![[Home]](http://www.bayleshanks.com/cartoonbayle.png)
motivating problem:
Usually we track time with physical time, e.g. we assign a global real number representing time to each event. But one can also only consider the ordering of events; in computation, often it does not matter if step 3 occurred at 13:30 and step 4 occurred at 14:53, just that step 4 came after step 3. So we might consider a discrete version of time.
Sometimes it is unclear whether some events came before or after others. For example, you may a distributed system with a bunch of processor nodes whose clocks are not synchronized very precisely. Or, you may be working with 'events' that are actually intervals, for example, 'processor A executes subroutine X' and 'processor B executes subroutine Y', in which case two 'events' can overlap. Or, you may be working with events whose ordering relative to each other is known in some cases but unknown in others; for example two concurrent threads that take an action A1, then wait for the other at a synchronization barrier, then take another action A2; you know that threads 1's A1 preceded thread 2's A2, but you don't know if thread 1's A1 preceded thread 2's A1.
For these reasons we often model logical time not as a totally ordered structure (similar to the natural numbers), but rather as a partial order.
In many applications we assume that each individual process's logical time is totally ordered (that is, that each individual process knows, for any pair of events that it observed or generated, which one came first; therefore all the events observed or generated by an individual process can be arranged in order as a line), but that the global logical time of a concurrent distributed system is not.
We define a logical time by defining an ordering relation on events, such as 'happens-before' or 'caused' or 'might-have-caused'.
A logical clock is a function C whose domain is events and whose range is some representation of logical time, that is, C maps events to times, or said another way, for any event e, C(e) tells us what time that event occurred at. We call the value returned by C(e) a 'timestamp'. We place a requirement on C that relates the ordering of the timestamps to the ordering of events; "if e1 < e2, then C(e1) < C(e2)".
See also 'logical clocks for consistency', below, in which we discuss schemes by which processes communicate with each other about their logical clocks for the purpose of combining their local logical time into a global logical time.
Links:
event (re)ordering models is my own term; "memory model" in programming languages; "consistency model" in theory
best introduction, highly recommended read: Hardware Memory Models (Memory Models, Part 1). See elison below.
for some authors, in shared memory, a "coherence model" is about event (re)ordering for events pertaining to a single item in memory; a "consistency model" is about event (re)ordering for events across different items. Typically, stronger guarantees are provided for coherence than for consistency; typically, coherence is taken to mean that every observer is guaranteed to observe the same sequence of values for any single item. For other authors, "coherence" and "consistency" are synonyms.
https://en.wikipedia.org/wiki/Consistency_model
partial and total orders
one technique is to attach integer timestamps to each event. Each processor sends out each event with a unique timestamp which is greater than all timestamps it has ever sent or observed (Lamport).
relaxed (totally ordered only within each variable), release (acquire-release) (partially ordered), sequentially consistent (totally ordered)
'serializability' from database literate, where event = transaction compressed to a point: "a transaction schedule is serializable if its outcome (e.g., the resulting database state) is equal to the outcome of its transactions executed serially, i.e., sequentially without overlapping in time" -- https://en.wikipedia.org/wiki/Serializability
others from http://www.cs.rice.edu/~druschel/comp413/lectures/replication.html (should we include this?):
http://corensic.wordpress.com/2011/06/13/understanding-violations-of-sequential-consistency/ gives an example where it's hard to explain a delay in terms of a single reordering (but you can explain it when you realize that different processes can observe different reorderings):
P1: A=1; t1=A; t2=B P2: B=1; t3=B; t4=A assert(!(t2 == 0 and t4==0)
the assertion can fail because it may take a long time for the writes of 1 to A and B to propagate inter-processor, even though those same writes were read locally immediately.
http://people.engr.ncsu.edu/efg/506/sum06/lectures/notes/lec20.pdf gives an example that can fail on read/read or write/write reordering (i think) but not on write/read reordering (x/y being read as "reorder the x, which in the program code is before the y, to after the y"):
P1: A = 1; flag = 1;
P2: while (flag == 0); assert(A == 1);
Example from http://people.engr.ncsu.edu/efg/506/sum06/lectures/notes/lec20.pdf of something that fails under processor consistency but not (i think) under casual ordering:
P1: A = 1;
P2: while (A==0); B = 1;
P3: while (B==0); print A;
everyone likes this example:
P1: A = 1; print B;
P2: B = 1; print A;
and this similar one, which is part of Dekker's (sp?) algorithm for critical sections:
P1: A = 1; if (B == 0) {enter critical section}
P2: B = 1; if (A == 0) {enter critical section}
note that if there are any delays, or write/read reorderings, both threads may enter the critical section
Example of counterintuitive things with 'C relaxed' ordering:
" For example, with x and y initially zero,
Thread 1: r1 = atomic_load_explicit(y, memory_order_relaxed); atomic_store_explicit(x, r1, memory_order_relaxed); Thread 2: r2 = atomic_load_explicit(x, memory_order_relaxed); atomic_store_explicit(y, 42, memory_order_relaxed);
is allowed to produce r1 == r2 == 42. "
consistency models in which we distinguish 'synchronization operations' and give them stronger consistency properties ( http://people.cs.pitt.edu/~mosse/cs2510/class-notes/Consistency1.pdf ; todo i dont quite understand these):
"an operation is defined as a synch operation if it forms a race with any operation in any sequentially consistent execution" -- http://www.cs.utah.edu/~rajeev/cs7820/pres/7820-12.pdf
" Background: Most large-scale distributed systems (i.e ., databases) apply replication for scalability, but can support only weak consistency:
DNS: Updates are propagated slowly, and inserts may not be immediately visible.
NEWS: Articles and reactions are pushed and pulled throughout the Internet, such that reactions can be seen before postings.
Lotus Notes: Geographically dispersed servers replicate documents, but make no attempt to keep (concurrent) updates mutually consistent.
WWW: Caches all over the place, but there need be no guarantee that you are reading the most recent version of a page." -- http://www.cs.rice.edu/~druschel/comp413/lectures/replication.html (should we include this?):
client-central consistency properties: Assume there is a 'client' who migrates across processes in between each read and write and who accesses shared memory from whichever process they currently reside in. We want to provide guarantees for this client but only regarding their own data.
