![[Home]](http://www.bayleshanks.com/cartoonbayle.png)
---
i guess besides having stuff like PSET for good "zero to pixel" for beginners, we should also aim to provide facilities for 'demoscene' type stuff. I dunno what platforms they have but i assume we need to allow some sort of basic access to modern video and sound:
what APIs are suitable here? Remember, we don't want to include entire modern APIs, just a tiny subset.
for example, this fits in 4k on a modern Windows PC (detail on requirements: [1] ):
https://www.youtube.com/watch?v=9r8pxIogxZ0
I can't find source code for the video aspects of that demo.
As for sound:
On the page [2], apparently the author says: "4klang "sources": http://noby.untergrund.net/4klang-zettai.zip (4klang 3.11, Renoise 2.8.1, provided as is, ugly and messy just like it was made)"
which contains two filesm 'pts-311f.4kp' and 'pts-f.xrns'.
The xrns file is apparently the source for the audio using Renoise, a $75 sound program [3]. But 4klang is another sound program [4]. Apparently these can be used together; another project says:
" The audio is currently being generated by 4klang synth. Music is written in Renoise DAW and exported through the 4klang VSTi plugin, resulting in a 4klang.h file and a 4klang.inc file, which hold useful defines and song data.
The 4klang.inc file should be compiled along with 4klang.asm, which holds the synth impl, together into 4klang.obj, using NASM assembler. The obj file can then be linked to the demo executable. If you want to write your own 4klang song, then you should generate new 4klang.inc and 4klang.h files and assemble the 4klang.inc/4klang.asm into a new 4klang.obj.
Then place 4klang.h and 4klang.obj into the code directory and run build.bat. " [5].
So the question for audio is, what I/O API primitives do 4klang executables access?
Also, presumably there are 'demoscene'-oriented languages and VMs (although maybe not? given the emphasis on small file sizes, mb ppl just usually write in assembly? But the 2017 revision party PC category link above allows DotNet?, although strangely not Java).
Of course, real demoscene stuff uses file compression like [6]. But we aren't trying to support that (at least, not directly), so we don't need to be a good language to write a file compressor in.
so remaining stuff to do here:
---
hmm an isa for randomly generating interesting programs should be both:
what we DON'T need is:
so, eg we don't need many registers, we don't need position-independent code
the word size is nibbles (2 bits), represented using 2s complement. Arithmetic is signed. Von Neumann architecture (self-modifying code is possible).
so here's some ideas:
The 8 three-operand instruction opcodes and mnemonics and operand signatures are:
The 8 instr-two-0 two-operand instruction opcodes and mnemonics and operand signatures are:
The 8 instr-two-1 two-operand instruction opcodes and mnemonics and operand signatures are:
The 8 instr-one-0 one-operand instruction opcodes and mnemonics and operand signatures are:
The 8 instr-one-1 one-operand instruction opcodes and mnemonics and operand signatures are:
The 8 zero-operand instruction opcodes and mnemonics and operand signatures are:
as you can see it gets a little hairy because we want to have lots of different instructions. i'm going to leave this for now, but i think the basic idea is pretty good.
---
you can unify a bunch of those variant instructions by having 4 4-bit fields (16-bit instructions). It's probably worth it to give our poor mutating algorithms more regularity. So we have:
the word size is nibbles (2 bits), represented using 2s complement. Arithmetic is signed. Von Neumann architecture (self-modifying code is possible). There is a stack and 3 registers; TOS can also be used as a register, and the second item on the stack can be accessed in register direct mode only.
Note that dynamic jumps can be accomplished by directly changing the PC.
The 16 three-operand instruction opcodes and mnemonics and operand signatures are:
The 16 two-operand instruction opcodes and mnemonics and operand signatures are:
The 16 one-operand instruction opcodes and mnemonics and operand signatures are:
The 16 zero-operand instruction opcodes and mnemonics and operand signatures are:
maybe should add more stackops...
---
wait a minute, if we are thinking about an ISA to be useful as a context for aid in compressing/decompressing data for, say, a 4k demoscene, then we can't have too many instructions because the size of the VM code in the decompressing algorithm will outweigh the compression savings. Otoh it's very important to have regularity in that case. hmm... mb get rid of the one-operand and zero-operand instructions and stuff them into the two-operand ones; that's a little more regular anyways, in the sense that it makes those instructions 'easier to find' with mutation.
so how about the following 32 instructions:
The 16 three-operand instruction opcodes and mnemonics and operand signatures are:
The 16 two-operand instruction opcodes and mnemonics and operand signatures are:
(one-operand, but still in this list)
(zero-operand, but still in this list)
also, i'm afraid that the addressing modes given above were probably too irregular for compact implementation (having addressing modes at all is bad enough). Not sure what to do about that.
also, if the goal was actually use in 4k demoscenes, we'd probably want byte words, not nibble words.
also, it may be useful to use the OVM's first-class-functions stuff, but i'm not sure if that would be worth it, either. hmm...
also, this exercise gives me some ideas that should maybe be applied to OVM:
---
hmm should look at genetic algorithms too
hmm i guess in genetic algorithms, you wouldn't want program locations to be genes; because if the two parents are doing almost the same thing at the beginning and end of the program, but one parent has a longer section in the middle, then the program locations of the stuff at the end of that parent are displaced from their corresponding program locations in the other parent; so first you want to make a mapping that maps the closely corresponding instructions in each parent.
also you'd want mutation operations not only of changing the bits of some instruction, but also inserting or deleting instructions (one or an entire segment of many instructions at once)
also maybe callable functions could serve as 'chromosomes'
also when new labels are jumped to or new functions called (maybe the functions should be called by label instead of by address?), they could cause the autocreation of a new empty memory segment (infinitely far away from all others); when code goes to the end of a memory segment that could be an implicit RET (or implicit HALT if it's the main memory segment).
