![[Home]](http://www.bayleshanks.com/cartoonbayle.png)
Table of Contents for Programming Languages: a survey
We'll refer to the top of the stack as TOP0, and to the second position on the stack as TOP1, and to the third position as TOP2, etc.
stacks:
cpython: block stack
stack ops: cpython:
arithmetic:
todo
see also [[plChLlvmLang?]]
todo
see also GENERIC, GIMPLE, RTL in [[plChMiscIntermedLangs?]]
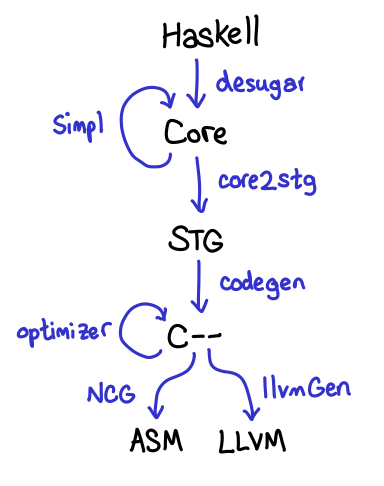
Optimizations:
Some issues with the LLVM backend: "LLVM makes assumptions which cause friction for GHC
The two major hurdles here are tables next to code and the fact that GHC uses two stacks.
LLVM does not support tables next to code well despite being discussed as far back as 7 years ago. The reason for this is the combination of GHC not being an important user of LLVM, and few GHC devs being interested in writing patches for LLVM. So instead GHC uses workarounds. For example we split methods into multiple methods (proc-point splitting) so that we can among other things place data needed by the gc inline next to the code (Tables next to code). This is bad for all kinds of reasons.
Somewhat related is the fact that GHC uses two stacks, one being heap allocated. Which is also something LLVM was not designed for and a result llvm does “struggle” with the resulting code.
The last point of friction comes in the form of compile time. Some of this is lack of optimization for the llvm backend on GHCs side. Some of it is that LLVM does at least duplicate some of the work GHC performs in the shared Cmm pipeline. Some of it is just llvm doing so much more work.
That being said it’s not clear to what degree this is unavoidable because of the nature of Haskell code. And to what degree this could be solved with redesigns for parts of GHC.
But from my perspective even just figuring out if LLVM is a suitable long term solution requires a large upfront investment of resources. Something hard to do for a project like GHC which has limited corporate sponsorship." -- https://andreaspk.github.io/posts/2019-08-25-Opinion%20piece%20on%20GHC%20backends.html
See also the Haskell section in plChSingleIntermedLangs.
https://en.wikibooks.org/wiki/Haskell/Graph_reduction
http://docs.python.org/devguide/compiler.html
" Python’s parser is an LL(1) parser mostly based off of the implementation laid out in the Dragon Book [Aho86]." -- https://docs.python.org/devguide/compiler.html#parse-trees
" The abstract syntax tree (AST) is a high-level representation of the program structure without the necessity of containing the source code; it can be thought of as an abstract representation of the source code. The specification of the AST nodes is specified using the Zephyr Abstract Syntax Definition Language (ASDL) [Wang97]. " -- https://docs.python.org/devguide/compiler.html#abstract-syntax-trees-ast
" The AST is generated from the parse tree...The function begins a tree walk of the parse tree, creating various AST nodes as it goes along. It does this by allocating all new nodes it needs, calling the proper AST node creation functions for any required supporting functions, and connecting them as needed." -- https://docs.python.org/devguide/compiler.html#parse-tree-to-ast
" A control flow graph (often referenced by its acronym, CFG) is a directed graph that models the flow of a program using basic blocks that contain the intermediate representation (abbreviated “IR”, and in this case is Python bytecode) within the blocks. Basic blocks themselves are a block of IR that has a single entry point but possibly multiple exit points. The single entry point is the key to basic blocks; it all has to do with jumps. An entry point is the target of something that changes control flow (such as a function call or a jump) while exit points are instructions that would change the flow of the program (such as jumps and ‘return’ statements). What this means is that a basic block is a chunk of code that starts at the entry point and runs to an exit point or the end of the block.