" For concurrent operations, the absence of synchronized clocks prevents us from establishing a total order. We must allow each operation to come just before, or just after, any other in-flight writes. If we write a, initiate a write of b, then perform a read, we could see either a or b depending on which operation takes place first. After operations complete, visibility is guaranteed
On the other hand, we obviously shouldn’t interact with a value from the future–we have no way to tell what those operations will be. The latest possible state an operation can see is the one just prior to the response received by the client. " -- [1]
todo https://en.wikipedia.org/wiki/Happened-before
here's a map of some consistency models (adapted from fig. 2 of Highly Available Transactions: Virtues and Limitations by Peter Bailis, Aaron Davidson, Alan Fekete, Ali Ghodsi, Joseph M. Hellerstein, Ion Stoica, drawn by Kyle Kingsbury):
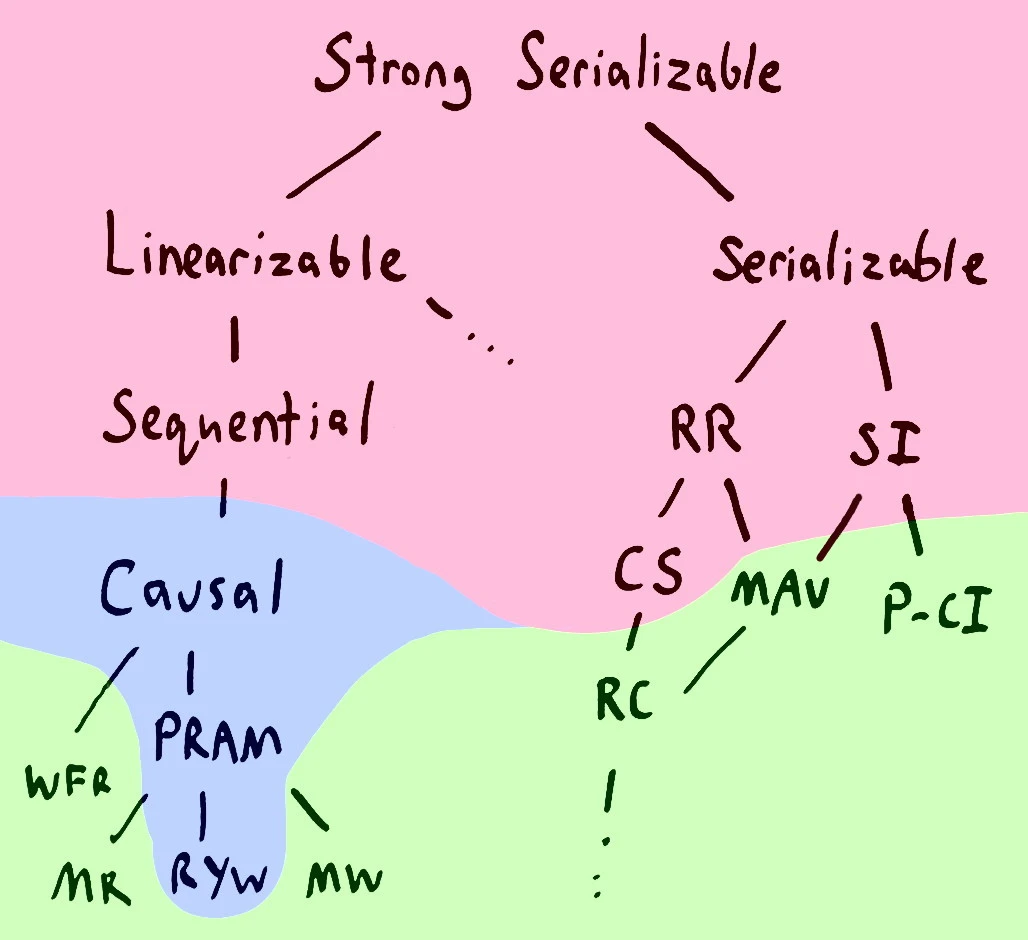
In the above figure, the pink background indicates models such that no distributed system that implements them can satisfy the availability criterion ("every user that can contact a correct (non-failing) server eventually receives a response from that server, even in the presence of arbitrary, indefinitely long network partitions between servers" -- [2]). The blue background indicates models that are compatible with availability but only if client nodes must always talk to the same server node ('sticky availability'; its definition is more complicated if different server nodes deal with different subsets of the data, see [3] section 4.1). The green background indicates models that are compatible with availability without this requirement.
Some definitions of some things in this figure (these definitions are mostly quoted from [4])
"In the modern distributed systems context, “sequential consistency” means something slightly different (and weaker) than what architects intend. What architects call “sequential consistency” is more like what distributed systems folks would call “linearizability”." [6]
Links:
Example language memory models and research about them:
what else? apparently Chu spaces can model this stuff?
http://theory.stanford.edu/~rvg/branching/branching.html http://www.cse.unsw.edu.au/~rvg/6752/handouts.html
So, you have a multinode database. The database works by having 'primaries' and secondaries; each piece of data is owned by a single 'primary' node. All write operations must go to the relevant primary node. A read from a primary node of data owned by it is guarantees to return the result of the most recent previous write operations.
In the face of a network partition, (a) a write only succeed (and only take effect) if they have been acknowledged by a majority of nodes, and (b) if the primary ends up in the minority partition, then a new primary will be elected in the majority partition.
What if the old primary in the minority partition still thinks it's the primary after the new primary has been elected? This will still not allow writes to the minority partition; because writes only succeed if they have been acknowledged by a majority of nodes, and the old primary is stuck in a minority partition and so can't get that many acknowledgments.
However, a client could write to the new primary node and then read from the old primary node. Since the old primary node is still telling clients that it is the primary, the client might think that the read gives the aforementioned guarantee that it must return the most recent previous write operation. In other words, the client could be getting 'stale reads' while thinking it has a guarantee that reads will not be stale.
'Read Your Writes' is not guaranteed here:
'Monotonic Reads' is not guaranteed here:
(this also means that the PRAM consistency property does not hold, because PRAM implies both Read Your Writes (RYW) and Monotonic Reads (MR) (ie PRAM is strictly stronger than RYW and strictly stronger than MR), and furthermore, it implies that none of causal consistency, sequential consistency, linearizable consistency hold, because causal consistency is strictly stronger than PRAM, and each of the others are strictly stronger than the previous).
" For instance, let’s say two documents are always supposed to be updated one after the other–like creating a new comment document, and writing a reference to it into a user’s feed. Stale reads allow you to violate the implicit foreign key constraint there: the user could load their feed and see a reference to comment 123, but looking up comment 123 in Mongo returns Not Found.
A user could change their name from Charles to Désirée, have the change go through successfully, but when the page reloads, still see their old name. Seeing old values could cause users to repeat operations that they should have only attempted once–for instance, adding two or three copies of an item to their cart, or double-posting a comment. Your clients may be other programs, not people–and computers are notorious for retrying “failed” operations very fast.
Stale reads can also cause lost updates. For instance, a web server might accept a request to change a user’s profile photo information, write the new photo URL to the user record in Mongo, and contact the thumbnailer service to generate resized copies and publish them to S3. The thumbnailer sees the old photo, not the newly written one. It happily resizes it, and uploads the old avatar to S3. As far as the backend and thumbnailer are concerned, everything went just fine–but the user’s photo never changes. We’ve lost their update. " -- [7]
Consider the example from the previous section, now drop the requirement that writes only succeed if they have been acknowledged by a majority of nodes. Now writes to the minority partition are visible to later reads from nodes in the minority partition.
" For instance, suppose we have a user registration service keyed by a unique username. Now imagine a partition occurs, and two users–Alice and Bob–try to claim the same username–one on each side of the partition. Alice’s request is routed to the majority primary, and she successfully registers the account. Bob, talking to the minority primary, will see his account creation request time out. The minority primary will eventually roll his account back to a nonexistent state, and when the partition heals, accept Alice’s version.
But until the minority primary detects the failure, Bob’s invalid user registration will still be visible for reads. After registration, the web server redirects Alice to /my/account to show her the freshly created account. However, this HTTP request winds up talking to a server whose client still thinks the minority primary is valid–and that primary happily responds to a read request for the account with Bob’s information.
Alice’s page loads, and in place of her own data, she sees Bob’s name, his home address, his photograph, and other things that never should have been leaked between users.
You can probably imagine other weird anomalies. Temporarily visible duplicate values for unique indexes. Locks that appear to be owned by two processes at once. Clients seeing purchase orders that never went through.
Or consider a reconciliation process that scans the list of all transactions a client has made to make sure their account balance is correct. It sees an attempted but invalid transaction that never took place, and happily sets the user’s balance to reflect that impossible transaction. The mischievous transaction subsequently disappears on rollback, leaving customer support to puzzle over why the numbers don’t add up.
Or, worse, an admin goes in to fix the rollback, assumes the invalid transaction should have taken place, and applies it to the new primary. The user sensibly retried their failed purchase, so they wind up paying twice for the same item. Their account balance goes negative. They get hit with an overdraft fine and have to spend hours untangling the problem with support. " -- [8]
The 'CAP' in CAP theorem is an acronym for Consistency, Availability, and Partition tolerance, defined as follows.
" given consistency, availability, and partition tolerance, any given system may guarantee at most two of those properties. While Eric Brewer’s CAP conjecture was phrased in these informal terms, the CAP theorem has very precise definitions:
Consistency means linearizability, and in particular, a linearizable register. Registers are equivalent to other systems, including sets, lists, maps, relational databases, and so on, so the theorem can be extended to cover all kinds of linearizable systems.
Partition tolerance means that partitions can happen. Providing consistency and availability when the network is reliable is easy. Providing both when the network is not reliable is provably impossible. If your network is not perfectly reliable–and it isn’t–you cannot choose CA. This means that all practical distributed systems on commodity hardware can guarantee, at maximum, either AP or CP.
