window specifically, getting the contents of buffers, etc. Opening up Acme and then reading /mnt/acme/1/body will read the in-editor text of the first window which can be useful if the text is not saved or even associated with a file. Writing to it will put the text into the window, so arbitrary scripts can be used to manipulate text. There’s a special directory new that opens a new window when it is touched, so the output of a command can be opened up in a new editor window by redirecting its output to /mnt/acme/new/body. "
--
instead of distinguishing things which ARE aliased or contain aliases, could distinguish things that COULD BE aliased or contain aliases, e.g. like variables vs. values
so, a value can not contain any variables. but a variable can contain values. the values in a variable can be changed (swapped with other values). part of a variable can be taken as an alias or as a copy or as a value, or even as a move (rather, a swap). copying a variable into a value can either be forced immediately (if the other party is going to change it outside of this process's Oot runtime), or copy-on-write.
---
this whole thing is a good read but i'll also discuss excerpts:
http://blog.paralleluniverse.co/post/64210769930/spaceships2
---
" Local Actor State
In Erlang, actor state is set by recursively calling the actor function with the new state as an argument. In Pulsar, we can do the same. Here’s an example from the Pulsar tests:
(is (= 25 (let [actor (spawn #(loop [i (int 2) state (int 0)] (if (== i 0) state (recur (dec i) (+ state (int (receive)))))))] (! actor 13) (! actor 12) (join actor))))
However, Clojure is all about managing state correctly. Since only the actor can set its own state, and because an actor cannot run concurrently with itself, mutating a state variable directly shouldn’t be a problem. Every Pulsar actor has a state field that can be read like this @state and written with set-state!. Here’s another example from the tests:
(is (= 25 (let [actor (spawn #(do (set-state! 0) (set-state! (+ @state (receive))) (set-state! (+ @state (receive))) @state))] (! actor 13) (! actor 12) (join actor))))
Finally, what if we want several state fields? What if we want some or all of them to be of a primitive type? This, too, poses no risk of race conditions because all state fields are written and read only by the actor, and there is no danger of them appearing inconsistent to an observer. Pulsar supports this as an experimental feature (implemented with deftype), like so:
(is (= 25 (let [actor (spawn (actor [^int sum 0] (set! sum (int (+ sum (receive)))) (set! sum (int (+ sum (receive)))) sum))] (! actor 13) (! actor 12) (join actor))))
These are three different ways of managing actor state. Eventually, we’ll settle on just one or two (and are open to discussion about which is preferred). "
---
want some sort of way to say 'this subroutine has access to these containers of state', where 'these containers of state' might be subsets like {STDERR}, {STDERR, STDOUT}, {STDERR, database connection}, {STDERR, reference variables &P and &Q, database connection}, {STDERR, reference variable &Q, STM domain &R, non-uniform memory domain &S, read-only access to TCP port &p , read-only access to IPC/intrathread channel &c}, etc.
--
in general you want to be careful about persistent state, so oot should require a sigil when you access a non-local/persistent 'mutable variable' as opposed to just an immutable value. this includes when you call a function that accesses or changes such state, e.g. an object method, or a function with a closure.
however, you don't necessarily care about any state changes made by a subroutine you call, just state changes in those parts of world state that you care about.
e.g. if subroutine A calls internal subroutine B that temporarily creates its own persistent state via a closure, but this closure is always deleted before A returns, then A's caller doesn't care
most of the time you don't care if a supposedly pure function triggers a debug routine writes to a log file, or prints to STDERR
you don't care if a subroutine that you call offloads most of its work to a cluster supercomputer that it accesses over the network in order to compute the pure function that you need
in most cases you don't care if your call to the random number generator affects its internal state, even if another part of your application will later call that same random number generator and be affected by the change in internal state
so maybe we need to give oot routines a way to express which parts of state they care about, and make the stateful sigil relative to that.
--
" Clojure has transients, which basically means "inside this function, use a mutable value under the hood while building up the value, but make it immutable before it's returned". " -- http://augustl.com/blog/2014/an_immutable_operating_system/
---
nock vs human language: in Nock, the "subject" means state. In human language, the "subject" is often "I". is there some sense or set of conditions in which state = I?
