![[Home]](http://www.bayleshanks.com/cartoonbayle.png)
" Sista is an adaptive optimizer using speculative inlining that is implemented entirely in Smalltalk, and is "live" in the system, meaning that the optimizer runs in the same run-time as the application and potentially can be interactively developed. Sista makes use of Smalltalk's support for first-class activation records (contexts), both to analyse the running system, and to allow manipulation of execution state to effect switching from unoptimized code to optimized code and back. Because Sista optimizes from bytecoded methods to bytecoded methods which are normal Smalltalk objects:
---
egeozcan 9 hours ago
I don't understand. I also like JS async/await and like JS and node in general but .NET is simply beautiful IMHO (given you are using F# or C#). Why would you rather not write .NET code?
reply
189723598 6 hours ago
c# is a great language but many people don't want to have to specify type information so often or create classes so often. Even many statically-typed languages don't require as much List<T> stuff. Also, everything outside of the language itself sucks. The frameworks, the operating system is has to run on, the community, etc.
reply
---
" So the safety aspect is nice, but to me Rust's coolest meta-feature is zero-cost abstractions.
In languages like Ruby, there is often a tension between writing/using high-level abstractions and performance.
For example, it would be nice to split up a big method into a bunch of smaller methods, but method calls aren't free; using things like each and map is nice, but they are much slower than a hand-crafted loop; Symbol#to_proc is sweet, but it comes with a pretty heavy performance penalty. "
---
http://blog.rust-lang.org/2015/05/11/traits.html
---
example of some commandline stuff we should be able to do:
---
https://github.com/BYVoid/Batsh (compiles to both Bash and Windows Batch)
BYVoid 2 days ago
I am the author of Batsh. Batsh is a toy language I developed 2.5 years ago in a hackathon. It was just for me to play with OCaml. Feel free to play with it at http://batsh.org/.
reply
thinkpad20 2 days ago
The idea is interesting, but ultimately the utility of this seems limited. The differences between windows and Unix are more than just the shell language involved; shell scripts are typically deeply intertwined with the system in question, to the point where it's often not the case that a bash script will even run reliably across different Unix systems, much less on windows. Also, you can already run bash on windows, so once again the problem doesn't seem to be the language per se. I can only imagine how difficult it would be not just to design a script that would work properly on both platforms, but to debug the cases where it didn't.
Also, as others have noted this language doesn't support redirection, which in my mind makes it practically useless beyond toy applications. I've written hundreds of bash scripts and I don't think any of them didn't make heavy use of pipes and redirection. I'm also not sure if the language supports running processes in the background, traps, magic variables like $!, extra options, subshells, file globbing, etc, all things that many real-world scripts use. Bash scripts often use many programs available on Unix systems as well, such as find, grep, readlink, xargs, and other things that aren't part of the language per se. Unless those are ported over too, writing useful scripts would be almost impossible.
Finally, I don't think the author has made a convincing argument that such a language is even needed, when languages like perl/python/ruby exist for when the task is complex enough to require a more powerful language. On the other hand, if the project is (as I suspect) purely for fun and interest, then by all means :)
reply
deevus 2 days ago
Powershell _is_ great (I help run an OSS project written in Powershell), but it has a long start-up time. If you're doing it as a pre-build step for example, you don't want to add potentially seconds (!) to your build just to use powershell.
reply
stinos 2 days ago
Do you use -noprofile? (you probably should for build steps, or else make sure all your build environments have a similar profile to yours) Then the startup time is usually much better - at least I haven't seen it going over some 100s of mSec.
reply
---
http://norvig.com/design-patterns/design-patterns.pdf
---
this guy summarizes what the improvements were of various languages and states es opinion that we have long past the point of diminishing returns:
http://blog.cleancoder.com/uncle-bob/2016/05/21/BlueNoYellow.html
the improvements he states (noting that the ones mentioned first/in the earlier languages he considers very significant, and the ones mentioned later insignificant):
assembler over machine language: " the assembler does all the horrible clerical work for you. I mean it calculates all the physical addresses. It constructs all the physical instructions. It makes sure you don't do things that are physically impossible, like addressing out of range. And then it creates an easily loadable binary output. "
fortran over assembler: "If we're talking about the 1950s, Fortran was a pretty simple language back then. I mean, it was hardly more than a symbolic assembler for symbolic assembly -- if you catch my meaning."
C over fortran: " C does save a bit of clerical work over Fortran. With that old Fortran you had to remember things like line numbers, and the order of common statements. You also had rampant goto statements all over the place. C is a much nicer language to program in than Fortran 1. I'd say it might reduce the workload by 20%. "
reduction in wait time due to PCs: "in the 1950s we were using punched cards and paper tapes. Compiling a simple program took half an hour at least. And that's only if you could get access to the machine. But by the late 1980s, when C++ was becoming popular, programmers kept their source code on disks, and could compile a simple program in two or three minutes."
C++: "the object-oriented features of C++, specifically polymorphism, allowed large programs to be separated into independently developable and deployable modules. "
java over c++: "Java is a simpler language. It has garbage collection. It doesn't have header files. It runs on a VM. There are lots of advantages. (And a few disadvantages.)"
ruby over java: "Ruby is a really nice language. It is both simple, and complex; both elegant and quirky. It's dog slow compared to Java; but computers are just so cheap that...the major workload that Ruby reduces over a language like Java is Types. In Java you have to create a formal structure of types and keep that structure consistent. In Ruby, you can play pretty fast and loose with the types...that's offset by the fact that playing fast and loose with the type structure leads to a class of runtime errors that Java programmers don't experience. So, Ruby programmers have a bigger test and debug overhead..." but overall e thinks Ruby is faster
"when the compile time ((is)) effectively zero it encourages a different programming style and discipline." as is the case with Smalltalk back in the day, and pretty much every language now
clojure over ruby "because it's so simple, and because it's functional."
The top comments in the HN discussion largely agree FOR GENERAL PURPOSE, but then say that for any particular purpose, choice of language matters alot. Examples:
"I agree. The (fictional?) person asking the questions was asking for universal productivity improvements, and I think we are long past that point. There are essentially no scenarios where programming in assembly is more productive than programming in C, but those kinds of open/shut comparisons don't work well for the long-tail environment that we live in now. People are building new languages to solve specific types of problems better."
" For example, Erlang is great when you need to do lots of concurrent operations with guarantees about safety and uptime, but not really what I'd write a CSV parsing program or email client in.
C is very easy to link against on almost every platform and language, so basic libraries are often written in C.