Availability means that every request to a non-failing node must complete successfully. Since network partitions are allowed to last arbitrarily long, this means that nodes cannot simply defer responding until after the partition heals." -- [9]
(CA, AP, and CP refer to the property of satisfying two of the the three CAP properties; CA means namely Consistency+Availability, AP means Availability+Partition tolerance, CP means Consistency+Partition tolerance)
The theorem:
http://en.cppreference.com/w/c/atomic/memory_order
fences , memory barriers
https://en.wikipedia.org/wiki/Consistency_model
acquire/release ordering vs. sequentially consistent ordering: http://stackoverflow.com/questions/14861822/acquire-release-versus-sequentially-consistent-memory-order
acquire/release in terms of memory barriers: " Acquire semantics is a property which can only apply to operations which read from shared memory, whether they are read-modify-write operations or plain loads. The operation is then considered a read-acquire. Acquire semantics prevent memory reordering of the read-acquire with any read or write operation which follows it in program order.
Release semantics is a property which can only apply to operations which write to shared memory, whether they are read-modify-write operations or plain stores. The operation is then considered a write-release. Release semantics prevent memory reordering of the write-release with any read or write operation which precedes it in program order." -- http://preshing.com/20120913/acquire-and-release-semantics/#comment-20810
a release is load/store + store/store, and and acquire is load/load, load/store.
in C (at least in C++, todo) variable declared 'atomic' are automatically also considered 'volatile', i.e. the processor assumes that other threads may be reading/writing them (cite http://corensic.wordpress.com/2011/05/09/dealing-with-benign-data-races-the-c-way/ )
Links:
todo
Links:
"The strongest memory model typically considered is sequential consistency (SC), and the weakest is release consistency process consistency (RCpc)." -- [10]
---
"
Reply Travis Downs's avatar
Travis Downs · 56 weeks ago There is a second type of reordering that isn't covered by the "four possible" reorderings like StoreLoad?, and which is allowed on x86: CPUs are allowed to see *their own stores* out of order with respect to the stores from other CPUs, and you can't explain this by simple store-load reordering.
This is explained in the Intel manual with statements like "Any two CPUs *other than those performing the stores* see stores in a consistent order". The underlying hardware reason is store-forwarding: a CPU may consume its own stores from the store buffer, long before those stores have become globally visible, resulting in those stores appearing "earlier" to that CPU than to all the other CPUs.
This is often glossed over by people that say x86 only exhibits "StoreLoad?" reordering: in fact it has StoreLoad? reordering plus "SLF reordering" (SLF being store-to-load forwarding). SLF doesn't fit cleanly in into that 2x2 matrix of reorderings, it kind of has to be described explicitly.
" -- [11]
---
" Raymond Chen defined acquire and release semantics as follows, back in 2008:
An operation with acquire semantics is one which does not permit subsequent memory operations to be advanced before it. Conversely, an operation with release semantics is one which does not permit preceding memory operations to be delayed past it.
Raymond’s definition applies perfectly well to Win32 functions like InterlockedIncrementRelease?, which he was writing about at the time. It also applies perfectly well to atomic operations in C++11, such as store(1, std::memory_order_release).
It’s perhaps surprising, then, that this definition does not apply to standalone acquire and release fences in C++11!
...
This misconception is very common. Herb Sutter himself makes this mistake at 1:10:35 in part 1 of his (otherwise superb) atomic<> Weapons talk...
that’s not how C++11 release fences work. A release fence actually prevents all preceding memory operations from being reordered past subsequent writes. " -- [12]
---
intro
Shared Memory Consistency Models:A Tutorial by Sarita Adve, Kourosh Gharachorloo; Presentation: Vince Schuster
Semantics of Shared Variables & Synchronization a.k.a. Memory Models by Sarita V. Adve and Hans-J. Boehm. Great intro, with an overview of some ongoing work at the end.
Memory Consistency Models for Programming Languages
RCsc gives the following orderings ([14], slide 46): acquire -> all all -> release special -> special
RCpc gives those same orderings, except that a special write followed by a special read can be reordered ([15], slide 46).
C11/C++11 RCsc is "well aligned to the requirements of the C++11/C11 memory_order_seq_cst" and RCpc is "supported by the use of memory_order_release/ memory_order_acquire /memory_order_acqrel in C++11/C11" [16].
" The Armv8.0 support for release consistency is based around the “RCsc” (Release Consistency sequentially consistent) model described by Adve & Gharacholoo in [1], where the Acquire/Release instructions follow a sequentially consistent order with respect to each other. This is well aligned to the requirements of the C++11/C11 memory_order_seq_cst, which is the default ordering of atomics in C++11/C11.
Instructions are added as part of Armv8.3-A to support the weaker RCpc (Release Consistent processor consistent) model where it is permissible that a Store-Release followed by a Load-Acquire to a different address can be re-ordered. This model is supported by the use of memory_order_release/ memory_order_acquire /memory_order_acqrel in C++11/C11.
[1] Adve & Gharachorloo Shared Memory Consistency Models: A Tutorial " -- [17]
Note that, in a safe language like Java whose security depends on the assumption that you will not be given a pointer to an object unless you are permitted to access that object, thin-air reads could present security problems. A memory model with arbitrary thin-air reads could permit an arbitrary pointer to be manufactured from nothing; worse, on some implementations, implementations-specific behavior such as speculation, caching, and reuse of previously allocated memory, could cause this arbitrary pointer to frequently be a valid pointer to which the program should not have access. One proposed solution is for a memory model specification that permits thin-air reads to specify that not just any value can be read from thin-air, but rather, only one of the set of values that previously or concurrently occupied the memory address being read from.
Golang:
C++ and LLVM:
Linux kernel: https://www.kernel.org/doc/Documentation/memory-barriers.txt A formal kernel memory-ordering model (part 1) A Strong Formal Model of Linux-Kernel Memory Ordering * A Weak Formal Model of Linux-Kernel Memory Ordering (described in terms of differences from the strong model) https://www.kernel.org/doc/Documentation/atomic_t.txt http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2016/p0124r1.html
Java:
RISC-V:
Javascript:
---
the RMEM tool lets you run litmus tests in various operational concurrency models:
https://www.cl.cam.ac.uk/~sf502/regressions/rmem/
---
Shared Memory Consistency Models: A Tutorial
---
---
" intuitively I would assume that a properly annotated C program > where all annotated stores&loads are compiled with .rl and .aq (and > remaining stores/loads are compiled to normal s/l and never moved by the > compiler across aq/rl mops) is going to have only TSO behaviors on RVWMO. > In fact I conjecture that you get only SC behaviors if you compile all of > the annotated stores&loads to .sc (and the remaining stores and loads to > normal s/l, which are never reordered with earlier .sc loads and later .sc > stores).
Yes, that's exactly what the SC-for-DRF theorem states. C11/C++11 uses the term "atomic" for what you call "annotated". "
-- Jonas Oberhauser and Daniel Lustig, [20]
---
DRFrlx:
---
from [21] :
hierarchy of common memory consistency model strengths, from strongest to weakest:
a "woefully incomplete" characterization of these memory consistency models: consider reorderings of the following instruction pairs: load/load, load/store, store/load, store/store:
SEQUENTIAL CONSISTENCY:
" 1. All threads are interleaved into a single “thread” 2. The interleaved thread respects each thread’s original instruction ordering (“program order”) 3. Loads return the value of the most recent store to the same address, according to the interleaving
...
For performance, most processors weaken rule #2, and most weaken #1 as well.
...
Q: Can I think of an execution as an interleaving of the instructions in each thread (in some order)? ... That would make it illegal to forward values from a store buffer!.. Because with a store buffer, cores can read their own writes “early”.
Option 1: forbid store buffer forwarding, keep a simpler memory model, sacrifice performance
Option 2: change the memory model to allow store buffer forwarding, at the cost of a more complex model
Nearly all processors today choose #2
Q: Can I think of an execution as an interleaving of the instructions in each thread (in some order), with an exception for store buffer forwarding?