---
this article [7] thinks that some languages to NOT learn are:
Dart, Objective-C, Coffeescript, Lua, and Erlang
"due to their lack of community engagement, jobs, and growth"
---
[8] points to a pastebin [9] that contains a code example from an amazing rule-based storywriting system called Inform7:
" Section 1 - Definitions
A wizard is a kind of person. A warrior is a kind of person.
A weapon is a kind of thing. A dagger is a kind of weapon. A sword is a kind of weapon. A staff is a kind of weapon.
Wielding is a thing based rulebook. The wielding rules have outcomes allow it (success), it is too heavy (failure), it is too magical (failure). The wielder is a person that varies.
To consult the rulebook for (C - a person) wielding (W - a weapon): now the wielder is C; follow the wielding rules for W.
Wielding a sword: if the wielder is not a warrior, it is too heavy. Wielding a staff: if the wielder is not a wizard, it is too magical. Wielding a dagger: allow it.
Section 2 - Example
Dungeon is a room. Gandalf is a wizard in Dungeon. Conan is a warrior in Dungeon.
The rusty dagger is a dagger in Dungeon. The elvish sword is a sword in Dungeon. The oaken staff is a staff in Dungeon.
Instead of giving a weapon (called W) to someone (called C): consult the rulebook for C wielding W; if the rule failed: let the outcome text be "[outcome of the rulebook]" in sentence case; say "[C] declines. '[outcome text].'"; otherwise: now C carries W; say "[C] gladly accepts [the W]."
The can't take people's possessions rule is not listed in any rulebook.
Test me with "give sword to gandalf / give sword to conan / give staff to conan / give staff to gandalf / give dagger to gandalf / get dagger / give dagger to conan". "
---
entirely unrelated but interesting:
"RocksDB? is used all over Facebook, powers the entire social graph. Great storage engine that pairs well with multiple DBMS: MySQL?, Mongo, Cassandra"
---
" Some years ago, I made a preliminary design for a virtual machine called "Extreme-Density Art Machine" (or EDAM for short). The primary purpose of this new platform was to facilitate the creation of extremely small demoscene productions by removing all the related problems and obstacles present in real-world platforms. There is no code/format overhead; even an empty file is a valid EDAM program that produces a visual result. There will be no ambiguities in the platform definition, no aspects of program execution that depend on the physical platform. The instruction lengths will be optimized specifically for visual effects and sound synthesis. I have been seriously thinking about reviving this project, especially now that there have been interesting excursions to the 16-byte possibility space. But I'll tell you more once I have something substantial to show. " [10]
---
"
The traditional competition categories for size-limited demos are 4K and 64K, limiting the size of the stand-alone executable to 4096 and 65536 bytes, respectively. However, as development techniques have gone forward, the 4K size class has adopted many features of the 64K class, or as someone summarized it a couple of years ago, "4K is the new 64K". There are development tools and frameworks specifically designed for 4K demos. Low-level byte-squeezing and specialized algorithmic beauty have given way to high-level frameworks and general-purpose routines. This has moved a lot of "sizecoding" activity into more extreme categories: 256B has become the new 4K. For a fine example of a modern 256-byter, see Puls by Rrrrola.
https://www.youtube.com/watch?v=R35UuntQQF8
...
The next hexadecimal order of magnitude down from 256 bytes is 16 bytes
...
A recent 23-byte Commodore 64 demo, Wallflower by 4mat of Ate Bit, suggests that this might be possible:
https://www.youtube.com/watch?v=7lcQ-HDepqk
The most groundbreaking aspect in this demo is that it is not just a simple effect but appears to have a structure reminiscent of bigger demos. It even has an end. The structure is both musical and visual. The visuals are quite glitchy, but the music has a noticeable rhythm and macrostructure. Technically, this has been achieved by using the two lowest-order bytes of the system timer to calculate values that indicate how to manipulate the sound and video chip registers. The code of the demo follows:
When I looked into the code, I noticed that it is not very optimized. The line "eor $a2", for example, seems completely redundant. This inspired me to attempt a similar trick within the sixteen-byte limitation. I experimented with both C-64 and VIC-20, and here's something I came up with for the VIC-20:
Sixteen bytes, including the two-byte PRG header. The visual side is not that interesting, but the musical output blew my mind when I first started the program in the emulator. Unfortunately, the demo doesn't work that well in real VIC-20s (due to an unemulated aspect of the I/O space). I used a real VIC-20 to come up with good-sounding alternatives, but this one is still the best I've been able to find. Here's an MP3 recording of the emulator output (with some equalization to silent out the the noisy low frequencies).
http://www.pelulamu.net/pwp/vic20/soundflower.mp3
"
" When dealing with very short programs that escape straightforward rational understanding by appearing to outgrow their length, we are dealing with chaotic systems. Programs like this aren't anything new. The HAKMEM repository from the seventies provides several examples of short audiovisual hacks for the PDP-10 mainframe, and many of these are adaptations of earlier PDP-1 hacks, such as Munching Squares, dating back to the early sixties. Fractals, likewise producing a lot of detail from simple formulas, also fall under the label of chaotic systems. "
" Some years ago, I made a preliminary design for a virtual machine called "Extreme-Density Art Machine" (or EDAM for short). The primary purpose of this new platform was to facilitate the creation of extremely small demoscene productions by removing all the related problems and obstacles present in real-world platforms. There is no code/format overhead; even an empty file is a valid EDAM program that produces a visual result. There will be no ambiguities in the platform definition, no aspects of program execution that depend on the physical platform. The instruction lengths will be optimized specifically for visual effects and sound synthesis. I have been seriously thinking about reviving this project, especially now that there have been interesting excursions to the 16-byte possibility space. But I'll tell you more once I have something substantial to show. "
aka Viznut
---
Viznut appeared to publish his EDAM (see above), renamed to IBNIZ, later in 2011:
http://viznut.fi/texts-en/ibniz.html
---
" During this period, the computer market was moving from computer word lengths based on units of 6-bits to units of 8-bits, following the introduction of the 7-bit ASCII standard. " [12]
---
https://www.youtube.com/watch?v=Qw5WLk9IeX0 shows a Sierpinski Triangle demo in 16 bytes.