Javascript (in the form of nodejs) is great for writing simple web servers because most of its standard library is asynchronous by default. Compare Python (with Tornado or similar) where lots of popular libraries cannot easily be used in an event loop.
I could go on forever, and you might disagree with me about a particular details, but the general point stands. If you took an expert Erlang programmer and gave her a day to write a spreadsheet application, you'd get a worse result than the same day spent by a C# programmer. "
"SQL"
"...Have fun with your ruby pacemaker, js air traffic control and life without static typing in 10mioLOC codebases...."
But then some lower-voted comments simply disagree, and feel that recent new languages offer more gains than the original article estimated.
---
donaldball • a day ago
I left ruby for clojure a few years ago and have rarely looked back. I don't think clojure will be my last language, but it has opened my eyes to new ways of doing things. In particular, I don't think I will ever write anything of more than moderate complexity in a language that doesn't feature immutable data structures as a ubiquitous idiom.
Looking back though, the thing that impedes ruby and rails most significantly is the lack of first-class support for abstractions like clojure's protocols. In ruby, discipline and duck typing are just about all you have.
...
Curt Sampson donaldball • 18 hours ago
Yeah, immutable data structures turned out to be a huge win when I moved from Ruby to Haskell back around 2008. Here are, in order, what I think were the biggest wins:
1. A powerful type system. This is by far the biggest win because, as I mention in another comment below, it's done more than anything else not just to increase reliability, but massively reduce the amount of code I write and make what I do write far easier to understand. Ruby programmers were definitely on to something with the idea of "duck typing"; in Haskell something akin to that but statically checked ("classes", which are not the same thing as OO "classes") is the core of abstraction. Algebraic data types change your life in the way that immutability (below) does; they're another thing that provide far more value than you'd see at first glance. Beyond these two things is what you might call the "programmability" of the type system: roughly, it's an actual language, not just a way of tagging things.
2. Immutable data structures throughout. This is one of those things that it sounds as if you can live without until you find out what a life change it is. So many problems and concerns just go away.
3. Simple, minimal and beautiful syntax. As developers our biggest activity by far is reading code, and good syntax really helps with this. Ruby's syntax is often moderately minimal and quite beautiful when used correctly and in a suitable situation, but unfortunately the overall design is extremely baroque and this far too often leads to nasty messes under the hood of many APIs. How often in Ruby have you gone and thought, "Reading the source code was by far the easiest way to understand that library?" This happens all the time to me in Haskell. (The type system contributes a lot to this, too.)
---
There are two main strategies that D3 uses to facilitate debugging.
First, whenever possible, D3’s operations apply immediately; for example, selection.attr immediately evaluates and sets the new attribute values of the selected elements. This minimizes the amount of internal control flow, making the debug stack smaller, and ensures that any user code (the function you pass to selection.attr that defines the new attribute values) is evaluated synchronously.
This immediate and synchronous evaluation of user code is in contrast to other systems and frameworks, including D3’s predecessor Protovis, that retain references to your code and evaluate them at arbitrary points in the future with deep internal control flow. I talk about this a bit in the D3 paper (and the essay I linked above): http://vis.stanford.edu/papers/d3 Even in the case of transitions, which are necessarily asynchronous, D3 evaluates the target values of the transition synchronously, and only constructs the interpolator asynchronously.
Second, and more obviously, D3 uses the DOM and web standards. It doesn’t introduce a novel graphical representation. This means you can use your browsers developer tools to inspect the result of your operations. Combined with the above, it means you can run commands to modify the DOM in the console, and then immediately inspect the result. D3’s standards-based approach has also enabled some interesting tools to be built, like the D3 deconstructor: https://ucbvislab.github.io/d3-deconstructor/
reply
---
antirez 1 day ago
Hello pathsjs,
well first of all, one thing is that I make efforts towards a goal, another thing is to reach it. In your analysis I don't reach the goal of simplicity, but I can ensure you I really try hard.
Now more to the point, I still think Redis is a simple system:
> one thing that Redis does not have is a coherent API.
Unfortunately coherence is pretty orthogonal to simplicity, or sometimes there is even a tension between the two. For instance instead of making an exception in one API I can try to redesign everything in more general terms so that everything fits: more coherence and less simplicity. In general complex systems can be very coherent.
Similarly the PHP standard library is extremely incoherent but is simple, you read the man page and you understand what something does in a second.
> Whenever I use Redis, I absolutely need the command cheatsheet [snip]
This actually means that Redis is very simple, in complex systems to check the command fingerprint in the manual page does not help, since it is tricky to understand how the different moving parts interact.
However it is true that in theory Redis could have more organized set of commands, like macro-type commands with sub operations: "LIST PUSH ..." "LIST POP ..." and so forth. Many of this things were never fixed because I believe that is more aesthetic than a substantial difference, and the price to pay to give coherence later is breaking the backward compatibility.
> why LPUSH accepts multiple parameters but LPUSHX does not?
Since nobody uses LPUSHX almost and is a kinda abandoned command, but this is something that we can fix since does not break backward compatibility.
> Why there is even hyperloglog in a database?
Because Redis is a data structures server and HLLs are data structures.
> Where did the need for RPUSHLPOP come from?
It is documented and has nothing to do with simplicity / coherence.
> Why the options for SCRIPT DEBUG are YES, SYNC and NO?
They have different fork behavior, as explained in the doc.
I think Redis is a system that is easy to pickup overall, but that's not the point of my blog post. However our radically different point of view on what simplicity is is the interesting part IMHO. I bet you could easily design a system that is complex for me because of, for instance, attempt to provide something very coherent, because breaking coherency for a few well-picked exceptions to the rule is a great way to avoid over-generalization.
reply
andreaferretti 15 hours ago
Hi antirez, I think we just have two opposing views about what constitutes simplicity.
I agree that Redis has the rare advantage that one can understand a command at a time, and the cheat sheet is essentially all that is needed to work with it efficiently. Many systems have a documentation that is much more involved, and in this sense Redis is simple.
Still, the reason I find it non simple is that it seems like you (or other contributors) added a random selection of data structures and operations in it. It is difficult to imagine which operations or data structures will be available without consulting the instructions. For instance, there is hyperloglog, but there are no trees or graphs, or sorted maps. And lists have LPUSHX, but no LSETX, nor there is a LLAST operation (I guess it may be for efficiency reasons, but then LINDEX has the same complexity). Sets have SUNION and SUNIONSTORE, but there is no LCONCAT or LCONCATSTORE.