A:
example of the exception for store buffer forwarding:
2 CPUs. Each CPU has 2 threads: threads 1 and 2 on CPU 1, threads 3 and 4 on CPU 2. Thread 1 (on CPU 1) stores a value to memory location A, then Thread 2 reads from memory location A. Starting at about the same time, Thread 3 (on CPU 2) stores a different value to memory location A, then Thread 4 reads from memory location A. If the time it takes for these stores to propagate between CPUs is short, Thread 2 perceives an ordering on which Thread 1's store came before Thread 3's store, but Thread 4 perceives the opposite ordering. So, in this case, there is no interleaving perceived by all threads.
---
" Memory Model Landscape
Sequential Consistency (SC)
Total Store Order (TSO)
Weaker memory models
---
example of acausal paradox due to load-store reordering, from https://www.bsc.es/sites/default/files/public/u1810/arvind_0.pdf:
"Example: Ld-St Reordering Permitting a store to be issued to the memory before previous loads have completed, allows load values to be affected by future stores in the same thread" For example,
Process 1: r1 = Load(a) Store(b,1)
Process 2: r2 = Load(b) Store(a,r2)
Load-store reordering would allow the '1' stored by Process 1 into b to be loaded into r2 by process 2's load, and then stored into a by process 2's store, and then loaded into r1 from a by process 1! Implementation-wise, here is what could happen:
"
note: sometimes relaxed memory formalisms would permit similar but even more paradoxical results, called out-of-thin-air results, see
Outlawing Ghosts: Avoiding Out-of-Thin-Air Results
---
" While strong memory models like SC and SPARC/Intel-TSO are well understood, weak memory models of commercial ISAs like ARM and POWER are driven too much by microarchitectural details, and inadequately documented by manufacturers.... This forces the researchers to formalize these weak memory models by empirically determining the allowed/disallowed behaviors of commercial processors and then constructing models to fit these observations " -- Weak Memory Models: Balancing Definitional Simplicity and Implementation Flexibility
---
" SC [1] is the simplest model, but naive implementations of SC suffer from poor performance. Although researchers have proposed aggressive techniques to preserve SC [29]–[38], they are rarely adopted in commercial processors perhaps due to their hardware complexity. Instead the manufactures and researchers have chosen to present weaker memory models, e.g., TSO [2], [3], [25], [39], PSO [4], RMO [4], Alpha [5], Processor Consistency [40], Weak Consistency [41], RC [6], CRF [42], Instruction Reordering + Store Atomicity [43], POWER [11] and ARM [44]. The tutorials by Adve et al. [45] and by Maranget et al. [46] provide relationships among some of these models. A large amount of research has also been devoted to specifying the memory models of high-level languages: C++ [26], [47]–[50], Java [51]–[53],
" -- [24]
---
intro memory consistency models slides:
https://www.cs.utexas.edu/~pingali/CS395T/2006fa/lectures/consistency.pdf
---
" Recently, Lustig et al. have used Memory Ordering Specification Tables (MOSTs) to describe memory models, and proposed a hardware scheme to dynamically convert programs across memory models described in MOSTs [19]. MOST specifies the ordering strength (e.g., locally ordered, multi-copy atomic) of two instructions from the same processor under different conditions (e.g., data dependency, control dependency). " -- [25]
https://en.wikipedia.org/wiki/Consistency_model
---
great two-part intro to memory consistency models by Russ Cox. Especially the first part is wonderful and highly recommended reading. In this summary, I elide many great examples and historical discussions. If any of this is unclear to you, or if you'd like more historical detail, I recommend reading the original posts straight through instead of reading my summary.
Hardware Memory Models (Memory Models, Part 1)
"A long time ago, when everyone wrote single-threaded programs...During this fairy-tale period, there was an easy test for whether an optimization was valid: if programmers couldn't tell the difference (except for the speedup) between the unoptimized and optimized execution of a valid program, then the optimization was valid. That is, valid optimizations do not change the behavior of valid programs. ... Many hardware and compiler optimizations that were invisible (and therefore valid) in single-threaded programs produce visible changes in multithreaded programs. If valid optimizations do not change the behavior of valid programs, then either these optimizations or the existing programs must be declared invalid. Which will it be, and how can we decide?
Here is a simple example program in a C-like language. In this program and in all programs we will consider, all variables are initially set to zero.
Thread 1 Thread 2 x = 1; while(done == 0) { /* loop */ } done = 1; print(x);
If thread 1 and thread 2, each running on its own dedicated processor, both run to completion, can this program print 0?
It depends. It depends on the hardware, and it depends on the compiler. A direct line-for-line translation to assembly run on an x86 multiprocessor will always print 1. But a direct line-for-line translation to assembly run on an ARM or POWER multiprocessor can print 0. Also, no matter what the underlying hardware, standard compiler optimizations could make this program print 0 or go into an infinite loop.
“It depends” is not a happy ending. Programmers need a clear answer to whether a program will continue to work with new hardware and new compilers. And hardware designers and compiler developers need a clear answer to how precisely the hardware and compiled code are allowed to behave when executing a given program. Because the main issue here is the visibility and consistency of changes to data stored in memory, that contract is called the memory consistency model or just memory model.
Originally, the goal of a memory model was to define what hardware guaranteed to a programmer writing assembly code. In that setting, the compiler is not involved. Twenty-five years ago, people started trying to write memory models defining what a high-level programming language like Java or C++ guarantees to programmers writing code in that language. Including the compiler in the model makes the job of defining a reasonable model much more complicated.
...
Again, this post is about hardware. Let's assume we are writing assembly language for a multiprocessor computer. What guarantees do programmers need from the computer hardware in order to write correct programs? Computer scientists have been searching for good answers to this question for over forty years.
Leslie Lamport's 1979 paper “How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs” introduced the concept of sequential consistency:
The customary approach to designing and proving the correctness of multiprocess algorithms for such a computer assumes that the following condition is satisfied: the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program. A multiprocessor satisfying this condition will be called sequentially consistent.
Today we talk about not just computer hardware but also programming languages guaranteeing sequential consistency, when the only possible executions of a program correspond to some kind of interleaving of thread operations into a sequential execution. Sequential consistency is usually considered the ideal model, the one most natural for programmers to work with. It lets you assume programs execute in the order they appear on the page, and the executions of individual threads are simply interleaved in some order but not otherwise rearranged.
One might reasonably question whether sequential consistency should be the ideal model, but that's beyond the scope of this post. I will note only that considering all possible thread interleavings remains, today as in 1979, “the customary approach to designing and proving the correctness of multiprocess algorithms.” In the intervening four decades, nothing has replaced it.
Earlier I asked whether this program can print 0:
Thread 1 Thread 2 x = 1; while(done == 0) { /* loop */ } done = 1; print(x);
To make the program a bit easier to analyze, let's remove the loop and the print and ask about the possible results from reading the shared variables:
Litmus Test: Message Passing
Can this program see r1 = 1, r2 = 0?Thread 1 Thread 2 x = 1 r1 = y y = 1 r2 = x
We assume every example starts with all shared variables set to zero. Because we're trying to establish what hardware is allowed to do, we assume that each thread is executing on its own dedicated processor and that there's no compiler to reorder what happens in the thread: the instructions in the listings are the instructions the processor executes. The name rN denotes a thread-local register, not a shared variable, and we ask whether a particular setting of thread-local registers is possible at the end of an execution.
This kind of question about execution results for a sample program is called a litmus test. Because it has a binary answer—is this outcome possible or not?—a litmus test gives us a clear way to distinguish memory models: if one model allows a particular execution and another does not, the two models are clearly different. Unfortunately, as we will see later, the answer a particular model gives to a particular litmus test is often surprising.