see https://www.pouet.net/prod.php?which=62079 for some related code
---
" In order to let the jewels of Core Demoscene Activity shine in their full splendor, there should be a larger scale of equally glorified ways of demonstrating them. Such as interactive art. Or dynamic non-interactive. Maybe games. Virtual toys. Creative toys or games. Creative tools. Or something in the vast gray areas between the previously-mentioned categories. "
"
First phase: Toy Language. It should have an easy learning curve and reward your efforts as soon as possible. It should encourage you to experiment and gradually give you the first hints of a programming mindset. Languages such as BASIC and HTML+PHP have been popular in this phase among actual hobbyists.
Second phase: Assembly Language. While your toy language had a lot of different building blocks, you now have to get along with a limited selection. This immerses you into a "virtual world" where every individual choice you make has a tangible meaning. You may even start counting bytes or clock cycles, especially if you chose a somewhat restricted platform.
Third phase: High Level Language. After working on the lowest level of abstraction, you now have the capacity for understanding the higher ones. The structures you see in C or Java code are abstractions of the kind of structures you built from your "Lego blocks" during the previous phase. You now understand why abstractions are important, and you may also eventually begin to understand the purposes of different higher-level programming techniques and conventions.Based on this theory, I think it is a horrible mistake to recommend the modern PC platform (with Win32, DirectX?/OpenGL?, C++ and so on) to an aspiring democoder who doesn't have in-depth prior knowledge about programming. Even though it might be easy to get "outstanding" visual results with a relative ease, the programmer may become frustrated by his or her vague understanding of how and why their programs work.
The new democoders I know, even the youngest ones, have almost invariably tried out assembly programming in a constrained environment at some point of their path, even if they have eventually chosen another niche. 8-bit platforms such as C-64 or NES, usually via emulator, have been popular choices for "first hardcore coding". Sizecoding on MS-DOS has also been quite common.
Not everyone has the mindset for learning an actual "oldschool platform" on their own, however. I therefore think it might be useful to develop an "educational demoscene platform" that is easy to learn, simple in structure, fun to experiment with and "hardcore" enough for promoting a proper attitude. It might even be worthwhile to incorporate the platform in some kind of a game that motivates the player to go thru varying "challenges". Putting the game online and binding it to a social networking site may also motivate some people quite a lot and give the project some additional visibility. "
---
" The tracker format can be divided into 3 main concepts: samples & instruments, patterns and sequencing order. You can typically load or configure the parameters of samples that can be played. Certain trackers allow you to configure samples into instruments by defining behaviors on how the sample will be played when triggered under different pitches. The samples or instruments are then sequenced in patterns that will be played back under the stipulated tempo. And you can set the order of how the patterns will be played under the song sequence. These simple rules are the basis for most trackers that exist out there, each of them with their unique, quirky and often highly counter-intuitive menus that you'll grow to love. "
---
https://github.com/anttihirvonen/demoscene-starter-kits
"
Beginners
If you have little to none graphics programming experience, Processing is the best way to get started. It has an intuitive API, good documentation, lots of examples and most importantly, you can get your first visuals on screen in 10 minutes. Also, there's very little boilerplate code you need to write – instead, you can focus on developing content for your awesome first demo! "
" Getting started with Windows and Visual Studio
These kits contain examples on raw WinAPI? programming for size limited productions. Code is compiled using Microsoft Visual Studio 2013 and the compiled binaries are compressed with Crinkler to achieve minimal file sizes. Available kits
Windows1k_OpenGL: Opens an OpenGL window and draws an effect using a GLSL shader
Links
Iñigo Quílez's excellent sizecoding examples
Graphics Size Coding blog
in4k wiki (cached) a somewhat dated but interesting size coding resourceGetting the software
You can download Visual Studio 2013 Express for free
"
---
another demoscene keyword 'procedural' eg 'procedural graphics' 'procedural music'
another keyword, probably more useful for our purposes, is 'sizecoding'
---
is a blog focusing on sizecoding graphics techniques. It has a sidebar of links that i haven't explored yet.
the author makes a graphics library for demos/intros called Qoob. The idea is that, for small CGI objects, storing the list of commands to generate the object is more compact than storing the mesh and compressing it. Qoob can store this in 30 bytes:
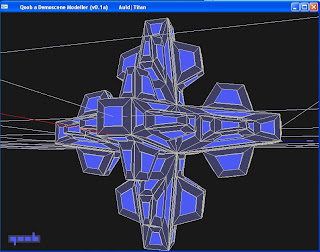
older posts eg [14] have some good 'hello world'-ish stuff for starting GPU stuff
---
" The things that excite me the most about Rust are
The borrow checker, which greatly improves memory safety (SEGFAULTs no more!),
Immutability (const) by default,
Intuitive syntactic sugar such as pattern matching,
No built-in implicit conversions between (arithmetic) types."