Let me add an example, since I think it highlights the difference in approach we may have. I find the Scala collections very well designed and easy to work with. Each collection has essentially the same (large) set of operations, from `map` and `filter` to more sophisticated ones such as `combinations(n)` or `sliding(len, step)`. Not only that, but usually this operations will preserve the types, whenever possible. This means that, say, `map`ping over a list will produce a list, while `map`ping over a string will produce a string (if the function is char -> char) or a sequence otherwise. Similarly mapping over a bitset will produce a bitset if the function is int -> int, or a set otherwise, since bitsets only represent sets of integers. This allows me to write even very complex algorithms succintly, without needing to consult the API. I find this very simple from the point of view of the user, although the design for writers themselves is pretty complex.
On the other hand, comments such as http://stackoverflow.com/questions/1722726/is-the-scala-2-8-... prove that some other people find it complex and daunting.
In short: I find Redis easy to use (and this is one of the reasons I do use it often!), but not simple in the sense that it is easy to grasp the design.
reply
---
makecheck 1 day ago
The goal is to maximize developers’ investment. Sometimes simplicity is needed but there are other ways.
For example, consistency: it takes long enough to figure out a new module without also having to re-learn all of the things you did arbitrarily differently from the previous module. Pay attention to naming, argument order, styles of error-handling, etc. and don’t abbreviate things that are not extremely common abbreviations (e.g. "HTML" is OK; getHypTxMrkpLang() is a PITA).
Also, if you include lots of examples that obviously work then developers are more likely to trust what they see. Python "doctest" is brilliant for this, since you can trivially execute whatever the documentation claims. Don’t document the ideal world in your API: document what it actually does.
Make your API enforce its own claims in code. Don’t assume that a developer will have read paragraph 3 where it “clearly says” not to do X; instead, assert that X is not being done. This is extremely valuable to developers because then they can’t do what you don’t expect them to do and they won’t start relying on undefined or untested behavior.
reply
---
scaleout1 13 hours ago
As someone who has used Heron (along with MillWheel?, Spark Streaming and Storm) I feel like this announcement is too late. The biggest thing Heron offer is raw scale but since they decided to use existing Storm API, it has the same shitty spout /bolt API that Storms offer. In contrast, Spark streaming/Flink/ Kafka Streaming are all offering map/flatmap/filter/sink based functional API. At twitter most teams used SummingBird? on top of Heron to get the same functional API but summingbird didnt get a lot of traction outside twitter and I am not sure how actively maintained OSS version of summingbird is. Even if you bite the bullet and decide to use SB with Heron, you will still miss out on a lot of usecases as SB was mostly focused on doing read/transform/aggregate/write whereas most streaming problem that i have noticed outside of twitter involve doing read/transform/aggregate/decision/write. I suppose you can implement decisioning in SB but i havent seen it done.
Comparing Heron to google millwheel is interesting because of the design choices they made. Heron support at least one and at most once message guarantees but at Twitter most job ran with acked turned off so it was at most once with acknowledged data loss ( they had a batchjob doing mop up work to pick up missing data). Google on the other hand implemented exactly once semantic by doing idempotent sinks/ watermarking and managing out of order messages plus deduping support. Since both Flink and Spark will be implementing Apache Beam (millwheel's predecessors) model, only reason I see someone picking heron instead of Flink/Spark is that they are operating at massive scale that flink/spark dont support yet
reply
eldenbishop 13 hours ago
Storm is a low level system for managing (optionally) transactional multi-machine tasks. It makes no assumptions about what is being processed (ie. analytics, data transforms). The primitives you are talking about exist in the child project Trident which runs on top of storm. Storm itself is no more for analytics than a web-server. It is a lower level tool.
reply
weego 12 hours ago
The parent also ignored the time-to-process difference which is drastically lower in storm. It has its flaws but scale is not the only metric to use as a decider
reply
RBerenguel 12 hours ago
I had a look at the open source SummingBird? as a possible way to implement a (soft) real time project I have, because I'm not specially Java-ish and Storm does not seem to play that nice with Scala (I've been told it works decently with Clojure, though, that might have been a solution to my non-Javaness) and it looked somewhat stale.
Ditched it and decided to do it in Spark with Scala (making it a good excuse to learn Scala). With so many real time options popping up and around, deciding which to pick is getting harder and harder.
reply
heavenlyhash 7 hours ago
Thank you for this comment. It contained orders of magnitude more useful information about the API choices and data models that define this system than the linked article itself.
reply
jsmthrowaway 9 hours ago
> they are operating at massive scale that flink/spark dont support yet
Flink certainly scales just fine, for what it's worth. Flink 1.0 is quite good, and I'd consider what I'm doing "massive scale"; the ease of 1MM+ QPS with decent p95 latency via Flink surprised me compared to other systems that I investigated in this space. Most hip-fired benchmarks, including that awful Yahoo! one that everybody cites, use Flink poorly.
Rest of your comment is great and I couldn't agree more. Spot-on analysis. Twitter made a misfire here buying out Nathan Marz, neglecting Storm in favor of Heron while the rest of the field advanced (notably Google's open source work and Flink), announcing Heron which is so much better but keeping it to the chest for a while, then losing out on both of their streaming engines in time. Storm and Heron both feel too little too late, particularly Storm's recent (vast) performance improvements which a lot of folks I know kinda shrugged at and which is kinda too bad.
The Dataflow/Beam/Flink stuff is the compelling horse right now, to me. Just my personal opinion.
reply
---
in the context of a plan9 discussion:
"Unix wrinkles: there are so many, but just consider the sockets interface. Sockets completely break the Unix model of named entities that you can open and close and read and write. Sockets don't have names and are not visible in the file system. It's a long list of what they got wrong and that's why, in 1978, other mechanisms were proposed (if you're willing to dig you can find the RFC and you'll see ideas like /dev/tcp/hostname and so on). But to our dismay (I was there at the time) the current BSD socket interface won. Many of us were disappointed by that decision but it was the fastest way to get network support into Unix."
---
random semiinteresting posts about Rust on ARM MCUs:
kam 11 hours ago
| parent | flag | on: Why is a Rust executable large? |
I've used Rust on a variety of ARM Cortex-M based microcontrollers including Atmel SAMD21, NXP LPC1830, and STM32F4. AVR is tougher because that's an 8-bit architecture with very new support in LLVM.
On microcontrollers, you use libcore instead of the full libstd, for lack of an OS or memory allocator. Libcore is easy to cross compile because it has no dependencies. You provide a target JSON file to specify LLVM options, and a C toolchain to use as a linker, and nightly rustc can cross-compile for platforms supported by LLVM.
https://github.com/hackndev/zinc is a good starting point.