As an example, consider an ‘if’ statement with an ‘else’ block. The guard on the ‘if’ is a basic block which is pointed to by the basic block containing the code leading to the ‘if’ statement. The ‘if’ statement block contains jumps (which are exit points) to the true body of the ‘if’ and the ‘else’ body (which may be NULL), each of which are their own basic blocks. Both of those blocks in turn point to the basic block representing the code following the entire ‘if’ statement.
CFGs are usually one step away from final code output. Code is directly generated from the basic blocks (with jump targets adjusted based on the output order) by doing a post-order depth-first search on the CFG following the edges. " -- https://docs.python.org/devguide/compiler.html#control-flow-graphs
" AST to CFG to Bytecode
With the AST created, the next step is to create the CFG. The first step is to convert the AST to Python bytecode without having jump targets resolved to specific offsets (this is calculated when the CFG goes to final bytecode). Essentially, this transforms the AST into Python bytecode with control flow represented by the edges of the CFG.
Conversion is done in two passes. The first creates the namespace (variables can be classified as local, free/cell for closures, or global). With that done, the second pass essentially flattens the CFG into a list and calculates jump offsets for final output of bytecode.
...
PySymtable?_Build() begins by entering the starting code block for the AST (passed-in) and then calling the proper symtable_visit_xx function (with xx being the AST node type). Next, the AST tree is walked with the various code blocks that delineate the reach of a local variable as blocks are entered and exited using symtable_enter_block() and symtable_exit_block(), respectively.
Once the symbol table is created, it is time for CFG creation, whose code is in Python/compile.c . This is handled by several functions that break the task down by various AST node types.
Emission of bytecode is handled by the following macros: ... ADDOP() add a specified opcode ... ADDOP_JABS() create an absolute jump to a basic block ADDOP_JREL() create a relative jump to a basic block ... In addition to emitting bytecode based on the AST node, handling the creation of basic blocks must be done. Below are the macros and functions used for managing basic blocks:
NEW_BLOCK() create block and set it as current ... Once the CFG is created, it must be flattened and then final emission of bytecode occurs. Flattening is handled using a post-order depth-first search. Once flattened, jump offsets are backpatched based on the flattening and then a PyCodeObject? file is created.
" -- https://docs.python.org/devguide/compiler.html#ast-to-cfg-to-bytecode
Links:
The PyPy? project has two goals (1) a reimplementation of Python in RPython, (2) to be a generic toolkit for programming language implementation based on RPython. This section is only about (1). For (2), see PyPy (seen as a toolkit for creating programming languages) . For RPython considered as a language in itself, see RPython.
i'm not positive that everything here pertains to Perl5 and not some other version of Perl..
Links:
Perl6 source code is parsed and the parse tree is annotated by firing "action methods" during parsing. The annotated AST is called a QAST. The QAST is then compiled to a virtual machine bytecode. Various virtual machines are planned to be supported, include Parrot, JVM, and MoarVM?. The compilation steps from source code to bytecode are implemented in a subset of Perl6 called 'NQP' (Not Quite Perl).
For MoarVM? considered as a language in itself, see the relevant section of [1].
The Perl6 object model is being reimplemented in the 6model project.
Links:
Squeak runs on a VM.
The VM is implemented in Slang, a subset of Smalltalk that can be efficiently optimized.
http://prog21.dadgum.com/127.html
Erlang -> Core Erlang -> BEAM -> optimized BEAM
http://www.gnu.org/software/guile/docs/master/guile.html/Compiler-Tower.html#Compiler-Tower
" Guile defines a tower of languages, starting at Scheme and progressively simplifying down to languages that resemble the VM instruction set (see Instruction Set).
Each language knows how to compile to the next, so each step is simple and understandable. Furthermore, this set of languages is not hardcoded into Guile, so it is possible for the user to add new high-level languages, new passes, or even different compilation targets.
Languages are registered in the module, (system base language):
(use-modules (system base language))
They are registered with the define-language form.