---
demoscene 4k and 64k ("4k and 64k intros") audio tools:
demoscene <=64k, sizecoding resources:
---
http://xmunkki.org/wiki/doku.php?id=projects:il4
---
2004 Forth JIT Compiler for 4K intros
http://neoscientists.org/~plex/win4k/index.html
---
i dont think i'll ever need this again but noting it just in case:
Floating Point Routines for the 6502 (1976) (6502.org)
pascalmemories on May 9, 2015 [-]
Around 768 bytes. The golden days of tight code and amazing minds pulling together cool code that set the framework for floating point on 'home' computers. A great reference point and piece of history.
edit: I see from the link in the comment posted by ddingus that there is also an errata with a fix for the bug in the original code. http://codebase64.org/doku.php?id=base:errata_for_rankin_s_6502_floating_point_routines
StillBored on May 10, 2015 [-]
Well, $1fee-$1d00=750 bytes of code, + the 14 zero page locations. Its really the zero page that makes the processor function at all. When I go back to 6502 assembly, it amazes me what was possible with a processor that basically had 3 independent (because they could not be combined) 8 bit registers and a 256 byte stack.
There are some C compilers (http://www.6502.org/tools/lang/) for the processor, but it quickly becomes obvious just how poorly C fits. The 6502 is basically a processor that forces one to code with a bytecode + interpreter or in native assembly.
Which brings me back to the zero page. It is is both the solution to getting anything complex done. And simultaneously the problem because there isn't a good way to allocate space there (because the zero page locations are encoded directly in the instructions).
...it precludes easily sharing routines from different projects
jjwiseman on May 9, 2015 [-]
As a reminder, the 6502 doesn't even have integer multiply or divide.
ddingus on May 9, 2015 [-]
Over the years, some pretty good routines have been developed.
http://codebase64.org/doku.php?id=base:6502_6510_maths
Tons of great little tricks in there. 6502 math coding is kind of fun in this way.
A look at old games, such as "Elite" ( http://www.iancgbell.clara.net/elite/) show many trade offs being used to make simple wireframe 3D plausible at some few frames per second.
---
"a plugin architecture based on the ideas behind Redux with a very small core (https://repl.it/blog/ide). Everything in the IDE is a plugin, which is simply a reducer, a receiver, and a React component. The reducer builds up the state required for the plugin to work, the receiver dispatches actions in response to other actions flowing through the system, and the component renders" [21]
---
"...tracker music. It’s pretty much like MIDI2 but with also samples packed in the file..."
" I used Windows’ built-in gm.dls MIDI soundbank file (again, a classic trick) to make a song with MilkyTracker? in XM module format. This is the format that was used also for many MS-DOS demoscene productions back in the 90s. "
---
comments on:
https://plg.uwaterloo.ca/~cforall/features
zestyping 1 day ago
| parent | flag | favorite | on: C for All |
There are a lot of features thrown into this language that don't seem worth the learning costs they incur. What are the problems you're really trying to fix? Focus on the things that are really important and impactful, and solve them; don't waste time on quirky features that just make the syntax more alien to C programmers.
kragen 1 day ago [-]
Yeah, Ping, I agree. It reads like they missed the key lesson of C — in Dennis Ritchie's words, "A language that doesn't have everything is actually easier to program in than some that do." And some of the things they've added vitiate some of C's key advantages — exceptions complicate the control flow, constructors and destructors introduce the execution of hidden code (which can fail), and even static overloading makes it easy to make errors about what operations will be invoked by expressions like "x + y".
An interesting exercise might be to figure out how to do the Golang feature set, or some useful subset of it, in a C-compatible or mostly-C-compatible syntax.
I do like the returnable tuples, though, and the parametric polymorphism is pretty nice.
reply
dmitrygr 1 day ago [-]
exceptions because in embedded contexts they may not always be a good idea (and C targets such contexts). overloading because it is too easy to abuse and as such it gets abused a lot by those who do not know better. The rest of us are then stuck decoding what the hell "operator +" means when applied to a "serial port driver" object
reply
reza_n 1 day ago [-]
Constructs like closures come at a cost. Function call abstraction and locality means hardware cannot easily prefetch, instruction cache misses, data cache misses, memory copying, basically, a lot of the slowness you see in dynamic languages. The point of C is to map as close to hardware as possible, so unless these constructs are free, better off without them and sticking to what CPUs can actually run at full speed.
reply
alerighi 1 day ago [-]
Clousure costs a lot if we are talking of real closures, that capture variables from the scope where they are defined, because you need to save somewhere that information, so you need to alloc an object with all the complexity associated.
And it can easily get very trick in a language like C where you don't have garbage collection and you have manually memory management, it's easy to capture things in a closure and then deallocate them, imagine if a closure captures a struct or an array that is allocated on the stack of a function for example.
I think we don't need closures in C, the only thing that I think we would need is a form of syntactic for anonymous function, that cannot capture anything of course, it will do most of the things that people uses closure for and doesn't have any performance problems or add complexity to the runtime.
reply
enriquto 1 day ago
| parent | flag | favorite | on: C for All |
I'm all for the evolution of C, but this list...
1) has some downright idiotic things (exceptions, operator overloading)
2) has a few reasonable, but mostly inconsequential things (declaration inside if, case ranges)
3) is missing a few real improvements (closures, although it is not clear whether the "nested routines" can be returned)
(but note another comment which said, "Now if you want to talk about something that actually makes manual memory management a total nightmare, look at the OP's suggestion for adding closures to C.")
bdamm 1 day ago [-]
Agree 100%. Improvements to C would be things like removing "undefined behavior", not adding more syntax sugar. If anything, C's grammar is already too bloated. (I'm looking at you, function pointer type declarations inside anonymized unions inside parameter definition lists.)
reply
dmitrygr 1 day ago [-]
Couldn't agree more. and i'll add another:
the suggested syntax is ridiculous. What is this punctuation soup?
void ?{}( S & s, int asize ) with( s ) { // constructor operator
void ^?{}( S & s ) with( s ) { // destructor operator
^x{}; ^y{}; // explicit calls to de-initializereply
ori_b 1 day ago [-]
Fair point, but changing the language won't change the amount of global state. and the associated complexity, nor will it make subsystem supervision work correctly. Changing the language will not prevent unbounded recursion or the associated stack overflows and subsystem failures. Changing the language will not fix mis-analysis of task switching overhead. And changing the language will not fix manufacturing issues with the PCBs.