Things like interrupt handlers and statically-allocated global data require big chunks of unsafe code. Rust has a promising future in this space, but it will take more experimentation to get the right abstractions to make microcontroller code more idiomatic.
and Rust with low binary sizes:
https://lifthrasiir.github.io/rustlog/why-is-a-rust-executable-large.html
---
https://news.ycombinator.com/item?id=11823274 contrasts a few variant syntaxes for Promises, async/await:
the article gives this syntax for Promises:
export default function getUsers () {
return new Promise((resolve, reject) => {
getUsers().then(users => {
filterUsersWithFriends(users)
.then(resolve)
.catch((err) => {
resolve(trySomethingElse(users));
});
}, reject)
});
}compared to this for async/await:
export default async function getLikes () { const users = await getUsers(); const filtered = await filterUsersWithFriends(users); return getUsersLikes(filtered); }
a commentator replied that actually the Promise syntax would only require:
export default function getUsers () {
return getUsers().then(users => {
return filterUsersWithFriends(users)
.catch(err => trySomethingElse(users));
});
}or, as a one-liner:
export default function getUsers () {
return getUsers().then(users => filterUsersWithFriends(users).catch(err => trySomethingElse(users)));but some replies say that isn't right: https://news.ycombinator.com/item?id=11824528
see also stackoverflow.com/questions/23803743/what-is-the-explicit-promise-construction-antipattern-and-how-do-i-avoid-it/23803744#23803744
another commentator provided a macro-using js library, cspjs, which does async/await with the following syntax:
task getUsersWithFriends() {
users <- getUsers();
catch (e) {
return trySomethingElse(users);
}
// Everything below is protected by the catch above.
withFriends <- filterUsersWithFriends(users);
return withFriends;
}---
The https://github.com/srikumarks/cspjs aync/await js library allows you to retry "the operation from within catch clause (ex: exponential backoff)".
It also "propagates errors to nodejs style callbacks automatically", and removes the need for "overheads like "promisifyAll"".
Implemented using sweetjs macros.
---
artursapek 9 hours ago
You can use async/await to implement a Mutex in ES6! It's crazy.
https://gist.github.com/artursapek/70437f6cdb562b7b62e910fd3...
Usage:
import Mutex from 'lib/mutex';
class MyObject {
constructor() {
this.m = new Mutex();
} async someNetworkCall() {
let unlock = await this.m.lock(); doSomethingAsynchronous().then((result) => {
// handle result
unlock();
}).catch((err) => {
// handle error
unlock();
});
}
} let mo = new MyObject();
mo.someNetworkCall();
// The next call will wait until the first call is finished
mo.someNetworkCall();I love it. We use it in our production codebase at Codecademy.
reply
peterjuras 9 hours ago
You can use the await keyword multiple times, and therefore make it easier to handle the error with try catch:
async someNetworkCall() {
let unlock = await this.m.lock(); try {
const result = await doSomethingAsynchronous();
// handle result
} catch (exception) {
// handle error
}
unlock();
}reply
---
" ...((if a)) kernel doesn't restore caller-saved registers at syscall exit? This seems extraordinary, because unless it either restores them or zaps them then it will be in danger of leaking internal kernel values to userspace - and if it zaps them then it might as well save and restore them, so userspace won't need to.
reply "
---
> The real NtQueryDirectoryFile? API takes 11 parameters
Curiosity got the best of me here: I had to look this up in the docs to see how a linux syscall that takes 3 parameters could possibly take 11 parameters. Spoiler alert: they are used for async callbacks, filtering by name, allowing only partial results, and the ability to progressively scan with repeated calls.
reply
bitwize 21 hours ago
This is a recurring pattern in Windows development. Unix devs look at the Windows API and go "This syscall takes 11 parameters? GROAN." But the NT kernel is much more sophisticated and powerful than Linux, so its system calls are going to be necessarily more complicated.
reply
trentnelson 19 hours ago
Curiosity got the better of me recently when I re-read Russinovich's [NT and VMS - The Rest Of The Story](http://windowsitpro.com/windows-client/windows-nt-and-vms-re...), and I bought a copy of [VMS Internals and Data Structures](http://www.amazon.com/VAX-VMS-Internals-Data-Structures/dp/1...).
Side-by-side, comparing VMS to UNIX, and VMS's approach to a few key areas like I/O, ASTs and tiered interrupt levels are simply just more sophisticated. NT inherited all of that. It was fundamentally superior, as a kernel, to UNIX, from day 1.
I haven't met a single person that has understood NT and Linux/UNIX, and still thinks UNIX is superior as far as the kernels go. I have definitely alienated myself the more I've discovered that though, as it's such a wildly unpopular sentiment in open source land.
Cutler got a call from Gates in 89, and from 89-93, NT was built. He was 47 at the time, and was one of the lead developers of VMS, which was a rock-solid operating system.
In 93, Linus was 22, and starting "implementing enough syscalls until bash ran" as a fun project to work on.
Cutler despised the UNIX I/O model. "Getta byte getta byte getta byte byte byte." The I/O request packet approach to I/O (and tiered interrupts) is one of the key reasons behind NT's superiority. And once you've grok'd things like APCs and structured exception handling, signals just seem absolutely ghastly in comparison.
reply
jen20 18 hours ago
I've never met a single person who understood what they were talking about and referred to a "UNIX kernels". It may be true that Linux was once less advanced than NT - this is no longer the case, despite egregious design flaws in things like epoll. It has simply never been true (for example) for the Illumos (nee Solaris) kernel.
reply
ambrop7 10 hours ago
Which design faults do you think epoll specifically has?
I know there are lots of file descriptors not usable with epoll or rather async i/o in general and that sucks (e.g. regular files).
For networking, I find epoll/sockets nicer to work with than Windows' IOCP, because with IOCP you need to keep your buffers around until the kernel deems your operation complete. I think you have 3 options:
1) Design the whole application to manage buffers like IOCP likes (this propagates to client code because now e.g. they need to have their ring buffer reference-counted).
2) You handle it transparently in the socket wrapper code by using an intermediate buffer and expose a simple read()/write() interface which doesn't require the user to keep a buffer around when they don't want the socket anymore.
3) You handle it by synchronously waiting for I/O to be cancelled after using CancelIo?. This sounds risky with potential to lock up the application for an unknown amount of time. It's also non-trivial because in that time IOCP will give you completion results for unrelated I/Os which you will need to buffer and process later.