Scheme Syntax: define-language [#:name] [#:title] [#:reader] [#:printer] [#:parser=#f] [#:compilers='()] [#:decompilers='()] [#:evaluator=#f] [#:joiner=#f] [#:for-humans?=#t] [#:make-default-environment=make-fresh-user-module]
Define a language.
This syntax defines a <language> object, bound to name in the current environment. In addition, the language will be added to the global language set. For example, this is the language definition for Scheme:
(define-language scheme
#:title "Scheme"
#:reader (lambda (port env) ...)
#:compilers `((tree-il . ,compile-tree-il))
#:decompilers `((tree-il . ,decompile-tree-il))
#:evaluator (lambda (x module) (primitive-eval x))
#:printer write
#:make-default-environment (lambda () ...))The interesting thing about having languages defined this way is that they present a uniform interface to the read-eval-print loop. This allows the user to change the current language of the REPL:
scheme@(guile-user)> ,language tree-il Happy hacking with Tree Intermediate Language! To switch back, type `,L scheme'. tree-il@(guile-user)> ,L scheme Happy hacking with Scheme! To switch back, type `,L tree-il'. scheme@(guile-user)>
" -- http://www.gnu.org/software/guile/docs/master/guile.html/Compiler-Tower.html#Compiler-Tower
The normal tower of languages when compiling Scheme goes like this:
Scheme
Tree Intermediate Language (Tree-IL)
Continuation-Passing Style (CPS)
Bytecode http://wingolog.org/archives/2013/11/26/a-register-vm-for-guile
See also Guile section of proj-plbook-plChLispLangs, [[proj-plbook-plChMiscIntermedLang?]], proj-plbook-plChSingleIntermedLangs, proj-plbook-plChTargetsImpl.
http://nominolo.blogspot.com/2012/07/implementing-fast-interpreters.html
Links:
Lua-like bytecode.
VM instructions [2] (50 instructions):
Links:
" Given this:
def a(&block)
yield
end def b
yield
endRunning `a {1+1}` is 4x slower than running `b {1+1}`. " -- https://news.ycombinator.com/item?id=9120409
Why is it slower? "There are two expensive things going on here: first, vm_make_env_object is creating a new environment for the call. This ends up doing a heap allocation using xmalloc (see line 461). Moreover, that call to rb_proc_alloc on line 683 ends up doing an allocation to create the Proc itself. Thus, every time you call a method that has an explicitly defined block parameter, you incur this allocation cost – and heap allocations are far slower than anything you can do on the Ruby stack....why isn't it equally expensive to yield to a block, even if that block isn't explicitly declared? ...MRI has optimized this common case, providing an entirely separate pathway, from parsing through execution, for blockless yields (it's actually a primitive in YARV, the meta-language to which Ruby is compiled at execution time). Because of this special pathway, calls to yield end up being handled by a dedicated C function in the interpreter (vm_invoke_block in vm_inshelper.c, if you're interested), and are much faster than their explicitly blocked bretheren." [3]
But why?
"> Is it because declaring &block means my code in the method body can now "do stuff" with `block`, whereas in the implicit case I don't have a reference so I can't do any funny business but just yield? That would make sense.
That's exactly it. With `&block`, you get a reified Proc on which you can do all kinds of stuff[0] and which you can move around. With a `yield` and an implicit block, you can't do any of that, you can just call the block. So the interpreter can bypass all the Proc reification as it knows the developer won't be able to use it, it can keep just a C-level structure instead of having to setup a Ruby-level object.
There's a not-completely-dissimilar situation with `arguments` in javascript: if you're using it, the runtime has to leave a number of optimisations off because you can do much, much more with it than with just formal arguments.
[0] http://ruby-doc.org//core-2.2.0/Proc.html has plenty of fun methods, which you can only access via a reified proc " -- [4]
"
mdavidn 1 day ago
This isn't just a syntactic difference. A Proc can outlive the method that defined it, so the interpreter must lift local variables from the stack to the heap. A block, however, can never outlive the method that defined it, so local variables can remain on the stack. In theory, the interpreter could perform an escape analysis and implicitly convert `block.call` to `yield` if no `block` reference survives local scope. Presumably MRI 2.3 does this analysis.