As far as I'm aware, one of the very few toolchains that even try to improve on this over C are Ada/SPARK.
reply
vvanders 1 day ago [-]
> but changing the language won't change the amount of global state
Global mutable state is marked as Unsafe in Rust.
> nor will it make subsystem supervision work correctly
Erlang is built specifically around this concept.
Perfect is the enemy of good here, throwing out a whole language due to one case doesn't help anyone.
reply
ori_b 1 day ago [-]
> Global mutable state is marked as Unsafe in Rust.
It's also the simplest way to avoid dynamic allocation and the associated OOM issues. So, short of doing static analysis to bound heap usage at compile time, that makes things worse.
And Toyota already got the static analysis wrong for their stack usage. At least globals will fail to compile if they won't fit.
reply
pjmlp 1 day ago [-]
Even ANSI/ISO C working group acknowledges that “thrust the programmer” doesn’t quite work.
reply
gmueckl 1 day ago [-]
This is because trusting the programmer is fundamentally wrong, no matter the programming language. In any good development process the actual coding is the least amount of work - for a reason.
reply
pjmlp 1 day ago [-]
This was the statement I was referring to.
<quote>
Spirit of C:
a. Trust the programmer.
b. Do not prevent the programmer from doing what needs to be done.
c. Keep the language small and simple.
d. Provide only one way to do an operation.
e. Make it fast, even if it is not guaranteed to be portable.
The C programming language serves a variety of markets including safety-critical systems and secure systems.
While advantageous for system level programming, facets (a) and (b) can be problematic for safety and security.
Consequently, the C11 revision added a new facet:
</quote>
http://www.open-std.org/jtc1/sc22/wg14/www/docs/n2139.pdf
reply
pjc50 1 day ago [-]
The trouble with a "safer C variant" is that it must remove features, or at least more heavily constrain programs to a safer subset of the language. This makes it not backwards-compatible.
I think the only successful "subset of C" is MISRA.
reply
pjmlp 1 day ago [-]
Maybe Frama-C as well.
reply
fao_ 1 day ago [-]
I remember reading a paper from around 2007 that asserted that most of MISRA did not catch or significantly prevent major bugs in code, indeed it asserted that much of the standard was useless. I am failing to find it now, as I cannot remember what terms I used, and I am not at a library computer and therefore I cannot search behind paywalls beyond abstracts.
reply
zzzcpan 1 day ago [-]
Cannot say that this is unexpected, but I was interested to find some papers, presumably these two: Assessing the Value of Coding Standards: An Empirical Study [1], Language subsetting in an industrial context: A comparison of misra c 1998 and misra c 2004 [2]
[1] http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.559.7854&rep=rep1&type=pdf
[2] http://leshatton.org/Documents/MISRA_comp_1105.pdf
reply
duneroadrunner 1 day ago [-]
SaferCPlusPlus?[1], for example, is a safe subset of C++ that has compatible safe substitutes for C++'s (and therefore C's) unsafe elements. So migrating existing C/C++ code generally just requires replacing variable declarations, not restructuring the code.
For C programs, one strategy is to provide a set of macros to be used as replacements for unsafe types in variable declarations. These macros will allow you, with a compile-time directive, to switch between using the original unsafe C elements, or the compatible safe substitutes (which are C++ and require a C++ compiler).
The replacement of unsafe C types with the compatible substitute macros can be largely automated, and there is actually a nascent auto-translator[2] in the works. (Well, it's being a bit neglected at the moment :)
Custom conventions using macros to improve code quality are not that uncommon in organized C projects. Right? But this one can (optionally, theoretically) deliver complete memory safety. So you might imagine, for example, a linux distribution providing two build versions, where one is a little slower but memory safe.
[1] shameless plug: https://github.com/duneroadrunner/SaferCPlusPlus
[2] https://github.com/duneroadrunner/SaferCPlusPlus-AutoTranslation
reply
kerkeslager 1 day ago [-]
What makes you think that a safer C variant would win the hearts of UNIX kernels and embedded devs any more than C++ (which started as just a C variant).
reply
BoorishBears? 1 day ago [-]
Simplicity, no STL or templating, no OOP connotations
I don’t necessarily think it would, but if it did, those would all be reasons
reply
BruceIV? 1 day ago [-]
[actually on the Cforall team] This is basically our pitch -- the last 30 years of language design features applied to a language that is not only source-compatible with C (like C++), but actually maintains the procedural paradigm of C (unlike C++) -- idiomatic C code should require minimal to no change to make it idiomatic Cforall code, and skilled C programmers should be able to learn the extension features orthogonally, rather than needing to figure out complex interactions between, say, templates and class inheritance. We are working in the same space as C++, and do draw inspiration from C++ where useful, but with the benefit of decades of watching C++ try things to see where the important features are.
There's also some really neat language-level concurrency support; work is ongoing on new features and a shorter summary, but you can see one of our Master's student theses for details: https://uwspace.uwaterloo.ca/handle/10012/12888
reply
aidenn0 1 day ago [-]
the existence of exceptions seems to bely the idea of minimal changes to make idiomatic C code idiomatic Cforall code.
While C does have longjmp and friends, usage of them is hardly idiomatic, so most C code assumes no non-local tranfer of control happens when calling functions. Coding with non-local transfer of control and without require very different idioms.
reply
pcwalton 1 day ago [-]
I highly suspect it's not that Unix C diehards are against the idea of touching C++—it's that they're against the idea of using anything but C. I don't think anything can win over those kernel developers.
reply
nwmcsween 1 day ago [-]
Its the complexity of the language vs the benefits it provides. C has many pitfalls (UB) but its simple. IMO a language that could migrate C programmers would have dependent types and an effect system with a nice syntax.
reply
noam87 1 day ago [-]
Idris?