On the other hand, with Linux such issues don't exist by design, because data is only ever copied in read/write calls which return immediately (in non-blocking mode).
reply
geocar 9 hours ago
The cool thing is that by gifting buffers to the kernel as policy, the gets to make that choice.
In Linux, you don't, and userspace and kernelspace both end up doing unnecessary copying, and it means with shared buffers, something might poll and not-block, but actually block by the time you get around to using the buffer.
This is annoying, and it generally means you need more than two system calls on average for every IO operation in performance servers.
As a rule, you can generally detect "design faults" by the number of competing and overlapping designs (select, poll, epoll, kevent, /dev/poll, aio, sigio, etc, etc, etc). I personally would have preferred a more fleshed out SIGIO model, but we got what we got...
One specific fault of epoll (compared to near-relatives) is that the epoll_data_t is very small. In Kqueue you can store both the file descriptor with activity (ident) as well as a few bytes of user data. As a result, people use a heap pointer which causes an extra stall to memory. Memory is so slow...
reply
ambrop7 6 hours ago
> something might poll and not-block, but actually block by the time you get around to using the buffer
On Linux if a socket is set to non-blocking it will not block. I don't really understand your point with shared buffers. You wouldn't typically share a TCP socket since that would result in unpredictable splitting/joining of data.
> In Linux, you don't, and userspace and kernelspace both end up doing unnecessary copying
I'm not so sure the Linux design where copies are done in syscalls must be inherently less efficient. I'm pretty sure with either design, you generally need at least one memcpy - for RX, from the in-kernel RX buffers to the user memory, and for TX, from user memory to the in-kernel TX buffers. I think getting rid of either copy is extremely hard and would need extremely smart hardware, especially the RX copy (because the Ethernet hardware would need to analyze the packet and figure out where the final destination of the data is!). Getting rid of TX copy might be easier but still hard because it'd need complex DMA support on the Ethernet card that could access potentially unaligned memory addresses. On the other hand, I also don't think you need more than one copy, if you design the network stack with that in mind.
> you need more than two system calls on average for every IO operation in performance servers.
True but it's not obvious that this is a performance bottleneck. Consider that a single epoll wait can return many ready sockets. I think theoretically it would hurt latency rather than throughput.
> As a rule, you can generally detect "design faults" by the number of competing and overlapping designs.
On Linux, I think for sockets, there are only: blocking, select, poll, epoll. And the latter three are just different ways to do the same thing. On Windows, it's much more complicated - see this list of different methods to use sockets (my own answer): http://stackoverflow.com/questions/11830839/when-using-iocp-should-i-set-wsaoverlappeds-hevent-to-null-or-to-a-valid-handl/11831450#11831450
> One specific fault of epoll (compared to near-relatives) is that the epoll_data_t is very small.
Pretty much universally when you're dealing with a socket, you have some nontrivial amount of data associated with it that you will need to access when it's ready for I/O, typically a struct which at least holds the fd number. Naturally you put a pointer to such a struct into the epoll_data_t. I don't see how one could do it more efficiently outside of very specialized cases.
reply
geocar 6 hours ago
> I'm not so sure the Linux design where copies are done in syscalls must be inherently less efficient.
Windows overlapped IO can map the user buffer directly to the network hardware, which means that in some situations there will be zero copies on outbound traffic.
> especially the RX copy I also don't think you need more than one copy, if you design the network stack with that in mind.
When the interrupt occurs, the network driver is notified that the DMA hardware has written bytes into memory. On Windows, it can map those pages directly onto the virtual addresses where the user is expecting it. This is zero copies, and just involves updating the page tables.
This works because on Windows, the user space said when data comes in, fill this buffer, but on Linux the user space is still waiting on epoll/kevent/poll/select() -- it has only told the kernel what files it is interested in activity on, and hasn't yet told the kernel where to deposit the next chunk of data. That means the network driver has to copy that data onto some other place, or the DMA hardware will rewrite it on the next interrupt!
If you want to see what this looks like, I note that FreeBSD? went to a lot of trouble to implement this trick using the UNIX file API[0]
> On Linux, I think for sockets, there are only: blocking, select, poll, epoll. And the latter three are just different ways to do the same thing.
Linux also supports SIGIO[1], and there are a number of aio[2] implementations for Linux.
epoll is not the same as poll: Copying data in and out of the kernel costs a lot, as can be seen by any comparison of the two, e.g. [3]
Also worth noting: Felix observes[4] SIGIO is as fast as epoll.
> I don't see how one could do it more efficiently
Dereferencing the pointer causes the CPU to stall right after the kernel has transferred control back into user space, while the memory hardware fetches the data at the pointer. This is a silly waste of time and of precious resources, considering the process is going to need the file descriptor and it's user data in order to schedule the IO operation on the file descriptor.
In fact, on Linux I get more than a full percent improvement out of putting the file descriptor there, instead of the pointer, and using a static array of objects aligned for cache sharing.
For more on this subject, you should see "what every programmer should know about memory"[4].
[0]: http://people.freebsd.org/~ken/zero_copy/
[1]: http://davmac.org/davpage/linux/async-io.html#sigio
[2]: http://lse.sourceforge.net/io/aio.html
[3]: 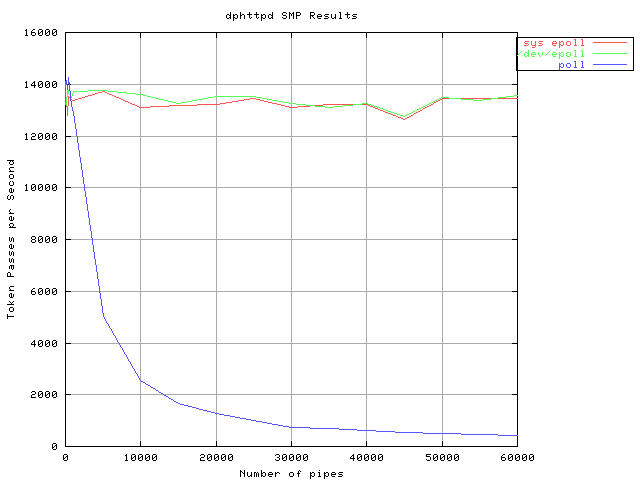
[4]: http://bulk.fefe.de/scalability/
[5]: https://www.akkadia.org/drepper/cpumemory.pdf
reply
ambrop7 4 hours ago
Thanks for the info. Yes I suppose zero-copy can be made to work but surely one needs to go through a LOT of trouble to make it work.