--
Hoon paradigm for handling 'subjects' (state) might be inspiration for ways to manage state even in other noncombinatorial, languages. (dunno yet if its good, have to learn Hoon first)
--
" You can create a goroutine with any function, even a closure. But be careful: a questionable design decision was to make closures capture variables by reference instead of by value. To use an example from Go's FAQ, this innocent looking code actually contains a serious race:
values := []string{"a", "b", "c"}
for _, v := range values {
go func() {
fmt.Println(v)
done <- true
}()
}
The for loop and goroutines share memory for the variable v, so the loop's modifications to the variable are seen within the closure. For a language that exhorts us to "do not communicate by sharing memory," it sure makes it easy to accidentally share memory! (This is one reason why the default behavior of Apple's blocks extension is to capture by value.) " -- http://ridiculousfish.com/blog/posts/go_bloviations.html#go_concurrency
--
do 'bits of state' share a lot of characteristics with 'rooms' in MMO worlds or in VR, or with the autonomous 'worlds' in hyperlinked MMOs such as the opensim hypergrid?
should we call them 'rooms' or 'worlds'?
--
places you put ppl in: rooms, worlds, cities, countries, houses, buildings, towns, places
places you put inanimate objs in: boxes, shelves, cabinets, drawers, carts, trays, containers, basket, bag
agents vs inanimate: agents move on their own, respond to stimuli, have goals/wants/ beliefs
words for animate animals: agent, actor, person, entity, animal
should we have 'plants' and 'animals'?
--
argues that actors are sufficient for separating purely functional stuff, and easier to understand, so monads are not needed:
http://gbracha.blogspot.com/2011/01/maybe-monads-might-not-matter.html?m=1
--
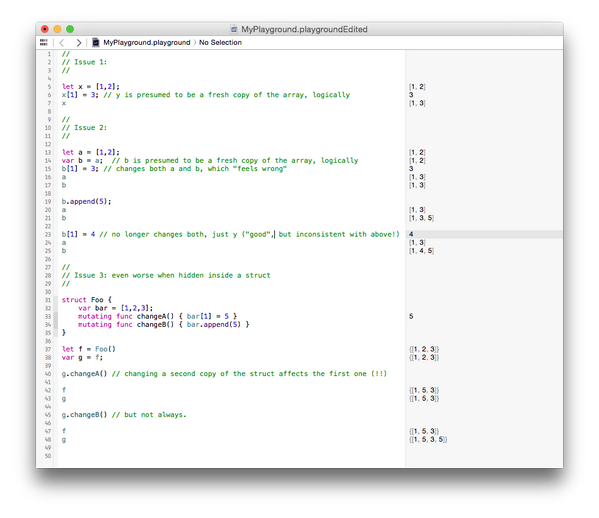 https://twitter.com/dwarfland/status/476310789763395584/photo/1
https://twitter.com/dwarfland/status/476310789763395584/photo/1
illustration of (Python-like) confusing use of references in Swift:
let x = [1,2]; x[1] = 3; x [1,3]
let a = [1,2] var b = a b[1] = 3 a [1,3] b [1,3]
b.append[5] a [1,3] b [1,3,5] note inconsistency with the above
even worse when hidden inside a struct struct Foo { var bar = [1,2,3]; mutating func changeA() {bar[1] = 5} mutating func changeB() {bar.append(5) }
let f = Foo(); var g = f;
g.changeA()
f {[1,5,3]} g {[1,5,3]}
g.changeB()
f {[1,5,3]} g {[1,5,3,5]}
note (bayle): this is the same behavior as Python but even more confusing if you though Swift's 'let' meant an immutable value type, in contrast to Swift's 'var' which would permit reference types, e.g. if you thought that things defined with 'let' would be referentially transparent. Actually it appears that 'let' just means you can't reassign to that variable, which isn't as conceptually useful and which is confusing.