It can compile small enough to run on an Arduino: https://github.com/stepcut/idris-blink
reply
pjmlp 1 day ago [-]
Yep you are quite right.
Other OSes not tied to UNIX culture were always more open to reach out for C++, even if constrained to a certain subset.
reply
naasking 1 day ago [-]
Looks pretty ambitious. My take from skimming:
| will probably be confusing. |
reply
DSMan195276 1 day ago [-]
I'm more or less in agreement, but I just though it was worth adding that the tuple's could actually have a lot of merit, I think I'd like to see them (Though I'm not sure the syntax is perfect parsing wise. It might be smart to prefix them, like `tuple [int, char]` or something.).
It seems like anonymous struct's fill the void, but a big problem with anonymous struct's is their types are never equal to any other, even if all the members are the exact same. So that means that if you declare the function as returning `struct { int x0; char x1; }` directly, it's actually mostly unusable because it's impossible to actually declare a variable with the same type as the return type. Obviously, the fix is to forward declare the `struct` ahead of time in a header file somewhere and then just use that type name, but that gets annoying really fast when you end-up with a lot of them. The tuples would allow you to achieve the same thing, but with a less verbose syntax and would allow them to be considered the same type even without forward declaring them.
reply
castratikron 1 day ago [-]
GNU C is probably my favorite extension of C. There's a lot of good stuff in there. The vector extensions make it really easy to write platform agnostic SIMD code.
https://gcc.gnu.org/onlinedocs/gcc/C-Extensions.html
reply
kerkeslager 50 days ago [-]
Also, the compare-and-set operations enabling lock-free code is pretty cool.
blattimwind 50 days ago [-]
I've used nested functions more often than I'd like to admit, because dealing with insane callback-heavy APIs is made a lot easier with them.
gmueckl 50 days ago [-]
Welcome to the lambda party ;). Passing nested functions as pointers is how lambdas often work behind the scene.
Gibbon1 50 days ago [-]
I love using nested functions when I have to write state machine code. It's a hella a lot better than the old school way using macros to do the same thing.
quelsolaar 50 days ago [-]
.... The syntax is great, what is needed is updates to reflect modern hardware:
-Vector types. (With arbitrary sizes not just up to vec4 for like on GPUs)
-New operators like clamp, and other intrinsic. (See GLSL and modern instruction sets)
-Min/max:
| < > |
-Dot:
-Cross product: ><
-Swizzle: a.3.2.1.0
-Qualifiers for warping behavior.
-Standard library with cash management hints.
-Define qualifiers for padding of structs to be defined.
I would also argue you could change some things in the spec to make it easier for compilers to optimize, like making the calling a switch without a catching case undefined behavior.
As for the syntax itself, I could find being able to type multiple break commands in a row to get out of more then one loop useful, but its not a big thing.
I would probably drastically restrict the power of the pre-processor too. ...
karlding 50 days ago [-]
Peter Buhr also teaches CS 343: Concurrent and Parallel Programming [0] at the University of Waterloo in a dialect of C++ that he has been working on [1], called uC++ [2].
[0] https://www.student.cs.uwaterloo.ca/~cs343/
[1] https://github.com/pabuhr/uCPP
[2] https://en.wikipedia.org/wiki/%CE%9CC%2B%2B
BruceIV? 50 days ago [-]
[on the Cforall team] One of our Master's students has incorporated the majority of the uC++ features into Cforall as well, with some neat extensions for multi-monitor locking in a way that doesn't introduce synchronization deadlocks not present in user code.
flohofwoe 50 days ago [-]
IMHO there are better proposals for a "better C" language which fix some of the shortcomings of original C:
As long as the language is small and has good tooling, and (most importantly) can easily interoperate with C libraries (have a look at Nim for an really awesome C integration), it doesn't matter whether it is backward compatible with C.
C itself should stay what it is. A low level and simple language without surprises which is only very slowly and carefully extended. Languages that are developed "by committee" and add lots of new features quickly are usually also quickly ruined.
earenndil 49 days ago [-]
I've written in the past about C2[1]. Nim is aimed at bit of a higher level than a "c replacement" should. I don't really know much about zig, but from what I do know, I like it.
1: https://www.reddit.com/r/programming/comments/7ugm8e/c2_c_wi... https://www.reddit.com/r/programming/comments/7ugm8e/c2_c_with_cleaner_syntax_a_module_system_no/dtlz4k9/
astrodust 49 days ago [-]
The biggest problem with C is not the language but the fact that the C standard library is so anemic. Where's the "Boost" for C?
> The ability to write generic reusable programs, called polymorphism, is fundamental to advanced software engineering. I am interested in static type-systems providing polymorphism without the use of subtyping. The problem with subtyping is that it imposes significant restrictions on reuse when static type-checking is required. This work has resulted in a new dialect of C language, called Cforall, which adds parametric polymorphism and extensive overloading to provide a more general type-system.
enriquto 49 days ago [-]
A beautiful, and simple, addition to the C language would be a mechanism to assess the remaining stack size. This is trivial to check in assembler, but practically impossible in portable C.
Indeed, thanks to VLA, the stack can be used as a clean notation for raii. You just replace this ugly, but very common, construction
void f(int n)
{
float *x = malloc(n * sizeof*x);
// ...
free(x);
}with this
void f(int n)
{
float x[n];
// ...
}BruceIV? 49 days ago [-]
[on the Cforall team] we actually take advantage of this same VLA idiom for temporary storage for polymorphic variables.