I'm curious about sending data for TCP through, don't you need to have the original data available anyway, in case it needs to be retransmitted? Do the overlapped TX operations (on Windows) complete only once the the data has also been acked? Are you expected to do multiple overlapped operations concurrently to prevent bad performance due to waiting for ack of pending data?
reply
geocar 3 hours ago
Windows was designed for an era where context switches were around 80µsec (nowadays they're closer to 2µsec), so a lot of that hard work has already paid for itself.
> don't you need to have the original data available anyway, in case it needs to be retransmitted? Do the overlapped TX operations (on Windows) complete only once the the data has also been acked?
I don't know. My knowledge of Windows is almost twenty years old at this point.
If I recall correctly, the TCP driver actually makes a copy when it makes the packet checksums (since you have the cost of reading the pages anyway), but I think behaviour this is for compatibility with Winsock, and it could have used a copy-on-write page, or given a zero page in other situations.
reply
trentnelson 18 hours ago
I qualified it as "Linux/UNIX kernel" because I wanted to emphasize the kernel and not userspace.
Solaris event ports are good, but they're still ultimately backed by a readiness-oriented I/O model, and can't be used for asynchronous file I/O.
reply
binarycrusader 17 hours ago
Solaris event ports most certainly can be and are used for async I/O. I'm not sure how you can claim otherwise:
https://blogs.oracle.com/dap/entry/libevent_and_solaris_even...
https://blogs.oracle.com/praks/entry/file_events_notificatio...
And Solaris, (unlike Linux historically at least), supports async I/O on both files and sockets. Linux (historically) only supported it for sockets. I have no idea if Linux generally supports async I/O for files at this point.
reply
trentnelson 16 hours ago
Let me rephrase it: there is nothing on any version of UNIX that supports an asynchronous file I/O API that integrates cleanly with the file system cache -- you can do signal based asynchronous I/O, but that isn't anywhere near as elegant as having a single system call that will return immediately if the data is available, and if not, sets up an overlapped operation and still returns immediately to the caller.
This isn't a terrible recap of async file I/O issues on contemporary operating systems: http://blog.libtorrent.org/2012/10/asynchronous-disk-io/
wahern 15 hours ago
They're called threads. Overlapped I/O on Windows is based on a thread pool, which is why you can't cancel and destroy your handle whenever you want--a thread from the pool might be performing the _blocking_ I/O operation, and in that critical section there's no way to wake it up to tell it to cancel. Just... like... on... Unix.
The difference between Windows Overlapped I/O and POSIX AIO is that on Windows it's a black box, so people can pretend it's magical. Whereas on Linux there hasn't been interest (AFAIK) to merge patches that provide a kernel-side pool of threads for doing I/O, and the decades-long debates have spilled out onto the streets. If you view userspace code as somehow inelegant or fundamentally slow, then of course all the blackbox Windows API and kernel components look appealing. What has held Linux back regarding AIO is that Linux (and Unix people in general) have historically preferred to keep as much in userspace as possible.
This is why NT has syscalls taking 11 parameters. In the Unix world you don't design _kernel_ APIs that way, or any APIs, generally. In the Unix world you prefer simple APIs that compose well. read/write/poll compose much better than overlapped I/O, though which model is most elegant and useful in practice is highly context-dependent. As an example, just think how you'd abstract overlapped I/O in your favorite programming language. C# exposes overlapped I/O directly in the language, but doing so required committing to very specific constructs in the language.
As for performance, both Linux and FreeBSD? support zero-copy into and out over userspace buffers. The missing piece is special kernel scheduling hints (e.g. like Apple's Grand Central Dispatch) to optimize the number of threads dedicated per-process and globally to I/O thread pools. But at least not too long ago the Linux kernel was much more efficient at handling thousands of threads than Windows, so it wasn't really an issue. That's another thing Linux prefers--optimizing the heck out of simpler interfaces (e.g. fork), rather than creating 11-argument kernel syscalls. IOW words, make the operation fast in all or most cases so you don't need more complex interfaces.
reply
bitwize 14 hours ago
The difference between Windows Overlapped I/O and POSIX AIO is that on Windows it's a black box, so people can pretend it's magical.
No. The difference is that in Windows you can check for completion and set up an overlapped I/O operation in one system call. Requiring multiple system calls to do the same thing means more unnecessary context switches, and the possibility of race conditions especially in multithreaded code. That and, as trentnelson stated, the Windows implementation is well integrated with the kernel's filesystem cache. Linux userspace solutions? Hahaha.
Supplying this capability as a primitive rather than requiring userland hacks is the right way to do it from an application developer's perspective.
reply
adamnemecek 16 hours ago
...
Also do you have an opinion on BeOS??
reply
trentnelson 16 hours ago
I was fascinated by BeOS? in the late 90s when I had a lot of enthusiasm (and little clue). All their threading claims just sounded so cool. I was also really into FreeBSD? from around 2.2.5 so I got to see how all the SMPng stuff (and kqueue!) evolved, as well as all the different threading models people in UNIX land were trying (1:1, 1:m, m:n).
NT solves it properly. Efficient multithreading support and I/O (especially asynchronous I/O) are just so intrinsically related. Trying to bend UNIX processes and IPC and signals and synchronous I/O into an efficient threading implementation is just trying to fit a square peg in a round hole in my opinion.
...
reply
bitwize 20 hours ago
Actually it does, as it mentioned that the extra parameters are for things like async callbacks and partial results.
The I/O model that Windows supports is a strict superset of the Unix I/O model. Windows supports true async I/O, allowing process to start I/O operations and wait on an object like an I/O completion port for them to complete. Multiple threads can share a completion port, allowing for useful allocation of thread pools instead of thread-per-request.
In Unix all I/O is synchronous; asynchronicity must be faked by setting O_NONBLOCK and buzzing in a select loop, interleaving bits of I/O with other processing. It adds complexity to code to simulate what Windows gives you for real, for free. And sometimes it breaks down; if I/O is hung on a device the kernel considers "fast" like a disk, that process is hosed until the operation completes or errors out.
reply
piscisaureus 18 hours ago
I wrote the windows bits for libuv (node.js' async i/o library), so I have extensive experience with asynchronous I/O on Windows, and my experience doesn't back up parent's statement.
Yes, it's true that many APIs would theoretically allow kernel-level asynchronous I/O, but in practice the story is not so rosy.
IMO the Windows designers got the general idea to support asynchronous I/O right, but they completely messed up all the details.
reply
trentnelson 16 hours ago
I didn't make my point particularly well there to be honest. Writing an NT driver is incredibly more complicated than an equivalent Linux one, because your device needs to be able to handle different types of memory buffers, support all the Irp layering quirks, etc.