---
mb have multimethods (and unattached functions in general), but then for encapsulating state (or rather, for non-referentially transparent operations), always use single-dispatch objects with methods like beautiful Io? (i mean, Io has single-dispatch objects, not that Io has both of these)
so addition could be a normal function, as could sprintf, but printf would be an object method
note that aliasable referencence variables are non-referentially transparent and hence must be objects
(purely stochastic functions are technically non-referentially transparent but we'll treat them as if they were; what we are really concerned about is spooky action at a distance, e.g. aliasing)
if you do this, though, then what about accesses to aliased reference variables which are 'within one of the current monads'? this should logically be done lazily, because accesses to something 'within one of the current monads' should not 'count' as aliased reference right? but in that case since there we may have (commutative) multiple monads, this doesn't jive with the 'one receiver' for non-referentially transparent things (although maybe it does, since each such thing's 'receiver' just means either that the thing itself is accessed only via a API/set of methods, or that accesses to it are syntactic sugar for calls to methods of its monad?).
--
this suggests a way to have a subset of commutative monads in an OOP-like way. a monad would correspond to a portion of state encapsulated in an object, with a set of methods (in some cases these methods could be accessed explicitly, in others you what looks like fields but such that accesses to these fields are syntactic sugar for getter and setter methods on the object). To say a function is 'in' the monad means two things; (a) there is a 'taint' on the type, (b) the function body can call the monad methods (possibly we could have a dynamic scoping mechanism so that you don't have to type the monad's name all the time).
so, e.g. in the IO monad we have:
deffunction f(int k) using monads IO i, IntState? s: i.printf('hi') x = s.lookup_int('x') y = i.ask_user_to_input_int() new_x = x + y + k s.change_int('x', new_x) s.commit()
so really all this is, is passing in those two objects as parameters:
deffunction f(int k, IO i, IntState? s) i.printf('hi') x = s.lookup('x') y = i.ask_user_to_input_int() new_x = x + y s.change('x', new_x) s.commit()
and if you have dynamic scoping then mb you could leave out the 'i.'s and 's.'s, as if you could leave out the 'self.' in Python
with the addition that we keep track of the 'type taint' of using i and s, and that this possibly has some impact on when we do laziness/strictness.
in Haskell what would happen is that we have, instead of a bunch of object parameters, a tower of monads. (i think) Each tail of lines within the 'do' syntax corresponds to a function that takes the previous state and computes a new state. This tail is passed to the monad lowest on the ladder to determine what to do. Then if that monad doesn't do anything, it passes it up the ladder. This 'passing up the ladder' is not built-in, it is explicitly implemented via a monad transformer.
hmm so we haven't quite captured monads, because in the above we've provided no way for any of the monads to alter control flow. e.g. the above doesn't give any way to do e.g. a backtracking monad which so i guess the above is only really a special case of monads, which in Haskell is done by monads just to use monads for as much as possible, but which in an OOP language could be implemented as above.
the remaining generality, e.g. letting the monad itself control execution via converting the function into a long expression using the monadic 'bind' function, is what makes monads non-commutative.
but at least this shows that some of the monads in haskell are really simple things that don't use the full power of monads, and are commutative because of that, and can be conceptualized in a simpler way using OOP
--
https://pypi.python.org/pypi/Contextual/0.7a1.dev
in http://www.eby-sarna.com/pipermail/peak/2007-June/002710.html, Python's famed PJ Eby says that Contextual is one of the successor packages to the old PEAK framework.
it looks like something like dynamic scoping. How is it related to my idea of semiglobals?
--
in contrast to 'everything is an object' languages, i think we want to emphasize pure functions over immutable data where possible. But aren't objects still useful for encapsulation? Can replace with typeclasses, which have both 'open functions' and 'open data'. But need to make sure no more verbose. Also, need to make sure than there is convenient syntax to mix-and-match object calls and ordinary function composition within a composition pipeline/chain.
--
where do events, event handling, event streams (functional reactive programming, FRP), spreadsheet-like cells fit on the stateful object/pure function dichotomy? At first glance one would think these are 'stateful' but FRP suggests sometimes abstracting and looking at them in a pure way.