If the execution of this litmus test is sequentially consistent, there are only six possible interleavings:
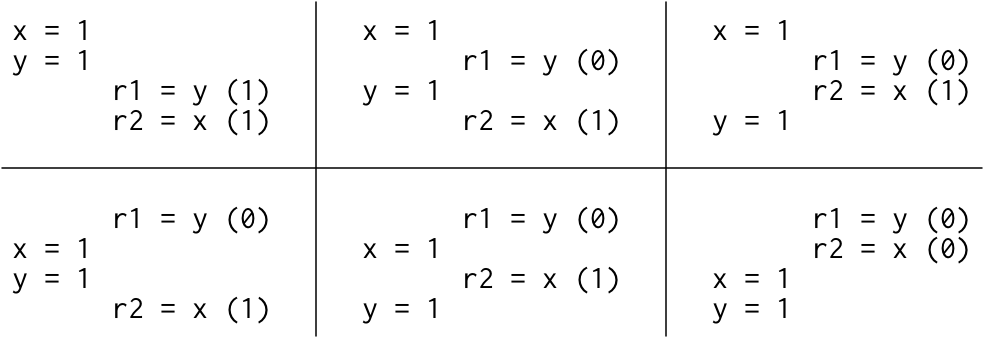
Since no interleaving ends with r1 = 1, r2 = 0, that result is disallowed. That is, on sequentially consistent hardware, the answer to the litmus test—can this program see r1 = 1, r2 = 0?—is no.
A good mental model for sequential consistency is to imagine all the processors connected directly to the same shared memory, which can serve a read or write request from one thread at a time. There are no caches involved, so every time a processor needs to read from or write to memory, that request goes to the shared memory. The single-use-at-a-time shared memory imposes a sequential order on the execution of all the memory accesses: sequential consistency.

(The three memory model hardware diagrams in this post are adapted from Maranget et al., “A Tutorial Introduction to the ARM and POWER Relaxed Memory Models.”)
This diagram is a model for a sequentially consistent machine, not the only way to build one. Indeed, it is possible to build a sequentially consistent machine using multiple shared memory modules and caches to help predict the result of memory fetches, but being sequentially consistent means that machine must behave indistinguishably from this model. If we are simply trying to understand what sequentially consistent execution means, we can ignore all of those possible implementation complications and think about this one model.
Unfortunately for us as programmers, giving up strict sequential consistency can let hardware execute programs faster, so all modern hardware deviates in various ways from sequential consistency. Defining exactly how specific hardware deviates turns out to be quite difficult. This post uses as two examples two memory models present in today's widely-used hardware: that of the x86, and that of the ARM and POWER processor families.
x86 Total Store Order (x86-TSO)
All the processors are still connected to a single shared memory, but each processor queues writes to that memory in a local write queue. The processor continues executing new instructions while the writes make their way out to the shared memory. A memory read on one processor consults the local write queue before consulting main memory, but it cannot see the write queues on other processors. The effect is that a processor sees its own writes before others do. But—and this is very important—all processors do agree on the (total) order in which writes (stores) reach the shared memory, giving the model its name: total store order, or TSO. At the moment that a write reaches shared memory, any future read on any processor will see it and use that value (until it is overwritten by a later write, or perhaps by a buffered write from another processor).
The write queue is a standard first-in, first-out queue: the memory writes are applied to the shared memory in the same order that they were executed by the processor. ... In the model, there are local write queues but no caches on the read path. Once a write reaches main memory, all processors not only agree that the value is there but also agree about when it arrived relative to writes from other processors. ...
there is a total order over all stores (writes) to main memory, and all processors agree on that order, subject to the wrinkle that each processor knows about its own writes before they reach main memory.
...
Owens et al. proposed the x86-TSO model, based on the earlier SPARCv8 TSO model.
...
ARM/POWER Relaxed Memory Model
Now let's look at an even more relaxed memory model, the one found on ARM and POWER processors. At an implementation level, these two systems are different in many ways, but the guaranteed memory consistency model turns out to be roughly similar, and quite a bit weaker than x86-TSO or even x86-TLO+CC.
The conceptual model for ARM and POWER systems is that each processor reads from and writes to its own complete copy of memory, and each write propagates to the other processors independently, with reordering allowed as the writes propagate.
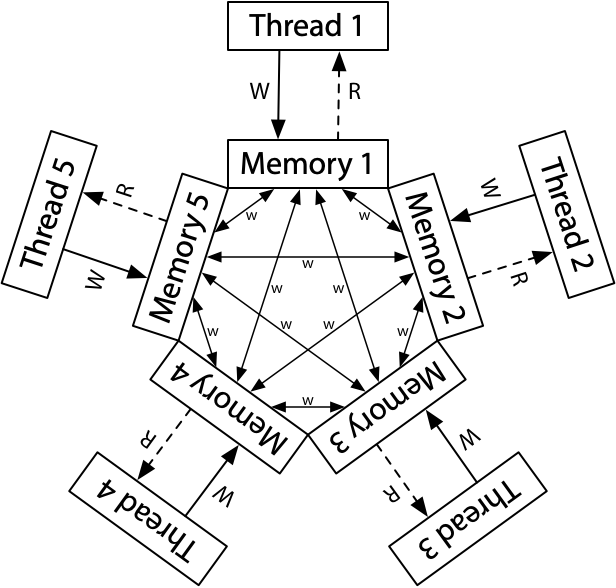
Here, there is no total store order. Not depicted, each processor is also allowed to postpone a read until it needs the result: a read can be delayed until after a later write.
... the ARM/POWER memory model is weaker than TSO: it makes fewer requirements on the hardware. ...
Like on TSO systems, ARM and POWER have barriers that we can insert into the examples above to force sequentially consistent behaviors. But the obvious question is whether ARM/POWER without barriers excludes any behavior at all. Can the answer to any litmus test ever be “no, that can’t happen?” It can, when we focus on a single memory location.
Here’s a litmus test for something that can’t happen even on ARM and POWER:
Litmus Test: Coherence
Can this program see r1 = 1, r2 = 2, r3 = 2, r4 = 1?
(Can Thread 3 see x = 1 before x = 2 while Thread 4 sees the reverse?)Thread 1 Thread 2 Thread 3 Thread 4 x = 1 x = 2 r1 = x r3 = x r2 = x r4 = x
On sequentially consistent hardware: no.
On x86 (or other TSO): no.
On ARM/POWER: no.This litmus test is like the previous one, but now both threads are writing to a single variable x instead of two distinct variables x and y. Threads 1 and 2 write conflicting values 1 and 2 to x, while Thread 3 and Thread 4 both read x twice. If Thread 3 sees x = 1 overwritten by x = 2, can Thread 4 see the opposite?
The answer is no, even on ARM/POWER: threads in the system must agree about a total order for the writes to a single memory location. That is, threads must agree which writes overwrite other writes. This property is called called coherence. Without the coherence property, processors either disagree about the final result of memory or else report a memory location flip-flopping from one value to another and back to the first. It would be very difficult to program such a system.
I'm purposely leaving out a lot of subtleties in the ARM and POWER weak memory models. For more detail, see any of Peter Sewell's papers on the topic. Also, ARMv8 strengthened the memory model by making it “multicopy atomic,” but I won't take the space here to explain exactly what that means.
There are two important points to take away. First, there is an incredible amount of subtlety here, the subject of well over a decade of academic research by very persistent, very smart people. I don't claim to understand anywhere near all of it myself. This is not something we should hope to explain to ordinary programmers, not something that we can hope to keep straight while debugging ordinary programs. Second, the gap between what is allowed and what is observed makes for unfortunate future surprises. If current hardware does not exhibit the full range of allowed behaviors—especially when it is difficult to reason about what is allowed in the first place!—then inevitably programs will be written that accidentally depend on the more restricted behaviors of the actual hardware. If a new chip is less restricted in its behaviors, the fact that the new behavior breaking your program is technically allowed by the hardware memory model—that is, the bug is technically your fault—is of little consolation. This is no way to write programs.
Weak Ordering and Data-Race-Free Sequential Consistency
By now I hope you're convinced that the hardware details are complex and subtle and not something you want to work through every time you write a program. Instead, it would help to identify shortcuts of the form “if you follow these easy rules, your program will only produce results as if by some sequentially consistent interleaving.” (We're still talking about hardware, so we're still talking about interleaving individual assembly instructions.)
Sarita Adve and Mark Hill proposed exactly this approach in their 1990 paper “Weak Ordering – A New Definition”. They defined “weakly ordered” as follows.