I just meant that writing an NT kernel driver will really give you an appreciation of what's going on behind the scenes in order to facilitate awesome userspace things like overlapped I/O, threadpool completion routines, etc.
reply
4ad 7 hours ago
> Write a kernel driver on Linux and NT and you'll see how much more superior the NT I/O subsystem is.
I wrote Windows drivers and file systems for about 10 years, and Unix drivers and file systems also for about 10 years.
I'd rather practice substance agriculture for the rest of my life than deal with Windows drivers again.
reply
trentnelson 4 hours ago
Yeah it's not a simple affair at all. It's a lot easier these days though, and the static verifier stuff is very good.
reply
SwellJoe? 19 hours ago
I have never worked with systems-level Windows programming, so I don't know the answer to this...but, how is what you're describing better than epoll or aio in Linux or kqueues on the BSDs?
I'm guessing you're coming from the opposite position of ignorance I am (i.e. you've worked on Windows, but not Linux or other modern UNIX), though, since "setting O_NONBLOCK and buzzing in a select loop, interleaving bits of I/O with other processing" doesn't describe anything developed in many, many years. 15 years ago select was already considered ancient.
reply
MarkSweep? 18 hours ago
I think IO Completion Ports [1] in Windows are pretty similar to kqueue [2] in FreeBSD? and Event Ports [3] in Illumos & Solaris. All of them are unified methods methods for getting change notifications on IO events and file system changes. Event Ports and kqueue also handle unix signals and timers.
Windows will also take care of managing a thread pool to handle the event completion callbacks by means of BindIoCompletionCallback? [4]. I don't think kqueue or Event Ports has a similar facility.
[1]: https://msdn.microsoft.com/en-us/library/windows/desktop/aa3... [2]: https://www.freebsd.org/cgi/man.cgi?query=kqueue&sektion=2 [3]: https://illumos.org/man/3C/port_create [4]: https://msdn.microsoft.com/en-us/library/windows/desktop/aa3...
reply
trentnelson 18 hours ago
BindIoCompletionCallback? is very old, the new threadpool APIs should be used, e.g.: https://github.com/pyparallel/pyparallel/blob/branches/3.3-p...
Regarding the differences between IOCP and epoll/kqueue, it all comes down to completion-oriented versus readiness-oriented.
https://speakerdeck.com/trent/pyparallel-how-we-removed-the-gil-and-exploited-all-cores?slide=52
reply
((from that link:)) readiness-oriented (UNIX approach):
Is this ready to write yet? No? How about now? Still no? Now? Yes!? Really? Ok, write it! Hi! Me again. Anything to read? No? How about now?
completion-oriented (windows approach): here, do this. Let me know when it's done.
dblohm7 12 hours ago
Last decade I wrote a server based on the old API and BindIoCompletionCallback?. I can't comment on the performance differences, but the newer threadpool API is much better to work with.
IMO one of the biggest problems with the old API is that there is only one pool. This can cause crazy deadlocks due to dependencies between work items executing in the pool. The new API allows you to create isolated pools.
The old API did not give you the ability to "join" on its work items before shutting down. You could roll your own solution if you knew what you were doing, but more naive developers would get burned.
You also get much finer grained control over resources.
reply
trentnelson 19 hours ago
To quote myself:
> The “Why Windows?” (or “Why not Linux?”) question is one I get asked the most, but it’s also the one I find hardest to answer succinctly without eventually delving into really low-level kernel implementation details. >
> You could port PyParallel? to Linux or OS X -- there are two parts to the work I’ve done: a) the changes to the CPython interpreter to facilitate simultaneous multithreading (platform agnostic), and b) the pairing of those changes with Windows kernel primitives that provide completion-oriented thread-agnostic high performance I/O. That part is obviously very tied to Windows currently. >
> So if you were to port it to POSIX, you’d need to implement all the scaffolding Windows gives you at the kernel level in user space. (OS X Grand Central Dispatch was definitely a step in the right direction.) So you’d have to manage your threadpools yourself, and each thread would have to have its own epoll/kqueue event loop. The problem with adding a file descriptor to a per-thread event loop’s epoll/kqueue set is that it’s just not optimal if you want to continually ensure you’re saturating your hardware (either CPU cores or I/O). You need to be able to disassociate the work from the worker. The work is the invocation of the data_received() callback, the worker is whatever thread is available at the time the data is received. As soon as you’ve bound a file descriptor to a per-thread set, you prevent thread migration >
> Then there’s the whole blocking file I/O issue on UNIX. As soon as you issue a blocking file I/O call on one of those threads, you have one thread less doing useful work, which means you’re increasing the time before any other file descriptors associated with that thread’s multiplex set can be served, which adversely affects latency. And if you’re using the threads == ncpu pattern, you’re going to have idle CPU cycles because, say, only 6 out of your 8 threads are in a runnable state. So, what’s the answer? Create 16 threads? 32? The problem with that is you’re going to end up over-scheduling threads to available cores, which results in context switching, which is less optimal than having one (and only one) runnable thread per core. I spend some time discussing that in detail here: https://speakerdeck.com/trent/parallelism-and-concurrency-wi.... (The best example of how that manifests as an issue in real life is `make –jN world` -- where N is some magic number derived from experimentation, usually around ncpu X 2. Too low, you’ll have idle CPUs at some point, too high and the CPU is spending time doing work that isn’t directly useful. There’s no way to say `make –j[just-do-whatever-you-need-to-do-to-either-saturate-my-I/O-channels-or-CPU-cores-or-both]`.) >
> Alternatively, you’d have to rely on AIO on POSIX for all of your file I/O. I mean, that’s basically how Oracle does it on UNIX – shared memory, lots of forked processes, and “AIO” direct-write threads (bypassing the filesystem cache – the complexities of which have thwarted previous attempts on Linux to implement non-blocking file I/O). But we’re talking about a highly concurrent network server here… so you’d have to implement userspace glue to synchronize the dispatching of asynchronous file I/O and the per-thread non-blocking socket epoll/kqueue event loops… just… ugh. Sure, it’s all possible, but imagine the complexity and portability issues, and how much testing infrastructure you’d need to have. It makes sense for Oracle, but it’s not feasible for a single open source project. The biggest issue in my mind is that the whole thing just feels like forcing a square peg through a round hole… the UNIX readiness file descriptor I/O model just isn’t well suited to this sort of problem if you want to optimally exploit your underlying hardware. >
> Now, with Windows, it’s a completely different situation. The whole kernel is architected around the notion of I/O completion and waitable events, not “file descriptor readiness”. This seems subtle but it pervades every single aspect of the system. The cache manager is tightly linked to the memory management and I/O manager – once you factor in asynchronous I/O this becomes incredibly important because of the way you need to handle memory locking for the duration of the I/O request and the conditions for synchronously serving data from the cache manager versus reading it from disk. The waitable events aspect is important too – there’s not really an analog on UNIX. Then there’s the notion of APCs instead of signals which again, are fundamentally different paradigms. The digger you deep the more you appreciate the complexity of what Windows is doing under the hood. >
> What was fantastic about Vista+ is that they tied all of these excellent primitives together via the new threadpool APIs, such that you don’t need to worry about creating your own threads at any point. You just submit things to the threadpool – waitable events, I/O or timers – and provide a C callback that you want to be called when the thing has completed, and Windows takes care of everything else. I don’t need to continually check epoll/kqueue sets for file descriptor readiness, I don’t need to have signal handlers to intercept AIO or timers, I don’t need to offload I/O to specific I/O threads… it’s all taken care of, and done in such a way that will efficiently use your underlying hardware (cores and I/O bandwidth), thanks to the thread-agnosticism of Windows I/O model (which separates the work from the worker). >
> Is there something simple that could be added to Linux to get a quick win? Or would it require architecting the entire kernel? Is there an element of convergent evolution, where the right solution to this problem is the NT/VMS architecture, or is there some other way of solving it? I’m too far down the Windows path now to answer that without bias. The next 10 years are going to be interesting, though.