--
i guess another role for state domains is to specify domains over which some memory consistency model holds
for things outside a state domain, are they threadlocal, or shared but with no consistency guarantees? or do we not have any non-local variables outside a state domain? i currently favor not having any non-locals outside of a state domain
--
the state domain could also be the namespace
--
---
how to reconcile the not wanting hidden aliasing with wanting properties?
e.g. we want properties in that we want obj.x to possibly be an automatically changing value that is calculated based on other stuff in obj.
i think the answer is that we want to handle this similarly to views: an object is a state domain, and attributes exposed by an object can implicitly depend on anything inside the object, but not on things outside of it. but then what if you "told" obj something via obj.tell(), and then queried attribute a via obj.x? x could indirectly depend on what obj learned via the obj.tell() mutation call.
maybe you mark obj as a state domain, and then a non-mutating query on an object is 'conditionally pure', e.g. it will return the same answer as long as the state of obj doesn't change
e.g. @obj.x will return the same value until someone does a mutation on obj
---
statemasks: pieces of state are grouped into 'statemasks', eg the caching subsystem, the logging subsystem, etc.
then in each scope you can choose a statemask to say which ones you care about in this scope. if a fn that we call only does I/O to a statemask with no overlap with our mask, and if it represents itself (via assertions or proofs in the type system) as pure aside from that I/O (barring exceptional conditions, eg disk corruption causing the cache to return the wrong value, mb even stuff like disk full causing an error upon logging altho mb we should disallow that one, etc), then we can act as if the fn is pure within our scope. Practically, this means that we can use purevars instead of &ersandImpureVars to reference it (presumably the same when we reference the function 'directly' not through a variable; presumably if its impure we'd have to use &fn to refer to it (?). (by 'presumably' i mean this is my current design decision, but i'm not sure)
in oot impure (including aliased, except for views) variables and fns would have an & to their left. vars without & are just values (from the point of view of this statespace mask).
---
ember's getters and setters and wrappers annoy ppl but it allows them to use observers rather than dirty checking.
getters and setters are already a core part of oot. observers should be a core part of oot, too (although i guess if u have getters and setters u dont really NEED observers eg ppl could always implement them w/ the getters and setters).
---
toread:
"
eric_bullington 1 day ago
| parent | flag |
It's a good point. But don't mistake Flux, GraphQL?, cursors, etc. with React.
React is just a great, fast way to interact with the DOM, with much less hoops than usual.
I think the community is still converging toward the proper way to deal with state. First it was passing callbacks, then the Flux pattern, and now there's talk of how GraphQL? and Relay fit in.
And speaking of functional approaches, there are those of us who have been inspired by the Clojurescript community (who was in turn inspired by Haskell, as I understand it) and are interested in using cursors (similar to lens) to encapsulate state.
" -- https://news.ycombinator.com/item?id=9096523
---
note: shall we use the term 'statespace'? now i'm thinking yes.
does 'statespace' mean the same thing as the term is used in dynamic systems (ie 'configuration space', eg the space of possible states)?
our 'statespace' is more like a namespace; or is it? i guess it could be defined to be the same as configuration space, so i guess we could use the term 'statespace' without cautioning that it is different from in dynamic systems..
later: mb 'state domain' would be clearer.
---
unify closures and objects.
a mistake OOP made is, we don't want every method we call to maybe have hidden side effects. It's all well and good to encapsulate methods with data representations, but that doesn't imply that they should get to have hidden side effects. But sometimes state is OK, as with a cache (which is covered by our 'masked state domains' idea), or with a generator for an immutable lazy list (eg many Haskell fibonacci functions). A generator for a lazy list is an interesting case; from the POV of the generator, it has state. But from the POV of the outside world, it doesn't; the runtime hides the state and just presents the caller with a lazy list. The key is probably that (a) the state is local, eg the fibonacci generator isn't allowed to follow some pointer to some other memory location and alter that, and (b) the generator isn't allowed to communicate directly with its caller in any other way either after it starts, aside from yielding values to the runtime that the runtime will put in the lazy list.
---
an impure operation might have annotation flags to denote what type of impurity it has ("impurity-type"):
note that operations will typically have more than one of these set to T (TRUE), eg a program that reads from a file using an interface that lets the program query the current cursor's position in the file should have BOTH 'reads from outside world' AND 'writes to program-internal state' set; if only 'reads from outside world' was set, that would only be appropriate for things such as checking what time it is, which doesn't leave any program-observable trace (aside from the time spent executing, and other implementation-dependent lowlevel details such as caches etc). Note that the line between 'program-internal state' and 'outside world' is dependent on context (the state mask). Note that a function that reads or writes state does not have to be flagged as such if the statemask masks this state (eg logging doesn't count as a write if the 'logging' state domain is masked).