Fun fact from when we switched our implementation to use VLAs: if you call alloca() for stack memory instead, it doesn't work properly inside a loop, because it never releases the memory until the stack frame is exited.
pjmlp 48 days ago [-]
VLAs were made optional in C11 as they became yet another security exploit vector, and not all C vendors are keen in supporting it, especially on the embedded space.
luckydude 49 days ago [-]
Hmm, we took a different approach, here's my C-like dialect (built on Tcl's byte codes so it co-exists with Tcl code. And yes, I know, but we needed Tk so were stuck with Tcl).
Stuff that I'd like to C in an evolved C:
regexp engine as part of the language so you can do
while (buf = <>) if (buf =~ /some regexp/) puts(buf);
<> and <FD> from perl, just handy.
Lists as a built in, with any element type and builtins like push, pop, shift, unshift, etc. Again, more perl goodness without all the @'s and $'s.
${expr} interpolation inside strings. Like shell, and it's handy.
At this point I'm just typing in the L language docs, so most of the stuff here:
http://www.little-lang.org/little.html
BTW - the logo for the language is a tip of the hat to the things that inspired it: the Tcl feather logo, the Perl camel logo, and "C" all bunched together. I'm very fond of that logo but not sure that anyone but me gets it.
js8 50 days ago [-]
Not bad, but not much to call home about either.
Personally, I would like to see better support for immutability/purity and more first-class functions (does C still insists on functions to be global in scope?).
Also, I think user-defined constructors/destructors are a bad idea. I generally found that any side effects that are done in constructors and destructors are a nasty source of bugs. It's almost always better to use a factory method (function), which makes user-defined constructor/destructor useless as a concept.
jcelerier 50 days ago [-]
> It's almost always better to use a factory method (function), which makes user-defined constructor/destructor useless as a concept.
well, no. In languages with constructors, you can enforce invariants in your class and ensure that no object that does not respect the invariants exists in your system. If you only have factory methods, you can still construct objects "normally" then nothing prevents anyone from creating another object which does not respect them. Or you can hide your struct definition in an implementation file, but then you loose the ability to construct on the stack and have to dynamically allocate, which kills performance.
js8 50 days ago [-]
> In languages with constructors, you can enforce invariants in your class and ensure that no object that does not respect the invariants exists in your system
Actually, it's not enough. If you can mutate the class variables (attributes), then you can always create a class that doesn't have these invariants enforced. The only way that could completely prevent invariants in the class being disrespected would be to have a strong, possibly dependent, type system.
For example, consider a function (method) that takes two objects of the same class and creates another object of the same class based on the two. During the construction of the returned object, invariants can be broken, and if this function contains an error, it will return an invalid object.
This is especially problematic with the RAII pattern. Because resource acquisition can fail, you have to allow for "broken" objects to be returned, which represent the resource not being acquired. In functional programming, this is done with sum types (and in general way with Maybe, for instance).
I would say I am against RAII pattern, because it gives people a false sense of security, as you have to deal with the resource not being acquired anyway (either by returning object in incorrect state or by exception). But if you forfeit RAII, you might as well get rid of user constructors and use factory methods (and simple data constructors and sum types) everywhere for simplicity and consistency.
dragonwriter 50 days ago [-]
> Actually, it's not enough. If you can mutate the class variables (attributes), then you can always create a class that doesn't have these invariants enforced. The only way that could completely prevent invariants in the class being disrespected would be to have a strong, possibly dependent, type system.
You can completely avoid it if the invariants are expressed as validation methods, and mutation of state isn't direct but through a mechanism initially updates shadow state and guarantees that validators are run and failed validations result in both the original state being preserved and an error being signalled, and only successful validation results in state updates.
A sufficiently robust type system is superior than this kind of runtime check in all kinds of ways, but is not the only way to avoid invalid state with mutable objects.
js8 50 days ago [-]
Right. What you are talking about is essentially a dynamic dependent type system.
jcelerier 50 days ago [-]
> This is especially problematic with the RAII pattern. Because resource acquisition can fail, you have to allow for "broken" objects to be returned, which represent the resource not being acquired. In functional programming, this is done with sum types (and in general way with Maybe, for instance).
... but with RAII you can't have invalid objects (if you actually care about your invariants of course).
If you do ::
class my_positive_int {
int m_x{};
public:
my_class(int x) {
if(x < 0)
throw invariant_broken;
m_x = x;
}
int get() const { return m_x; }
void set(my_positive_int other) { m_x = other.m_x; }
};then at no point in your program, cue undefined behaviour such as reinterpreting the bytes of your class as something else, can you have a my_positive_int with x < 0.
edflsafoiewq 50 days ago [-]
Everyone wants to cripple switch by turning it into the structure variously known as cond, when, match, etc. If you can only have one, by all means, take the cond, it will be useful more often, but switch's computed goto is a very useful thing to have in reserve.
mar77i 50 days ago [-]
What's with the weird cryptic, trigraphish syntax for something common as constructors and destructors?
How are _init(struct obj o) _cleanup(sturct o) not enough? Okay, except those rare cases when you need a _new(struct obj o).
BruceIV? 50 days ago [-]
[on the Cforall team] It broadly matches our other operator-overloading syntax, where the ?'s show where the arguments go, e.g. ?+? for binary addition, ?++ for postincrement and ++? for preincrement. For something as common as constructors and destructors, a concise syntax is a desirable feature.
coldtea 49 days ago [-]
The biggest evolution for C, to cut down bugs to 1/10 would be to have a proper built-in string type -- one that easily transforms into the relevant C type, and that keeps the size.
(And maybe a vector and hashmap).
earenndil 49 days ago [-]
sds? https://github.com/antirez/sds
---
dralley 1 day ago [-]
counterexample: RedoxOS?