https://groups.google.com/forum/#!topic/framework-benchmarks...
reply
---
linux file system hierarchy 2.0 'essential binaries' in /bin according to
image-store.slidesharecdn.com/aefe2299-2c18-4ca2-8bb7-0f6b23bb25f1-original.png
:
cat, chgrp, chmod, chowh, cp, data, dd, df, dmesg, echo, false, hostname, kill, ln, login, ls, mkdir, mknod, more, mount, mv, ps, pwd, rm, rmdif, sed, sh, stty, su, synch, true, umount, uname
---
pretty cool that you can do this in Python to create a suspension as a 0-ary lambda fn:
(lambda: 3)() 3
---
my thoughts on Checked C ('checkedc') (see my summary in proj-plbook-plChCLang, section 'Checked C'):
CheckedC? is a an extension to C to allow explicitly specification of pointer/array bounds. In a way, this is irrelevant for Oot, because we are a HLL with an abstraction level above that of pointer arithmetic and memory management. However, it is still distantly relevant for various reasons:
So, various notes:
they have syntaxes:
x : bounds(tmp, end)
to annotate x with a statement about its bounds, and
where i >= 0
to make an 'assertion' (which is apparently different from a C assertion, but it shouldn't be in Oot imo) and
i like this language in the paper:
"For an existing C program to be correct, there has to be an understanding on the part of the programmer as to why pointers and array indices stay in range. The goals of the design are to let the programmer write this knowledge down, to formalize existing practices, such as array pointer parameters being paired with length parameters, and to check this information.". To generalize that to explain Oot's 'extensible typechecking' dreams:
"For a program to be correct, there usually has to be an understanding of various conditions and invariants. One goal of Oot to is allow the programmer to write some of this down explicitly, and to allow extensible typechecking frameworks to check it."
In the HN discussion, Rust guy pcwalton points out that in addition to bounds errors, another very common error is use-after-free (accessing deallocated memory) [2]. [3] implies that very common errors include buffer overflow (which CheckedC? is preventing), use-after-free, and and 'format string'. The paper also mentions incorrect type-unsafe pointer casts and concurrency races.
Variables which carry their bounds with them at runtime carry both a lower and an upper bound (unlike some competing projects, in which the bounds carry counts of elements).
nice list of pointer ops (the ops in this list which take two pointers require that the pointers be to objects of the same type):
const pointer to mutable value vs mutable pointer to const value: interesting distinction. Also, i guess in Oot everything is 'non-local const' by default (eg you can do x = 3; x = 4; but if you are a function that was passed a pointer to a struct, you can't modify an element of that struct unless your signature indicated that you wanted to mutate that argument)?
the 'non-modifying expressions' for bounds, as well as the discussion on undefinedness/unspecifiedness of assignments and side-effects within expressions, provides evidence in favor of a separation between expressions and statements (and functions and procedures). Also, is control flow allowed within the non-modifying bounds expressions? i didn't see any 'if's but i think they did allow subroutine calls? todo check.
he says that he likes "ptr<const unsigned int> g" over "const unsigned int ptr" because it's easier to visually parse, which i should think about b/c currently we're heading for something more like the latter.
a Maybe-like bounds construct was rejected for C compatibility. Oot prefers Maybe.
in Lessons in the paper, they say that most of the time, bounds checks are only needed at variable declarations. In 11.4 of the paper, they say that the reason for including the option of attaching bounds to variable assignments, in addition to just the variable declaration, is to avoid having to split one variable with changing bounds into many variables with fixed bounds, which it sounds like he dislikes because it requires C code to be changed more than just adding bounds annotations. I dont think this is worth the complexity of introducing dataflow ('flow-sensitive bounds'), and in any case we dont have his requirement of making it easy to make existing C code safe by adding minimal annotations.
like Rust, this language annotates lexical scopes according to whether they are safe. Oot annotations must be able to annotate scopes, in addition to values, and in addition to variables (are all three of these really needed/separate?).
They have the expected division where anything that can be statically checked is, and other things require dynamic checks; and like Milewski's system, they have a third category, pointers that just can't do pointer arithmetic at all; and also a fourth, places where the programmer makes an assertion and is trusted. So this is all in line with my plans for type assertions.
It's interesting that they found that the complexity of alignment constraints was worth it for performance.
interesting list of undefined/unspecified/implementation depedendent stuff:
and how they make some undefined stuff more defined:
interesting discussion supporting null pointers and assertions, interesting b/c it supports them, as opposed to the 'billion dollar mistake' narrative. The reason is that explicitly handling errors is cumbersome and inefficient, which is annoying when the error can never happen. I think for Oot the implication is, asserts are for when YOU are sure that YOUR OWN code is correct; but use ordinary control flow and exceptions for argument-checking, eg when something bad could be caused by something outside your control.
There's inference procedures presented in Chapters 4 and 8 of [4], starting on PDF pages 57 and 107. Should make sure that Oot's extensible typechecking can express (most of) that.
i should maybe read his Related Work Chapter 9 [5] sometime.
---