Although their paper was about capturing the hardware designs of that time (not x86, ARM, and POWER), the idea of elevating the discussion above specific designs, keeps the paper relevant today.
I said before that “valid optimizations do not change the behavior of valid programs.” The rules define what valid means, and then any hardware optimizations have to keep those programs working as they might on a sequentially consistent machine. Of course, the interesting details are the rules themselves, the constraints that define what it means for a program to be valid.
Adve and Hill propose one synchronization model, which they call data-race-free (DRF). This model assumes that hardware has memory synchronization operations separate from ordinary memory reads and writes. Ordinary memory reads and writes may be reordered between synchronization operations, but they may not be moved across them. (That is, the synchronization operations also serve as barriers to reordering.) A program is said to be data-race-free if, for all idealized sequentially consistent executions, any two ordinary memory accesses to the same location from different threads are either both reads or else separated by synchronization operations forcing one to happen before the other.
Let’s look at some examples, taken from Adve and Hill's paper (redrawn for presentation). Here is a single thread that executes a write of variable x followed by a read of the same variable.
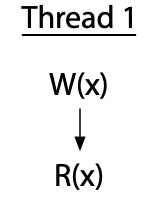
The vertical arrow marks the order of execution within a single thread: the write happens, then the read. There is no race in this program, since everything is in a single thread.
In contrast, there is a race in this two-thread program:
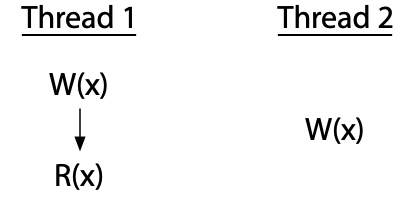
Here, thread 2 writes to x without coordinating with thread 1. Thread 2's write races with both the write and the read by thread 1. If thread 2 were reading x instead of writing it, the program would have only one race, between the write in thread 1 and the read in thread 2. Every race involves at least one write: two uncoordinated reads do not race with each other.
To avoid races, we must add synchronization operations, which force an order between operations on different threads sharing a synchronization variable. If the synchronization S(a) (synchronizing on variable a, marked by the dashed arrow) forces thread 2's write to happen after thread 1 is done, the race is eliminated:
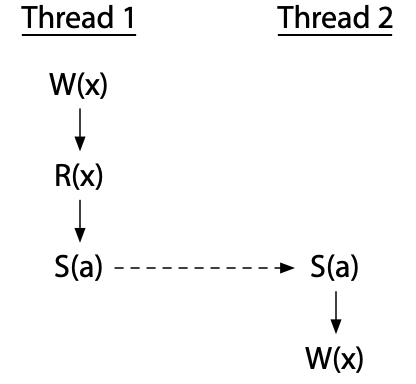
Now the write by thread 2 cannot happen at the same time as thread 1's operations.
...
Threads can be ordered by a sequence of synchronizations, even using an intermediate thread. This program has no race:
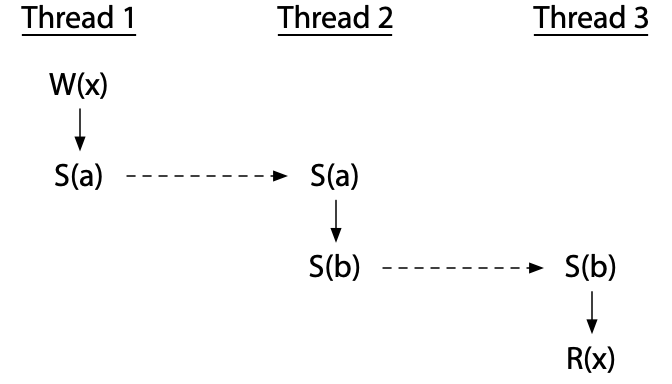
...
Adve and Hill presented weak ordering as “a contract between software and hardware,” specifically that if software avoids data races, then hardware acts as if it is sequentially consistent, which is easier to reason about than the models we were examining in the earlier sections. But how can hardware satisfy its end of the contract?
Adve and Hill gave a proof that hardware “is weakly ordered by DRF,” meaning it executes data-race-free programs as if by a sequentially consistent ordering, provided it meets a set of certain minimum requirements. I’m not going to go through the details, but the point is that after the Adve and Hill paper, hardware designers had a cookbook recipe backed by a proof: do these things, and you can assert that your hardware will appear sequentially consistent to data-race-free programs. And in fact, most relaxed hardware did behave this way and has continued to do so, assuming appropriate implementations of the synchronization operations. Adve and Hill were concerned originally with the VAX, but certainly x86, ARM, and POWER can satisfy these constraints too. This idea that a system guarantees to data-race-free programs the appearance of sequential consistency is often abbreviated DRF-SC.
DRF-SC marked a turning point in hardware memory models, providing a clear strategy for both hardware designers and software authors, at least those writing software in assembly language. As we will see in the next post, the question of a memory model for a higher-level programming language does not have as neat and tidy an answer. "
my note: i think the "certain minimum requirements" in the Adve and Hill paper for hardware to execute data-race-free programs as if by a sequentially consistent ordering are (quoting that paper, section 5.1):
" 1.Intra-processor dependencies are preserved.
2.All writes to thesamelocation can be totally ordered based on their commit times, and this is theorder in which they are observed by all processors.
3.All synchronization operations to the same location can be totally ordered based on their committimes, and this is also the order in which they are globally performed. Further, if S1 and S2 are synchronization operations and S1 is committed and globally performed before S2, then all components of S1 are committed and globally performed before any in S2.
4.A new access is not generated by a processor until all its previous synchronization operations (in program order) are committed.
5.Once a synchronization operation S by processor Pi is committed, no other synchronization operations on the same location by another processor can commit until after all reads of Pi before S (in program order) are committed and all writes of Pi before S are globally performed "
Programming Language Memory Models (Memory Models, Part 2)
"
Programming language memory models answer the question of what behaviors parallel programs can rely on to share memory between their threads. For example, consider this program in a C-like language, where both x and done start out zeroed.
Thread 1 Thread 2 x = 1; while(done == 0) { /* loop */ } done = 1; print(x);
The program attempts to send a message in x from thread 1 to thread 2, using done as the signal that the message is ready to be received. If thread 1 and thread 2, each running on its own dedicated processor, both run to completion, is this program guaranteed to finish and print 1, as intended? The programming language memory model answers that question and others like it.
Although each programming language differs in the details, a few general answers are true of essentially all modern multithreaded languages, including C, C++, Go, Java, JavaScript?, Rust, and Swift:
First, if x and done are ordinary variables, then thread 2's loop may never stop. A common compiler optimization is to load a variable into a register at its first use and then reuse that register for future accesses to the variable, for as long as possible. If thread 2 copies done into a register before thread 1 executes, it may keep using that register for the entire loop, never noticing that thread 1 later modifies done.
Second, even if thread 2's loop does stop, having observed done == 1, it may still print that x is 0. Compilers often reorder program reads and writes based on optimization heuristics or even just the way hash tables or other intermediate data structures end up being traversed while generating code. The compiled code for thread 1 may end up writing to x after done instead of before, or the compiled code for thread 2 may end up reading x before the loop.Given how broken this program is, the obvious question is how to fix it.
Modern languages provide special functionality, in the form of atomic variables or atomic operations, to allow a program to synchronize its threads. If we make done an atomic variable (or manipulate it using atomic operations, in languages that take that approach), then our program is guaranteed to finish and to print 1. Making done atomic has many effects:
The compiled code for thread 1 must make sure that the write to x completes and is visible to other threads before the write to done becomes visible.
The compiled code for thread 2 must (re)read done on every iteration of the loop.
The compiled code for thread 2 must read from x after the reads from done.
The compiled code must do whatever is necessary to disable hardware optimizations that might reintroduce any of those problems.The end result of making done atomic is that the program behaves as we want, successfully passing the value in x from thread 1 to thread 2.