Although it's more along the lines of Plan9 - a unix-like system that ignores the bits of POSIX that really suck.
reply
---
snarfy 1 day ago [-]
You can use c++14 on embedded devices just fine, and people do.
reply
saagarjha 1 day ago [-]
You can, as long as you stay away from templates and lambdas and STL containers; in short, most of the reasons you’d use C++.
reply
aurelian15 1 day ago [-]
STL, RTTI and Exceptions should be avoided on embedded platforms (talking about 8 bit µCs here). I've extensively used both templates and lambdas on 8 bit AVRs (both the Tiny and Mega series); actually, writing templated code for µCs is a great way to avoid overhead stemming from function pointers etc. while still having well maintainable code.
---
blattimwind 1 day ago [-]
I've used nested functions more often than I'd like to admit, because dealing with insane callback-heavy APIs is made a lot easier with them.
reply
---
kerkeslager 1 day ago [-]
Also, the compare-and-set operations enabling lock-free code is pretty cool.
reply
---
hsivonen 1 day ago [-]
Considering how hard it is to write truly exception-safe C++ and considering how major C++ code bases don't allow exceptions, adding exceptions to C does not seem like a good idea.
reply
codemac 1 day ago [-]
I've always liked the idea of djb's boringcc[0], except with different definitions of undefined based on what users were using C currently with. This would allow people to "upgrade" into boringcc with their current code bases. So with a single invocation of a compiler, you couldn't use more than one set of defined undefined behaviors.
[0]: https://groups.google.com/forum/m/#!msg/boring-crypto/48qa1kWignU/o8GGp2K1DAAJ
reply
---
boringcc 12/21/15 D. J. Bernstein As a boring platform for the portable parts of boring crypto software, I'd like to see a free C compiler that clearly defines, and permanently commits to, carefully designed semantics for everything that's labeled "undefined" or "unspecified" or "implementation-defined" in the C "standard".
...
For comparison, gcc and clang both feel entitled to arbitrarily change the behavior of "undefined" programs. Pretty much every real-world C program is "undefined" according to the C "standard", and new compiler "optimizations" often produce new security holes in the resulting object code,
D. J. Bernstein xua...@gmail.com writes: > Since accessing an array out of bounds is undefined behavior in C, > wouldn't boringC need to keep track of array length at runtime?
Here's a definition that would be moderately helpful for security: any read out of bounds produces 0; any write out of bounds is ignored.
In a new language this would be a poor choice compared to auto-resizing arrays, for the same reasons that 32-bit integers are a poor choice compared to bigints. However, in a language without a clean exception mechanism, it's not clear how to handle auto-resizing failures.
There are other ways to define everything without the "out of bounds" concept: for example, one can define where variables are stored in a flat address space, and then treat all pointer operations the same way the hardware does. But the definition above is simpler and more useful.
> Doesn't this imply that it must pass array length information when > calling a function that takes an array parameter?
No. Conceptually, what one wants is a "fat pointer" that knows the start and end of the array that it came from, but this can be physically stored as
This is implemented in, e.g., the MIRO project that I linked to before.
---Dan
12/21/15 D. J. Bernstein drc...@google.com writes: > How do you feel about defining signed integer overflow as trapping, > with unsigned retaining the ring semantics? Or is that too far from > C-classic?
This is clearly too far from what programmers expect and rely on: it would break tons of existing C code.
If you're designing a new language for general-purpose usage, you should provide auto-resizing bigints, not fake "integers" with sharp edges. But my goal here isn't to design a new language; it's to provide predictable behavior for the existing C code base.
---Dan
" It's crystal clear that, for example, almost the entire code base is compatible with signed addition defining overflow the same way that every modern CPU handles it. "
---
i have nowhere else to put this:
drawkbox 5 hours ago
| parent | flag | favorite | on: Avoid Else, Return Early (2013) |
Programmers with lots of hours of maintaining code eventually evolve to return early, sorting exit conditions at top and meat of the methods at the bottom.
Same way you evolve out of one liners.
Same way comments are extra weight that should only be in public or algorithm/need to know areas.
Same way braces go on the end of the method/class name to reduce LOC.
Same way you move on from heavy OO to dicts/lists.
Same way you go more composition instead of inheritance.
Same way while/do/while usually fades away, and if needed exit conditions.
Same way you move on from single condition bracket-less ifs. (debatable but more merge friendly and OP hasn't yet)
Same way you get joy deleting large swaths of code.
and many others on and on.
Usually these come from hours of writing/maintaining code and styles that lead to bugs.
---
some things that make C99 complicated:
" Derivations from standard C
This compiler is aimed to be being fully compatible with the C99 standard, but it will have some differences:
Type qualifers make the type system ugly, and their uselessness add unnecessary complexity to the compiler (and increased compilation time): - const: The definition of const is not clear in the standard. If a const value is modified the behaviour is undefined behaviour. It seems it was defined in order to be able to allocate variables in ROM rather than error detection. This implememtation will not warn about these modifications and the compiler will treat them like normal variables (the standard specifies that a diagnostic message must be printed).
C99 allows you to define type names of function types and write something like:
int f(int (int));
Accepting function types in typenames (or abstract declarators) makes the grammar ambiguous because it is impossible to differentiate between:
(int (f)) -> function returning int with one parameter of type f
(int (f)) -> integer variable fIf you don't believe me try this code:
int f(int g()) { return g(); }
Function type names are stupid, because they are used as an alias of the function pointer types, but it is stupid that something like sizeof(int (int)) is not allowed (because here it should be understood as the size of a function), but f(int (int)) is allowed because it is understood as a parameter of function pointer type.
This complexity is not needed at all as function pointers fix all these problems without this complexity (and they are the more usual way of writing such code).
C89 allows the definition of variables with incomplete type that have external linkage and file scope. The type of the variable is the composition of all the definitions find in the file. The exact rules are a bit complex (3.7.2), and SCC ignores them at this moment and it does not allow any definition of variables with incomplete type.
If you don't believe me try this code:
struct foo x;
struct foo { int i; }; "