Python has a similar performance impact for closures. Defining a lambda forces local variables onto the heap, even if the lambda is never instantiated, e.g. when defined inside an infrequently true condition.
reply " -- [5]
Links:
Igor Funa has made a self-hosting Turbo Pascal compiler (this is not the Borland Turbo Pascal compiler). He explains how it works:
http://turbopascal.org/turbo-pascal-internals
A list of Rust 'language items' may be found at the end of:
https://github.com/rust-lang/rust/blob/master/src/librustc/middle/lang_items.rs
my summary:
char, str, int (various sizes), unsigned int (various sizes), slice, const_ptr, mut_ptr
trait items: send, sized, unsize, copy, sync
drop
coerce_unsized
add, sub, mul, div, rem, neg, not, bitxor, bitand, bitor, shl, shr; _assign variants of most of the things on this line index, index_mut
struct items: range, range_from, range_to, range_full
cell items: unsafe_cell
more trait items: deref, deref_mut
fn, fn_mut, fn_once
eq, ord
fn items: str_eq
// A number of panic-related lang items. The `panic` item corresponds to
// divide-by-zero and various panic cases with `match`. The
// `panic_bounds_check` item is for indexing arrays.
//
// The `begin_unwind` lang item has a predefined symbol name and is sort of
// a "weak lang item" in the sense that a crate is not required to have it
// defined to use it, but a final product is required to define it
// somewhere. Additionally, there are restrictions on crates that use a weak
// lang item, but do not have it defined.panic_fn, panic_bounds_check_fn, panic_fmtexchange_malloc_fn, exchange_free_fn, strdup_uniq_fn
start_fn;
eh_personality, eh_personality_catch, eh_unwind_resume, msvc_try_filter
exchange_heap, owned_box
data items: phantom_data
no_copy_bound, non_zero, debug_trait
https://docs.julialang.org/en/release-0.4/devdocs/eval/
http://www.cs.utah.edu/~mflatt/racket-on-chez-jan-2018/ section 'Approach' gives an architectural overview of Racket on Chez Scheme (and contrasts it to an older version of Racket). Section 'Changes to Chez Scheme' is also of some interest for its upgrades to Chez Scheme.
https://www.cs.utah.edu/plt/publications/icfp19-fddkmstz.pdf is a similar discussion. Section 2 is a (more recent and in some ways more detailed) version of 'Approach', Section 3 describes the core 'LINKLETS' abstraction, and Section 4, LANGUAGE MISMATCHES, starting on page 78:5 is also of great interest. Section one has a useful quote about what is missing from many other virtual machines that make them inappropriate for a functional language:
"There are many virtual machines that a language implementer might choose to target, but themajor ones are not well suited to host a functional programming language. Most artificially limitthe continuation to a fixed-size call stack, preventing a programmer from using the direct, recursivestyle that naturally matches a list- or tree-shaped data declaration. Some have grudgingly tackedon a tail-call instruction, but first-class continuations are right out. Most provide numerical supportonly in the form of floating-point numbers and small integers, leaving out arbitrary precisionarithmetic. The functional-programming community sorted out these issues decades ago."
Linklets are code bundles produced by Racket’s macro expander each of which
"consumes and produces variables that have names and are potentially mutable, instead of consuming and producing values...By making the concepts of variables, imports, and exports explicit, the macro expander can cooperate withan underlying compiler to support cross-module optimizations (which turn into cross-linklet optimizations). Cross-module optimization in Racket CS is implemented by the schemify layer,while it is part of the lower-layer bytecode compiler in the existing Racket implementation. Besides using core syntactic forms, alinkletbody can directly refer to primitive functions like vector-ref and +. Those direct references allow the underlying compiler to recognize and optimize references to system primitives. Racket linklets rely on a large set of primitives -- roughly 1500 of them. In the case of building Racket on Chez Scheme, we get most of those primitives for free".