In the original program, after the compiler's code reordering, thread 1 could be writing x at the same moment that thread 2 was reading it. This is a data race. In the revised program, the atomic variable done serves to synchronize access to x: it is now impossible for thread 1 to be writing x at the same moment that thread 2 is reading it. The program is data-race-free. In general, modern languages guarantee that data-race-free programs always execute in a sequentially consistent way, as if the operations from the different threads were interleaved, arbitrarily but without reordering, onto a single processor. This is the DRF-SC property from hardware memory models, adopted in the programming language context.
As an aside, these atomic variables or atomic operations would more properly be called “synchronizing atomics.” It's true that the operations are atomic in the database sense, allowing simultaneous reads and writes which behave as if run sequentially in some order: what would be a race on ordinary variables is not a race when using atomics. But it's even more important that the atomics synchronize the rest of the program, providing a way to eliminate races on the non-atomic data. The standard terminology is plain “atomic”, though, so that's what this post uses. Just remember to read “atomic” as “synchronizing atomic” unless noted otherwise.
The programming language memory model specifies the exact details of what is required from programmers and from compilers, serving as a contract between them. The general features sketched above are true of essentially all modern languages, but it is only recently that things have converged to this point: in the early 2000s, there was significantly more variation. Even today there is significant variation among languages on second-order questions, including:
What are the ordering guarantees for atomic variables themselves?
Can a variable be accessed by both atomic and non-atomic operations?
Are there synchronization mechanisms besides atomics?
Are there atomic operations that don't synchronize?
Do programs with races have any guarantees at all?After some preliminaries, the rest of this post examines how different languages answer these and related questions, along with the paths they took to get there. The post also highlights the many false starts along the way, to emphasize that we are still very much learning what works and what does not. "
Section Hardware, Litmus Tests, Happens Before, and DRF-SC then reviews the first post in the series (Hardware Memory Models (Memory Models, Part 1)), and also briefly mentions the "happens-before" terminology. I recommend reading it if you are unclear on anything up to this point.
Section [26] gives some examples of reorderings that typical compiler optimizations tend to do (on ordinary variables, where there is no synchronization instructions in the program being run), and how this makes typical programming language memory models even weaker than the weak ARM/POWER memory model discussed in the first post in the series; notably,
"All modern hardware guarantees coherence, which can also be viewed as sequential consistency for the operations on a single memory location...because of program reordering during compilation, modern languages do not even provide coherence...In this sense, programming language memory models are all weaker than the most relaxed hardware memory models.
But there are some guarantees. Everyone agrees on the need to provide DRF-SC...
The programming language memory model is an attempt to precisely answer these questions about which optimizations are allowed and which are not. By examining the history of attempts at writing these models over the past couple decades, we can learn what worked and what didn't, and get a sense of where things are headed.
Original Java Memory Model (1996)
Java was the first mainstream language to try to write down what it guaranteed to multithreaded programs...Unfortunately, this attempt, in the first edition of the Java Language Specification (1996), had at least two serious flaws. They are easy to explain with the benefit of hindsight and using the preliminaries we've already set down. At the time, they were far less obvious.
The first flaw was that volatile atomic variables were non-synchronizing, so they did not help eliminate races in the rest of the program.
... Because Java volatiles were non-synchronizing atomics, you could not use them to build new synchronization primitives. In this sense, the original Java memory model was too weak. ...
Coherence is incompatible with compiler optimizations
The orginal Java memory model was also too strong: mandating coherence—once a thread had read a new value of a memory location, it could not appear to later read the old value—disallowed basic compiler optimizations ... Coherence is easier for hardware to provide than for compilers because hardware can apply dynamic optimizations: it can adjust the optimization paths based on the exact addresses involved in a given sequence of memory reads and writes. In contrast, compilers can only apply static optimizations...The compiler's incomplete knowledge about the possible aliasing between memory locations means that actually providing coherence would require giving up fundamental optimizations.
Bill Pugh identified this and other problems in his 1999 paper “Fixing the Java Memory Model.”
" Because of these problems, and because the original Java Memory Model was difficult even for experts to understand, Pugh and others started an effort to define a new memory model for Java. That model became JSR-133 and was adopted in Java 5.0, released in 2004. The canonical reference is “The Java Memory Model” (2005), by Jeremy Manson, Bill Pugh, and Sarita Adve, with additional details in Manson's Ph.D. thesis. The new model follows the DRF-SC approach: Java programs that are data-race-free are guaranteed to execute in a sequentially consistent manner.
https://research.swtch.com/plmm#sync As we saw earlier, to write a data-race-free program, programmers need synchronization operations that can establish happens-before edges to ensure that one thread does not write a non-atomic variable concurrently with another thread reading or writing it. In Java, the main synchronization operations are:
DRF-SC only guarantees sequentially consistent behavior to programs with no data races. The new Java memory model, like the original, defined the behavior of racy programs, for a number of reasons:
Instead of relying on coherence, the new model reused the happens-before relation (already used to decide whether a program had a race at all) to decide the outcome of racing reads and writes.
The specific rules for Java are that for word-sized or smaller variables, a read of a variable (or field) x must see the value stored by some single write to x. A write to x can be observed by a read r provided r does not happen before w. That means r can observe writes that happen before r (but that aren’t also overwritten before r), and it can observe writes that race with r.
Using happens-before in this way, combined with synchronizing atomics (volatiles) that could establish new happens-before edges, was a major improvement over the original Java memory model. It provided more useful guarantees to the programmer, and it made a large number of important compiler optimizations definitively allowed. This work is still the memory model for Java today. That said, it’s also still not quite right: there are problems with this use of happens-before for trying to define the semantics of racy programs. "
The post then goes on to explain that the rules for Java up to here are not sufficient to exclude various paradoxes, including an out-of-thin-air paradox (if i understand correctly, this can be a security risk, because the out-of-thin-air value could in practice be a copy of other data that was supposed to be secret, although this post doesn't go into that). He then says that the Java spec has a lot of wording to exclude these paradoxes, but the result is that it ends up being very complicated, and was later discovered to have at least one bug.
"C++11 Memory Model (2011) ... Compared to Java, C++ deviated in two important ways. First, C++ makes no guarantees at all for programs with data races, which would seem to remove the need for much of the complexity of the Java model. Second, C++ provides three kinds of atomics: strong synchronization (“sequentially consistent”), weak synchronization (“acquire/release”, coherence-only), and no synchronization (“relaxed”, for hiding races). The relaxed atomics reintroduced all of Java's complexity about defining the meaning of what amount to racy programs. The result is that the C++ model is more complicated than Java's yet less helpful to programmers.
C++11 also defined atomic fences as an alternative to atomic variables, but they are not as commonly used and I'm not going to discuss them.
" Unlike Java, C++ gives no guarantees to programs with races. Any program with a race anywhere in it falls into “undefined behavior.” A racing access in the first microseconds of program execution is allowed to cause arbitrary errant behavior hours or days later. This is often called “DRF-SC or Catch Fire”: if the program is data-race free it runs in a sequentially consistent manner, and if not, it can do anything at all, including catch fire.
...
The weaker atomics are called acquire/release atomics, in which a release observed by a later acquire creates a happens-before edge from the release to the acquire. The terminology is meant to evoke mutexes: release is like unlocking a mutex, and acquire is like locking that same mutex. The writes executed before the release must be visible to reads executed after the subsequent acquire, just as writes executed before unlocking a mutex must be visible to reads executed after later locking that same mutex. ... Note that, for a given set of specific reads observing specific writes, C++ sequentially consistent atomics and C++ acquire/release atomics create the same happens-before edges. ... Recall that the sequentially consistent atomics required the behavior of all the atomics in the program to be consistent with some global interleaving—a total order—of the execution. Acquire/release atomics do not. They only require a sequentially consistent interleaving of the operations on a single memory location. That is, they only require coherence. ... “acquire/release” is an unfortunate name for these atomics, since the sequentially consistent ones do just as much acquiring and releasing. What's different about these is the loss of sequential consistency. It might have been better to call these “coherence” atomics. Too late. ...