---
one pattern (used by Urbit, i think) is to have the majority of the program be a purely functional transition function that is given an event as input and emits an event as output. Presumably these events could be pairs (state, actual event) and upon output the environment could then update the state as requested before emitting the actual even.
---
urbit has a pretty neat call-stack-based async dispatch system:
preliminary Urbit vocab:
" A wire is a cause. For example, if the event is an HTTP request %thus, the wire will contain (printed to cords) the server port that received the request, the IP and port of the caller, and the socket file descriptor. The data in the wire is opaque to Urbit. But...Urbit...in response to this event or to a later one, can answer the request with an action...an HTTP response. Unix parses the action wire it sent originally and responds on the right socket file descriptor.
... Moves and ducts
Event systems are renowned for "callback hell". As a purely functional environment, Arvo can't use callbacks with shared state mutation, a la node. But this is not the only common pitfall in the event landscape.
A single-threaded, nonpreemptive event dispatcher, like node or Arvo, is analogous to a multithreaded preemptive scheduler in many ways. In particular, there's a well-known duality between event flow and control flow.
One disadvantage of many event systems is unstructured event flow, often amounting to "event spaghetti". Indeed, the control-flow dual of an unstructured event system is goto.
Arvo is a structured event system whose dual is a call stack. An internal Arvo event is called a "move". A move has a duct, which is a list a wires, each of which is analagous to a stack frame. Moves come in two kinds: a %pass move calls upward, pushing a frame to the duct, while a %give move returns a result downward, popping a frame off the duct.
%pass contains a target vane name; a wire, which is a return pointer that defines this move's cause within the source vane; and a card, the event data. %give contains just the card.
The product of a vane event handler is a cell [moves new-state], a list of moves and the vane's new state.
On receiving a Unix event, Arvo turns it into a %pass by picking a vane from the Unix wire (which is otherwise opaque), then pushes it on a move stack.
The Arvo main loop pops a move off the move stack, dispatches it, replaces the result vane state, and pushes the new moves on the stack. The Unix event terminates when the stack is empty.
To dispatch a %pass move sent by vane %x, to vane %y, with wire /foo/bar, duct old-duct, and card new-card, we pass [[/x/foo/bar old-duct] new-card], a [duct card] cell, to the call method on vane %y. In other words, we push the given wire (adding the vane name onto the front) on to the old duct to create the new duct, and then pass that along with the card to the other vane.
To dispatch a %give move returned by vane %x, we check if the duct is only one wire deep. If so, return the card as an action to Unix. If not, pull the original calling vane from the top wire on the duct (by destructuring the duct as [[vane wire] plot-duct]), and call the take method on vane with [plot-duct wire card].
Intuitively, a pass is a service request and a give is a service response. The wire contains the information (normalized to a list of strings) that the caller needs to route and process the service result. The effect always gets back to its cause.
A good example of this mechanism is any internal service which is asynchronous, responding to a request in a different system event than its cause - perhaps many seconds later. For instance, the %c vane can subscribe to future versions of a file.
When %c gets its service request, it saves it with the duct in a table keyed by the subscription path. When the future version is saved on this path, the response is sent on the duct it was received from. Again, the effect gets back to its cause. Depending on the request, there may even be multiple responses to the same request, on the same duct.
In practice, the structures above are slightly simplified - Arvo manages both vanes and moves as vases, [span noun] cells. Every dispatch is type-checked.
One card structure that Arvo detects and automatically unwraps is [%meta vase] - where the vase is the vase of a card. %meta can be stacked up indefinitely. The result is that vanes themselves can operate internally at the vase level - dynamically executing code just as Arvo itself does.
The %g vane uses %meta to expose the vane mechanism to user-level applications. The same pattern, a core which is an event transceiver, is repeated across four layers: Unix, Arvo, the %g vane, and the :dojo shell application. Event security
Arvo is a "single-homed" OS which defines one plot, usually with the label our, as its identity for life. All vanes are fully trusted by our. But internal security still becomes an issue when we execute user-level code which is not fully trusted, or work with data which is not trusted.
Our security model is causal, like our event system. Every event is a cause and an effect. Event security is all about who/whom: who (other than us) caused this event; whom (other than us) it will affect. our is always authorized to do everything and hear anything, so strangers alone are tracked.
Every event has a security mask with two fields who and hum, each a (unit (set plot)). (A unit is the equivalent of Haskell's Maybe - (unit x) is either [~ x] or ~, where ~ is nil.)
If who is ~, nil, anyone else could have caused this move -- in other words, it's completely untrusted. If who is [~ ~], the empty set, no one else caused this move -- it's completely trusted. Otherwise, the move is "tainted" by anyone in the set.
If hum is ~, nil, anyone else can be affected by this move -- in other words, it's completely unfiltered. If hum is [~ ~], the empty set, no one else can hear the move -- it's completely private. Otherwise, the move is permitted to "leak" to anyone in the set.
Obviously, in most moves the security mask is propagated from cause to effect without changes. It's the exceptions that keep security exciting.
" -- http://urbit.org/docs/theory/whitepaper#-i2-and-i3-the-hoon-compiler
(now at:
https://github.com/urbit/docs/blob/3a121b1a47d99b4e56b9de8c814bd6bd2e509bd4/docs/theory/whitepaper.md and https://raw.githubusercontent.com/urbit/docs/3a121b1a47d99b4e56b9de8c814bd6bd2e509bd4/docs/theory/whitepaper.md
)
---
still not sure exactly what an 'effect system' is supposed to be, but i think my statemask system and idea that side-effects should be in the types is probably one.
capabilities can be merged with this.
for example, perhaps some function's type signature says that it is only allowed to read and mutate two particular mutable data structures. And maybe it is allowed to read, but not mutate, a third one. This would be captured in its type signature. This can be used for control of side effects (for program safety/correctness), or just for security. Capabilities are like a dynamic extension to this; a function can acquire the capability (which is a piece of data that it gets at runtime) that enables it to read or mutate or whatever some object that it previously could not access in this way.
the state domains in the statemask are named collections of this access permissions. So perhaps in the example of a function that can read and mutate two particular mutable data structures (#1 and #2), and read but not mutate a third one (#3), perhaps the first and third of these (#1 and #3) would be grouped together in a named state domain.
and these state domains could be merged with objects (and objects with namespaces). So, even if objects #1 and #3 are conceptually distinct, they are placed within the same state domain by assigning them as values to attribute fields within that state domain (which just acts like a Python Set).
We may or may not want to require that state domains cannot overlap (although they can be in a hierarchy). This seems heavy-handed but it has benefits: if we do that, then we also have a system for concurrency control because recall that Milewski says that the ownership of shared memory must be represented as a tree (see [1] and the possibly the other Milewski links i put in ootTypeNotes1.txt).
---
in general, a 'namespace' can be thought of a unique 'place' in which something else is positioned, with many such things in it; also a dict mapping names to things.
so this violates our no-aliasing rule.
so now we have 3 exceptions to our no-aliasing rule:
actually, namespaces don't have to be an exception because we can prefix them with &
---
you can always turn statefulness into immutability by replacing a variable with a sequence of versions OOP objects hold state, but OOP objects with versions := turn statefullness into immutability a closure is like a program, or a complete plan for continuing, that takes state as an argument; contrast with its dual, a Turing machine-like 'computer' implementation, which holds state and takes a program as its argument
a comment by Alan Kay:
" McCarthy?...adding an extra parameter to all "facts" that represented the "time frame" when a fact was true. This created a simple temporal logic...Strachey...always using "old" values (from the previous ((time)) frame) to make new values, which are installed in a the new frame.
..."apply" and to notice that a kind of object (a lambda "thing", which could be a closure) was bound to parameters (which kind of looked like a message)...late bound parameter evaluation -- FEXPRs rather than EXPRs -- the unevaluated expressions could be passed as parameters and evaled later. This allowed the ungainly "special forms" (like the conditional) to be dispensed with, they could be written as a kind of vanilla lazy function.
By using the temporal modeling mentioned above, one could loosen the "gears" of "eval-apply" and get functional relationships between temporal layers via safe messaging.
...((recommends)) http://publications.csail.mit.edu/lcs/pubs/pdf/MIT-LCS-TR-205.pdf " -- https://news.ycombinator.com/item?id=11808551
---