They are compiled to lambdas by the 'schemify' layer (although some very large linklets are interpreted).
"The 'builtins' layer in each column represents a broad collection of primitive datatypes, including numbers (fixnums,flonums, exact rationals, and complex numbers), lists, strings, hash tables, records, procedures,continuations, and more."
Chez Scheme has apparently been adapted to use the nanopass compiler framework ( https://github.com/nanopass/nanopass-framework-scheme ).
This is described in:
https://andykeep.com/pubs/dissertation.pdf
particularly section 3.3.3. "Workings of the new compiler", page 62.
That section says there are "approximately 50 passes and approximately 35 nanopass languages", but I can't find much documentation of these outside of the source.
Figures 5.9 and 5.10 of the dissertation are:
e ::= c
| x |
| l |
| (let (x e1) e2) |
| (labels ([l1f1]...) e) |
| (call l? e0? e1) |
| (prim e ...) |
| ⊥ |
| ⊥ |
| ⊥ |
cp ∈ Var
Figure 5.9. Final output intermediate language.
(make-closure code length) (closure-set! closure index value) (closure-ref closure index) (vector e ...) (vector-ref vector index) (cons e1 e2) (car pair) (cdr pair)
Figure 5.10. Closure-related primitives.
However this is within the context of a chapter titled "CLOSURE OPTIMIZATION" so i suspect this is 'final' only with respect to that optimization, also i don't know what the other primitives (in 'prim') are (e.g. I/O, arithmetic, etc). Section 3.3.3 says "The other big difference between the original compiler and the new compiler is the use of a graph-coloring register allocator. This change necessitates several other changes in the compiler, including the expansion of code into a near-assembly language form much earlier in the compiler", so it would be interesting to see what the form is just before this 'near-assembly language form'.
The nanopass compiler languages for Chez Scheme appear to be defined in:
https://github.com/cisco/ChezScheme/blob/07108624d347e13980d70f3a10d48dc2b2aebd7d/s/np-languages.ss
http://www.cs.utah.edu/~mflatt/racket-on-chez-jan-2018/ gives an overview of Chez Scheme's implementation in a figure and accompanying text, describing a 2k C garbage collector, a C kernel of about 16k, a 14k compiler, 29k of builtins, and an 8k macro expander (these numbers are "rough lines-of-code counts").
What is the API of this 16k C kernel? Unfortunately I could not find documentation on it. Chez Scheme does have a file called "scheme.h" but i think it is only for FFI, for C programs to include that are providing interop with Chez, rather than a core of Chez, though i could be wrong. It is described in https://cisco.github.io/ChezScheme/csug9.5/csug9_5.pdf section 4.8. "C Library Routines", pdf page 94. An example of a Chez Scheme scheme.h file (these are each platform-specific) is: https://github.com/cisco/ChezScheme/blob/master/boot/i3le/scheme.h
Another C header which appears to have a variant in each platform directory in the Chez Scheme source is equates.h:
https://github.com/cisco/ChezScheme/blob/master/boot/i3le/equates.h
Chez Scheme's source also has a file called externs.h which "sets up platform-dependent includes and extern declarations for Scheme globals not intended for use outside of the system (prefixed with S_). Scheme globals intended for use outside of the system (prefixed with S) are declared in scheme.h":
https://github.com/cisco/ChezScheme/blob/9322fba12fb4d1c3a35f468a3351bd2f2cd61842/c/externs.h
The C code in the Chez Scheme source appears to be in the folder named C:
https://github.com/cisco/ChezScheme/tree/master/c
The Mf-base directory has some makefile stuff about build targets with the word 'kernel': https://github.com/cisco/ChezScheme/blob/7af7b0787399ed0592c6954fd357399e5a4297c0/c/Mf-base
https://c9x.me/compile/bib/iburg.pdf
Generally the implementation of a high-level language in a restricted 'core' version of that same language define the core by producing a statically typed variant and disallowing various metaprogramming constructs.