C++ did not stop with the merely coherent acquire/release atomics. It also introduced non-synchronizing atomics, called relaxed atomics (memory_order_relaxed). These atomics have no synchronizing effect at all—they create no happens-before edges—and they have no ordering guarantees at all either. In fact, there is no difference between a relaxed atomic read/write and an ordinary read/write except that a race on relaxed atomics is not considered a race and cannot catch fire.
Much of the complexity of the revised Java memory model arises from defining the behavior of programs with data races. It would be nice if C++'s adoption of DRF-SC or Catch Fire—effectively disallowing programs with data races—meant that we could throw away all those strange examples we looked at earlier, so that the C++ language spec would end up simpler than Java's. Unfortunately, including the relaxed atomics ends up preserving all those concerns, meaning the C++11 spec ended up no simpler than Java's.
"
The post goes on to note that the C++ spec allowed Out Of Thin Air ("acausal") paradoxes (even in non-racy programs), given an example, and then continues with
" To recap, Java tried to exclude all acausal executions formally and failed. Then, with the benefit of Java's hindsight, C++11 tried to exclude only some acausal executions formally and also failed. C++14 then said nothing formal at all. This is not going in the right direction. "
The post then cites some other papers to make the point that the formalization of relaxed-memory/weakly-ordered concurrency seems to be incredibly difficult and error-prone.
It goes on to state that C, Rust, and Swift adopted the C++ memory model, and that there is increasing hardware support for sequentially-consistent atomics: "The effect of this convergence is that sequentially consistent atomics are now well understood and can be efficiently implemented on all major hardware platforms, making them a good target for programming language memory models."
" JavaScript Memory Model (2017) ... JavaScript? has web workers, which allow running code in another thread. As originally conceived, workers only communicated with the main JavaScript? thread by explicit message copying. With no shared writable memory, there was no need to consider issues like data races. However, ECMAScript 2017 (ES2017) added the SharedArrayBuffer? object, which lets the main thread and workers share a block of writable memory. Why do this? In an early draft of the proposal, the first reason listed is compiling multithreaded C++ code to JavaScript?.
Of course, having shared writable memory also requires defining atomic operations for synchronization and a memory model. JavaScript deviates from C++ in three important ways:
Precisely defining the behavior of racy programs leads to the usual complexities of relaxed memory semantics and how to disallow out-of-thin-air reads and the like. In addition to those challenges, which are mostly the same as elsewhere, the ES2017 definition had two interesting bugs that arose from a mismatch with the semantics of the new ARMv8 atomic instructions. These examples are adapted from Conrad Watt et al.'s 2020 paper “Repairing and Mechanising the JavaScript Relaxed Memory Model.”
...
"
Looking at C, C++, Java, JavaScript?, Rust, and Swift, we can make the following observations:
They all provide sequentially consistent synchronizing atomics for coordinating the non-atomic parts of a parallel program.
They all aim to guarantee that programs made data-race-free using proper synchronization behave as if executed in a sequentially consistent manner.
Java resisted adding weak (acquire/release) synchronizing atomics until Java 9 introduced VarHandle. JavaScript has avoided adding them as of this writing.
They all provide a way for programs to execute “intentional” data races without invalidating the rest of the program. In C, C++, Rust, and Swift, that mechanism is relaxed, non-synchronizing atomics, a special form of memory access. In Java, that mechanism is either ordinary memory access or the Java 9 VarHandle “plain” access mode. In JavaScript, that mechanism is ordinary memory access.
None of the languages have found a way to formally disallow paradoxes like out-of-thin-air values, but all informally disallow them.Meanwhile, processor manufacturers seem to have accepted that the abstraction of sequentially consistent synchronizing atomics is important to implement efficiently and are starting to do so: ARMv8 and RISC-V both provide direct support.
Finally, a truly immense amount of verification and formal analysis work has gone into understanding these systems and stating their behaviors precisely. It is particularly encouraging that Watt et al. were able in 2020 to give a formal model of a significant subset of JavaScript? and use a theorem prover to prove correctness of compilation to ARM, POWER, RISC-V, and x86-TSO.
Twenty-five years after the first Java memory model, and after many person-centuries of research effort, we may be starting to be able to formalize entire memory models. Perhaps, one day, we will also fully understand them. "
There is also a third post about proposals to change Golang's memory model.
To summarize the whole series more succinctly (again, the actual series provides tons of clear examples that i'm leaving out here):
The first post starts with "A long time ago, when everyone wrote single-threaded programs...there was an easy test for whether an optimization was valid: if programmers couldn't tell the difference (except for the speedup) between the unoptimized and optimized execution of a valid program, then the optimization was valid...Many hardware and compiler optimizations that were invisible (and therefore valid) in single-threaded programs produce visible changes in multithreaded programs. If valid optimizations do not change the behavior of valid programs, then either these optimizations or the existing programs must be declared invalid." He then presents hardware memory models as a contract between assembly programmers and hardware about what the hardware is allowed to do when presented with certain programs, and similarly, programming language memory models as a contract between programmers and compilers about program behaviors.
His take is that Sequential Consistency ("the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program", or in other words, "the only possible executions of a program correspond to some kind of interleaving of thread operations into a sequential execution") is the easiest model for programmers to understand, and in fact all of the other models are too complicated for programmers to understand. In fact, the other (weaker) models are so complicated that even specialists trying to formalize them have a hard time creating formal models that correctly represent what hardware actually does, or what compilers are allowed to do.
He discusses the TSO model ("...there is a total order over all stores (writes) to main memory, and all processors agree on that order, subject to the wrinkle that each processor knows about its own writes before they reach main memory") and the ARM/POWER relaxed model ("each processor reads from and writes to its own complete copy of memory, and each write propagates to the other processors independently, with reordering allowed as the writes propagate"). He points out that they both have the coherence property ("threads in the system must agree about a total order for the writes to a single memory location").
He discusses the DRF-SC property, which is a contract of the form "if the program is data-race-free, then observable behavior is sequentially consistent". "A program is said to be data-race-free if, for all idealized sequentially consistent executions, any two ordinary memory accesses to the same location from different threads are either both reads or else separated by synchronization operations forcing one to happen before the other." He points out that all popular hardware satisfies DRF-SC.
In the second post, he points out that, without any synchronization, typical languages provide guarantees even weaker than hardware; they don't even provide coherence (and he explains and gives examples of why typical compiler optimizations destroy comherence, and explains why this is different from the situation in hardware). He states that typical languages do still guarantee DRF-SC if synchronization is used.
He introduces the idea of synchronization primitives with atomic variables with this example:
Thread 1 Thread 2 x = 1; while(done == 0) { /* loop */ } done = 1; print(x);
and states that making "done" atomic has these effects:
He points out that atomics really should be called "synchronizing atomics" because "It's true that the operations are atomic in the database sense, allowing simultaneous reads and writes which behave as if run sequentially in some order: what would be a race on ordinary variables is not a race when using atomics. But it's even more important that the atomics synchronize the rest of the program, providing a way to eliminate races on the non-atomic data.".
He says: " The general features sketched above are true of essentially all modern languages, but it is only recently that things have converged to this point: in the early 2000s, there was significantly more variation. Even today there is significant variation among languages on second-order questions, including:
What are the ordering guarantees for atomic variables themselves?
Can a variable be accessed by both atomic and non-atomic operations?
Are there synchronization mechanisms besides atomics?
Are there atomic operations that don't synchronize?
Do programs with races have any guarantees at all?"He discusses the 1996 Java memory model, which had two flaws:
and the 2004 Java memory model:
but in the case of racy programs, there are still paradoxes.
and the C++ (also C/Rust/Swift) memory model:
"C++11 also defined atomic fences as an alternative to atomic variables, but they are not as commonly used and I'm not going to discuss them."
and the 2017 Javascript memory model:
"Precisely defining the behavior of racy programs leads to the usual complexities of relaxed memory semantics and how to disallow out-of-thin-air reads and the like. In addition to those challenges, which are mostly the same as elsewhere, the ES2017 definition had two interesting bugs"
His conclusions are that all languages listed:
His opinions are:
For Golang, he opens by stating the general design philosophy:
He goes on to say the spec should be changed to:
something i don't understand is:
