![[Home]](http://www.bayleshanks.com/cartoonbayle.png)
can we/should we allow CALL3 to have INOUT operands? 2 of them or all 3? maybe CALL3 via just pushing the 2 'input' operands onto the stack? in which case, upon return, it just POPs the stack into the 3rd operand? which would allow a function that wants 2 INOUT operands to leave results on the stack? but that would mean that CALL3 has differing stack behavior depending on what is called, which i don't like.
so i don't think i'll do that. But it's just something to think about.
i guess you could have two different CALL3 addr mode flags to have this behavior, or the normal behavior.
---
in any case, one possible implementation of CALL3 is for it to have 'arguments passed on stack' semantics, so the two input arguments are pushed onto the stack beforehand, and then afterwards the one output argument is popped from the stack and moved into the destination register.
---
macros are expanded inline; one macro which is invoked multiple times will generate multiple instances in the generated code. A label within a macro will generate a unique label for each instance of the macro.
can nested macro invocations refer to macros from outer macro invocations? If so, the compiler will have to pass in the unique label names when calling a nested macro. Perhaps you could let the user handle this by allowing labels to be assigned to variables.
better idea: if the same label is defined more than once, the most recent definition (in terms of static position in the instruction stream) overwrites the others
---
sounds related to my idea of using the extra operand to pass type info:
Tag-free garbage collection using explict tag parameters http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.53.1106&rep=rep1&type=pdf
---
so, if the number used for passing types has 8 bits, how should an 8-bit immediate 'type' in this field be defined?
8-bits surely won't be enough for all of the types we may ever need, including custom types, struct types, function types, so we can just have a subset, and we'll have to just pass a pointer to a 'type' for others even when the type being passed is statically known (and so could otherwise be an 'immediate').
maybe the largest subset (in terms of bits needed) is function types, so let's consider those first. We'd like to at least handle functions with 2 inputs and one output. The largest number that can be multiplied by 3 and still be 8 or less is 2. So, we have 6-bit immediate function types with 2 bits each for each argument and for the return value. So, for each argument and 4 the return value we can encode 4 types. I think the obvious choices are:
'nil' can be used when we have functions that have less than 2 inputs or less than one output. ('nil' can be another name for what some languages call 'unit' and represent using the literal '()', and for what some languages call 'void')
These function types occupy 64 out of the 256 possible immediate types.
Now, isn't everything really a function type? Because we'll be calling functions and passing these types for polymorphism, so it would make sense for these types to be the function types.
This suggests that we choose the other (256-64 = 192) types to just be the most commonly needed function types, similarly to the 64 8-bit instructions.
However, when we have a pointer to a constant struct representing a 'type', this must be a recursive tree, and what encoding is the leaf of that tree? May as well make this part of the encoding. Which means that we need to reserve a lot of this space for the base types.
Let's reserve a block of 64 for base types.
Now we have used 64 for the base types, and 64 for the function types, and we have 128 left. What about 3-argument functions with only 2 distinct types? Assuming we can swap the 2 arguments, there are two forms of this:
a <- f(b, b) a <- f(a, b)
Each of a and b can take 3 bits, which means that each of the two forms takes 6 bits, which means that the total takes 7 bits. Which is our remaining 128. So these functions can only access (without pointing to a larger, constant struct) the most common 8 out of the 64 base types.
I might suggest:
bool, int32, int64, uint32, uint64, f32, f64, ptr
But doesn't leave any room for: dyn, custom/obj, string.
Also, since we are now talking about the format for the entire 'type struct', not just for the immediate operand, we need a way to specify 'this is a composite type'. We could repurpose 'dynamic' for that. Alternately, we could leave all that for the 64 'base types' (after all, we also need to specify WHICH composite type we have (union or product type? or, homogenous array? hetero array? linked list? struct? tuple? discriminated union (and then: option? simple enum?)? nondiscriminated union? keyword/interned string?)). But this suggests that we really want at least 'dyn' (or whatever we replace it with) in the functions-with-two-same-argument 8 base types. So, in the 8 base types, we should probably give up one or more of:
I suggest giving up 64-bit ints (in the 8 common base types; they can still be in the 64 base types).
Also, we would like these 3-bit common types to be a superset of the 2-bit common types above. So we need nil in there.
So, the 2-bit function operand types are:
And the 3-bit common types are:
We could also consider giving up one of f32 or f64, probably f32, and putting something else in that slot, like dyn or obj (obj could simply be RESERVED or CUSTOM, so as to allow HLLs to efficiently reuse this same system and put their own thing in there, which could be an object type). Or giving up bool. Or giving up both bool and f64.
And the 64 base types must include all composite type constructors as well as actual base types.
for inspiration, maybe see also:
https://en.wikipedia.org/wiki/Comparison_of_programming_languages_(basic_instructions) https://en.wikipedia.org/wiki/Primitive_data_type https://en.wikipedia.org/wiki/Template:Programming_language_comparisons
on the question of whether f32 or f64 is more common, it's contentious: https://softwareengineering.stackexchange.com/questions/305760/why-is-the-most-common-integer-number-32-bits-but-the-most-common-floating-poin
now that i've heard of NaN? tagging, that's more ammo for me to choose f64, given that having a system which is good for implementing an HLL is part of the goal here.
yeah, i like the idea of giving up f32 and adding in either DYNAMIC (which means a type variable to be provided later), ANY (which means a boxed/self-describing type) or CUSTOM (which means the semantics of this are reserved for a HLL building on top of LOVM). Remember, the ones we don't choose here can still be in the base 64 types, we are just choosing which 8 types are available in the shortcut for functions with two operands with the same type. For now let's just say CUSTOM or, maybe better since we haven't quite decided, RESERVED.
i'm tempted to get rid of bool and have two of these choices, but i guess functions with a bool output are pretty common so we want to represent those succinctly. One goal could be for these 8 types to be able to represent every function in Boot, as well as obvious alternatives; dunno if we have any actual bools in Oot, but we do have compare-and-jumps, for which an obvious alternative would be compare (although compare could also be trinary compare, which doesn't output bool; but a compare that was exactly analogous to compare-and-jump would be binary). And we also clearly have both int32 and uint32 in Boot, because i found that i had to describe that in footnotes to some of the instructions.
so the 3-bit common types are:
Out of the 256 one-byte types, we have:
so we have 56 other types. Included in that list might be the above, plus: - f32 - int64 - uint64 - int8 - uint8 - int16 - uint16 - VARIABLE/DYNAMIC (type variable) - ANY (boxed) - unicode string (how terminated?) - bytestring (null-terminated) - bytestring (32-bit length prefixed) - bytestring (8-bit length prefixed) - bytestring (16-bit length prefixed) - fixed point - CODEPTR (as distinguished from an ordinary data pointer) - type - some of these? or is that too crazy? i think it's too crazy: https://en.wikipedia.org/wiki/Comparison_of_data-serialization_formats - function
And some composite type constructors: - array (homogenous) - struct (which, here, i guess is the same as tuple/heterogenous array/tree and maybe S-expr if you forget about the linked-list-ness, since any subelement can be COMPOSITE) - linked list (which, here, i guess is the same as S-expr, since any subelement can be COMPOSITE) - discriminated union (which, here, i guess is the same as ADT, since any subelement can be COMPOSITE) - nondiscriminated union - option (yeah this can already be represented but it's probably worth pulling out into its own type) - comptime - annotation
This is only 6 items so far, out of 56 spots, so i think we'll have room for whatever we need (be sure to leave lots of RESERVEDs and CUSTOMs!).
We could have 16 RESERVEDs and 16 CUSTOMs, which means we have 32 slots to fill now, of which the above might be the first 26, which means we'd have 6 left. That's more like it.
i'm sure other language implementations must have stuff like this (internal semi-compact semi-standardized representations of composite data types), what are they? i don't think i've come across it.
i'm worried that this is getting much higher-level than i'd like for LOVM, however. Maybe a lot of this should be bumped up to the OVM level, and just left as CUSTOM here.
for LOVM, maybe all we need are 16 non-composite types, saving spots for COMPOSITE and function types for OVM as above: :
maybe for ??? we let one composite type slip in there, probably bytestring of some sort. Null-terminated or length-prefixed? If length-prefixed, what is the bitwidth of the prefix (i'm guessing 32 bits, since we are 32-bit oriented here in LOVM)? We could have both null-terminated and length-prefixed if we drop int16 or uint16, and if we drop both int16 and uint16 then we can have one other thing too.
So for now let's just say:
yes, i think that's much better. All the composite type stuff is too complicated for the LOVM level.
But now if we can't pass function types, how do we do polymorphism?
One alternative is just to not do polymorphism (in which case we don't have to define types here at all). But another alternative is to do only OOP-style "receiver"-based polymorphism, in which dispatch takes only one primitive type argument. This is enough for what we really want polymorphism for at this level (generic arithmetic ops e.g. addition over all of int32, uint32, f64); and frankly, it's all that some target platforms will support anyhow (and more than many will support, which means that on those platforms we'll have to compile e.g. polymorphic ADD to a dispatcher)
---
how does Wren represent strings? interestingly, it has both a 32-bit length prefix AND a null terminator. Having the null terminator means that it can just directly call C library functions for basic string ops. It also has a hash value:
" A heap-allocated string object. struct sObjString { Obj obj;
// Number of bytes in the string, not including the null terminator. uint32_t length;
// The hash value of the string's contents. uint32_t hash;
// Inline array of the string's bytes followed by a null terminator. char value[FLEXIBLE_ARRAY];}; " -- https://github.com/wren-lang/wren/blob/main/src/vm/wren_value.h
this suggests to me that if we have a bytestring type, that we specify BOTH that:
this lets us use whichever native primitive bytestrings the platform provides (if any).
bytestrings would be just defined as self-describing arrays of bytes (that is, an array of bytes data structure that contains the length of the array in the structure, so that you don't have to pass the length around separately). When you want arrays with zeros in them, the programmer can just use pointers and keep track of the length themself.
---
yknow, regarding the issue of having the 'smallstack' be a register accessible from Boot, necessitating the concept of a Boot 'user code' profile, you could just put the smallstack registers above the 8 registers that Boot can see. My issue with that is that we really would like to do stack manipulation in the compact 16-bit instructions. But:
so, i'm still leaning towards just having a Boot 'user code' profile, but it's something to think about. The second best alternative seems to be: - use the zero registers to save the current smallstack depth, and a pointer to the memory where you put the smallstack and the other registers. - use a higher register (>7) that Boot can't see to indicate 'if you see this in an operand, pop/push to smallstack instead of storing in a register) - now the 16-bit encoding can't access SMALLSTACK at all, but Boot can use all of the 8 registers it can see (with the zero registers functioning as immutable zeros) - we could even make the register containing the TOS a normal Boot register; this won't violate Boot semantics because Boot can't do anything to cause the stack to be pushed or popped, so within Boot program code this just acts an ordinary register - use some or all of those 64 8-bit instructions as compact ways to encode instructions that use the stack - unfortunately the most obvious encoding (just offer every opcode in a stack-only form) probably isn't good enough b/c we also want to compactly have a mixture of stack and register arguments, and we have 64 potential opcodes and 64 8-bit instruction slots - but 64 is probably still enough for the most commonly used cases, so it's probably fine
hmm after writing that down i like it more and more..
---
probably want opaque calling convention probably want 'entry' or 'prolog' (function prolog) instruction that takes as an argument how many registers are needed (i guess separately for int and ptr regs), and 'epilog' instruction to define the end of each function scope in the linear instruction stream. mb use something like GNU lightning's 'argument management' to access arguments: https://www.gnu.org/software/lightning/manual/lightning.html#The-instruction-set. Or maybe just define a convention there.
between these, and CALL, and RETURN, the calling convention can be implemented opaquely.
remember the old interop instructions: xentry xcall0 xcalli xcallp xcallii xcallmm xcallim xcallip xcallpm xcallpp xcall xcallv xlibcall0 xlibcalli xlibcallm xlibcallp xlibcall xlibcallv xret0 xreti xretp xpostcall
---
i GUESS we could sometimes use the 4th operand to just pass another argument, not always to pass type information
---
maybe CALL takes 4 arguments: the destination register, the address to call, the number of int registers in use (ie to be saved if the calling convention makes them caller-save), the number of ptr registers in use
otoh dont we want to pass type information in CALL, at least sometimes (mb a separate polymorphic call instr)?
hmm could split the # of registers operand into 2 4-bit operands. But that would mean that only 16 regs can be saved in between calls.. i guess the rest could be callee-saved tho..
ENTRY would have a similar problem tho (need to specify how many int regs needed, how many ptrs needed, where to put the type info, where to put the link register). I guess 'where to put the type info' and 'where to put the link register' could be a convention; but specifying them would be nice because mb where you want to put them is 'on the stack'.
do we even want a pseudostack register for the MEMORY stack (MEMSTACK as opposed to the SMALLSTACK)?
also does ENTRY need to specify how many arguments there are? how many int args and also how many ptr args?
---
one thing to consider is not having all of the 255 'registers' mean the same thing, not just as a convention, but as fundamental semantics. Could have some or all of:
if there are only up to 16 caller-saved and 16 callee-saved regs, then you can specify how many you need of either one or the other of those classes, both int and ptr, in one 8-bit immediate operand.
---
yknow, first, we could just have a separate REGSAVE instruction rather than making the # of things to save argument(s) to CALL.
Second, this was not wrong above, but remember that the caller (CALL) only needs to specify how many of the caller-saved regs they need saved, and the callee (ENTRY/PROLOG) only needs to specify how many of the callee-saved regs they need saved.
---
if the CALL instructon doesn't take a destination register argument, then it could just be:
Where the arguments are, where the link register is, and where the return value(s) go could all be specified by the calling convention.
Although, to be fair, the type information could be specified by the calling convention just as easily.
---
arg regs and return regs are caller-saved
---
does the caller have to alloc shadow space on mstack? MS x86-64 convention has 32 bytes of caller-allocated shadow space. sysv x64 does not have this tho.
i think not. No shadow space, no 'red zone'.
---
if the convention for passing types to polymorphic functions is:
then you can make the 4th operand just be the 1st argument, and get an additional (code density) benefit from it when calling non-polymorphic functions.
---
one issue with a CALL3 mechanism is: how do you know if the CALL3 operands are to be interpreted as integer registers or pointer registers? Seems like you would need to use the addressing modes (either of the "opcode" ie function pointer, or of the operands) to disambiguate this. There's a lot of possibilities:
(note: you could mb just leave out the 0- and 1- argument forms (just pass immediate zeros for the arguments you don't need))
(note: you don't need immediate mode for pointers, do you? but maybe you do, just to pass null pointers? could also interpret that as PC-relative)
i guess we could redefine the operand addr modes for CALL3. Use 1 bit for int-or-ptr, and 2 bits for any 4 out of: immediate, register, smallstack offset, stack choice, register indirect. So this isn't too hard, it's just an additional complexity.
also, note that unlike normal calls, CALL3 doesn't do any caller-saving, so the convention is different (everything is callee-save)
---
yknow, most callers probably won't need many or any of the caller-saved registers to be saved, as they will use the callee-save registers for anything that needs to be saved across calls, especially since there are so many callee-save registers available in this architecture. So:
ENTRY/prologue is more likely to need to save stuff (the callee-save registers), and so should probably include two full saving operands.
Similarly, RET will often have to restore the callee-save registers, and so should probably include two full restore operands in addition to the value being returned (or maybe the two values being returned, since we have an extra operand).
---
but doesn't RET usually need to pop off the stack too? which stack? both? so doesn't it need to be told how many to pop off?
no; i think in many conventions, the only thing on the stack are the args (and maybe the return addr), and the callER cleans up the stack. This does, however, suggest that CALL does actually need to know how many arguments there are.
---
So, so far we're looking at:
CALL &fn #argcount(4-bit each for int and ptr; so 16 args max per bank) arg0/type arg1 -- or: one entry for int argcount and one for ptr, and no arg1 -- we dont need it to do anything except store the current address in the link register, but it does whatever the platform calling convention needs it to do (e.g. push args onto the stack)
ENTRY (maybe: #argcount) callee-saves-used-int callee-saves-used-ptr ?? -- pushes the needed numbers of callee-saves registers onto the stack. Note: the first callee saves ptr register is the link register, so if you are going to issue a CALL within this function but dont need any callee-saves registers for computation, then callee-saves-used-ptr should be 1, not 0.
RET (maybe: return_addr) return_value (maybe: #argcount) callee-saves-used-int callee-saves-used-ptr -- restores the callee-saves registers from the stack, puts return_value into the return register, then jumps to the link register (or, could leave the 'link register' on the stack but adjust the stack pointer, and then jump indirectly to the 'link regiter' value past the end of the stack)
---
so what if the platform doesn't provide as many callee-saved regs as we do? eg if we provide 64 callee-saved regs, and the platform provides 3, then we don't really want to save 61 regs upon CALL, because most of those probably aren't needed. So, we kind of do want CALL's operands to tell us how many int and how many ptr callee-saved registers are currently in use/actually need to be saved.
this suggests either: CALL &fn #argcount(4-bit each for int and ptr; so 16 args max per bank) #callee-saves(4-bit each for int and ptr; so 16 max per bank) #caller-saves(4-bit each for int and ptr; so 16 args max per bank) or CALL &fn #argcount(4-bit each for int and ptr; so 16 args max per bank) #callee-savesInt #callee-savesPtr
in option 1, arguments are caller-saveds but they don't count in the #caller-saves count
i'm leaning towards the first variant.
so, we seem to have 48 registers per bank:
we also presumably have some 'specials', such as the stack pointer. If we had 16 of these 'other things', then we'd have 64 registers per bank.
---
actually even in x86-64 there are a lot of situations where only 2 GB of code is allowed; see 13.3 64-bit memory models in Windows and 13.4 64-bit memory models in Linux and BSD and 13.5 64-bit memory models in Intel-based Mac (Darwin) in https://www.agner.org/optimize/calling_conventions.pdf
---
could also use Lua-style CALLs:
" CALLA B CR(A), ... ,R(A+C-2) := R(A)(R(A+1), ... ,R(A+B-1))Performs a function call, with register R(A) holding the reference to thefunction object to be called. Parameters to the function are placed in theregisters following R(A). If B is 1, the function has no parameters. If B is 2or more, there are (B-1) parameters.If B is 0, the function parameters range from R(A+1) to the top of the stack.This form is used when the last expression in the parameter list is afunction call, so the number of actual parameters is indeterminate.Results returned by the function call is placed in a range of registersstarting from R(A). If C is 1, no return results are saved. If C is 2 or more,(C-1) return values are saved. If C is 0, then multiple return results aresaved, depending on the called function. " -- http://luaforge.net/docman/83/98/ANoFrillsIntroToLua51VMInstructions.pdf
actually we could provide both (both Lua-style calls, and calls that use a fixed set of registers for argument and return passing)...
---
yknow, instead of providing how many caller-saved registers to actually save upon each CALL, could store this in special REGISTERS instead (since it will often be set upon ENTRY and stay constant across a function). Then you have less CALL operands and you can exceed the 16 register limit and use more of the potential 255 registers
so we're looking at:
CALL fnptr #argcount(4-bit each for int and ptr; so 16 args max per bank) arg0/type ? -- reads the #s of caller-saves from special registers, and saves them, then calls, then restores them
mb also CALLLUA (same arguments as CALL) -- same as CALL but instead of the arguments being the first 16 registers, they are taken from the registers immediately after the fnptr register
ENTRY caller-save-needed-int caller-save-needed-ptr callee-save-needed-int caller-save-needed-ptr -- puts all 4 args into special registers, and saves the callee-save-neededs, (do we also need #args tho? mb but probably not..)
RET return-value -- reads the #s of callee-saves from special registers, and restores them
---
should we have IP-relative addressing so that position-independent code is ez? Or mb use some other register and do everything relative to that?
makes me go back to thinking about those X,Y registers from apple
http://www.obelisk.me.uk/6502/addressing.html http://www.emulator101.com/6502-addressing-modes.html http://skilldrick.github.io/easy6502/#addressing
could use our wealth of registers as a sort of 'zero page'. Do we want to allow indexing into the set of registers though? Probably not.
---
oo remember how pretty this used to be:
" initial commit Bayle Shanks authored 4 years ago
OVM is a virtual machine platform for programming language implementation. It is distinguished by a small, easy-to-port implementation, yet with the ability to preserve some high-level constructs when used as a target IL. Ovm is a prototype and is incomplete and buggy. There have not been any releases yet. Ovm is open-source (Apache 2.0 license).
Motivation Ovm is being (very slowly) developed for the Oot programming language (which is also under development), to serve as:
the language in which Oot will be implemented in a target IL (intermediate language) for Oot programs
Ovm is motivated by Oot's aspirations to be an easy-to-port 'glue language' that can run under, interoperate with, and transpile to/from a variety of languages and platforms. The reason for Ovm's existence is that many other virtual machines:
are too big: many VMs have large implementations and long specs, making them hard to port constrain control flow: many VMs and ILs are written to support a particular HLL (high-level language) and only support control flow patterns of that HLL (for example, some VMs/ILs have trouble with tail calls) are too low-level: on the other hand, there are some tiny VMs that consist of only a handful of assembly instructions and few or no registers. When HLL constructs are compiled into assembly, program structure can be difficult to recover; such a language would not be suitable as an IL for transpilation between HLLs
Ovm deals with these issues:
Ovm has a small implementation. Much of its functionality is in its standard library, which is itself written in Ovm (so you don't have to port it) Ovm is assembly-like and supports arbitrary control flow patterns via computed GOTO and exposure of the callstack Ovm is slightly higher-level than assembly and provides enough registers for a simple mapping of HLL variables to registers in most cases, but more importantly, it is extensible, which allows the standard library to define some higher-level constructs
The implementation of even relatively simple and common operations as standard library functions makes them inefficient. The motivation of this is just to allow us to have a small core, for portability, and push most of the functionality into the standard library. An Ovm implementation which values efficiency over portability could simply override some of these standard library calls with native implementations. Ovm is structured to make this easy to do.
What's here This repo contains:
ovm: command-line frontend to pymovm pymovm: a minimal Ovm implementation (in Python) oasm: Ovm assembler odis: Ovm disassembler pyooblib: a Python library for working with .oob files (and .ob0 files and raw ovm bytecode files) cinstr.ob0 and syscall.ob0, part of the 'standard library' of Ovm docs: There are no docs yet. For now, see http://www.bayleshanks.com/proj-oot-ootAssemblyThoughts (and possibly the later items in the http://www.bayleshanks.com/proj-oot-ootAssemblyNotes* series eg http://www.bayleshanks.com/proj-oot-ootAssemblyNotes13 ).
Ovm understands three file types (raw and .ob0 formats are understood by the core OVM implementation, .oob format is supported by standard library functions):
raw: raw Ovm bytecode .ob0: a simple module format containing a list of functions, their type signatures, their bytecode implementations .oob: "Oot bytecode", a more elaborate module format also containing imports, constant tables, signatures, optional debugging information, etc (not implemented yet).
Overview of the Ovm language Ovm is a assembly-like 3-operand CISC memory-to-memory register machine with 2 primitive types, 4 primitive address modes, 16 primitive instructions, 256 registers, a data stack, and a call stack. Primitive types:
U16: unsigned 16-bit integer PTR: pointer
Primitive address modes:
immediate register register indirect (the equivalent of LOAD/STORE) stack (post-increment/pre-decrement upon read/write; reading/writing to a stack pointer pops/pushes the stack)
Primitive instructions:
annotate (not a real instruction, but an annotation of this point in the code) loadi (load immediate) cpy (copy) add-u16-u16 (addition on integers) sub-u16-u16 (subtraction on integers) leq-u16-u16 (<= comparision on integers) add-ptr-u16 (add an integer to a pointer) sub-ptr-u16 (subtract an integer from a pointer) call3 (call the function represented by a function pointer, passing in 2 inputs and getting 1 output) lea (load effective address: given an addressing mode and operand data, compute an effective address) syscall (call various language or system services) jzrel (conditional relative branch; branch if input is zero) jnzrel (conditional relative branch; branch if input is non-zero) j (absolute jump (or static, or immediate jump); jump to a fixed label) ji (indirect jump (or dynamic jump); jump to a pointer in memory) (maybe: swap?)
Ovm will provide compile-time type checking (not yet implemented). Ovm provides the following features which are atypical for assembly-like languages:
Generic and ad-hoc polymorphism Single-instruction function calls to first-class-functions: a memory location holding a reference to function is called, passing in 2 inputs, and assigning one output Capability-based security (not yet implemented) Separate data and call stacks; also, stack, and the register file, are first-class and may be swapped in a single instruction to allow concise 'caller saving' of registers, greenthread context switching, etc. Extensibility features:
custom instructions, written in Ovm custom syscalls, written in Ovm user-defined data structures with getters and setters written in Ovm (not yet implemented) language hooks which call Ovm code (not yet implemented)
Oot has three bytecode encodings, SHORT (16-bit fixed length instructions; defined but not implemented yet), MEDIUM (64-bit fixed length instructions), and LONG (under development; variable-length instructions composed of a 64-bit aligned stream of 16-bit words). " -- https://gitlab.com/oot/ovm
---
how many regs to allow the use of? we want to save some for the implementation, right?
since i kind of like 64 anyway, there's a nice justification for that; 64*4=256, so if we only allow 64 regs in each bank and if registers hold 32-bit words then the implementation can convert register number to byte number in a heap-stored register bank
---
i really like the spirit of QBE vs LLVM:
https://c9x.me/compile/doc/llvm.html
" QBE is a much smaller scale project with different goals than LLVM.
QBE is for amateur language designers.
It does not address all the problems faced when conceiving an industry-grade language. If you are toying with some language ideas, using LLVM will be like hauling your backpack with a truck, but using QBE will feel more like riding a bicycle.
QBE is about the first 70%, not the last 30%.
It attempts to pinpoint, in the extremely vast compilation literature, the optimizations that get you 70% of the performance in 10% of the code of full blown compilers.
For example, copy propagation on SSA form is implemented in 160 lines of code in QBE!
QBE is extremely hackable.
First, it is, and will remain, a small project (less than 8 kloc). Second, it is programmed in non-fancy C99 without any dependencies. Third, it is able to dump the IL and debug information in a uniform format after each pass.
On my Core 2 Duo machine, QBE compiles in half a second (without optimizations)."
it's probably not for us right now for similar reasons as LLVM, as: (i) it's SSA (and right now we're looking for simplicity, not optimization) (ii) it's only for a few platforms (and right now we're looking for extreme and extremely easy portability)
but still interesting
---
two things to consider about CALLs and callee-save and caller-save variables:
1) the idea i had above of having the number of caller-save variables in use, and the number of callee-save variables in use, both be in special registers, works well in terms of this virtual machine, but if implemented straightforwardly has an implementation cost: - either these numbers are actually stored in platform registers, consuming a bunch of registers, or they are stored on the stack or heap, causing an extra unnecessary memory access upon each CALL/RETURN - this is because putting these things in registers makes them DYNAMIC variables, instead of statically known immediates - they are saved/restored automatically with the other registers, so it's not a 'problem' in that senses, but it is a performance problem - what these really should be are 'lexically scoped'; in this case 'linear lexical scope' would be enough, e.g. "any CALL/RET instruction after a PROLOG instruction and before the next EPILOG instruction take their number-of caller-save/callee-saves from the values given in the PROLOG instruction" - but, lexical scoping, even linear lexical scoping is perhaps slightly more complex than we want this language to be? - i dunno if it's actual a problem, is there really much of a complexity cost from this? If a compiler, you can still be doing single-pass; just have a few more state variables as you read thru the code that stores the last encountered number-of caller-save/callee-saves. If an interpreter, you can just use extra registers, as above, even though there's a perf cost to that. - still, even lexically linear stuff rubs me the wrong way a little. It seems it would be best to just have instruction operands in CALL and RETURN that contains that number of things that may have to be saved.
2) in actual register machines, the calling convention is just that, a convention, and programs have the option of using any register to pass arguments, not just the argument registers. However, in our case, some implementations might put some registers in actual registers and others in the stack or on the heap, so it might be simpler if we just made the caller-save/callee-save/argument register distinction an enforced property rather than a convention. That is, after a call, ONLY the argument registers are guaranteed to be preserved. Note that this strongly suggests that we should encapsulate callee-saving via an ENTRY/PROLOG instruction, so that implementations that wipe those registers anyway don't spend time redundantly saving the already wiped values (if it's left up to the program to do that explicitly).
so so far, i'm thinking:
---
Another place that extra/special registers might be useful is in defining custom instructions. Again, though, that would allow custom instructions to be redefined dynamically, whereas we probably want them to be defined 'lexically linearly' instead.
---
still have to figure out if we're doing hardware-style CALLs, where the argument register are a fixed group of registers, or Lua-style CALLs, where the argument registers are after the register holding the address to be jumped to. I'm thinking that we should do it hardware-style because maybe there's some reason they all do that, and even if not, there may be some impedence mismatch in translating to that (for example in tail calls), although i haven't thought it thru so i'm not really sure if there's a cost or not.
---
agner likes elf best: https://www.agner.org/optimize/calling_conventions.pdf
---
could still consider stuff like custom instructions, with a special register determining what the custom jnstructions do
---
an example of someone else's simple assembly language and simulator/debugger:
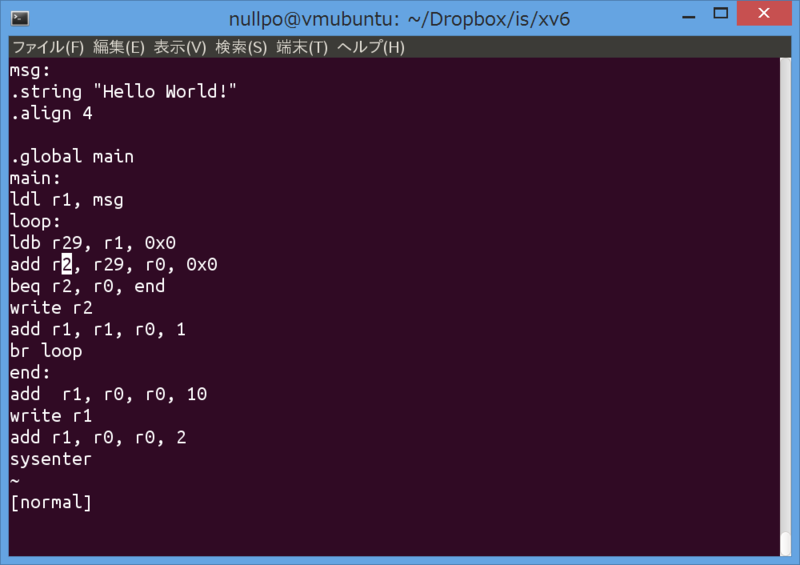
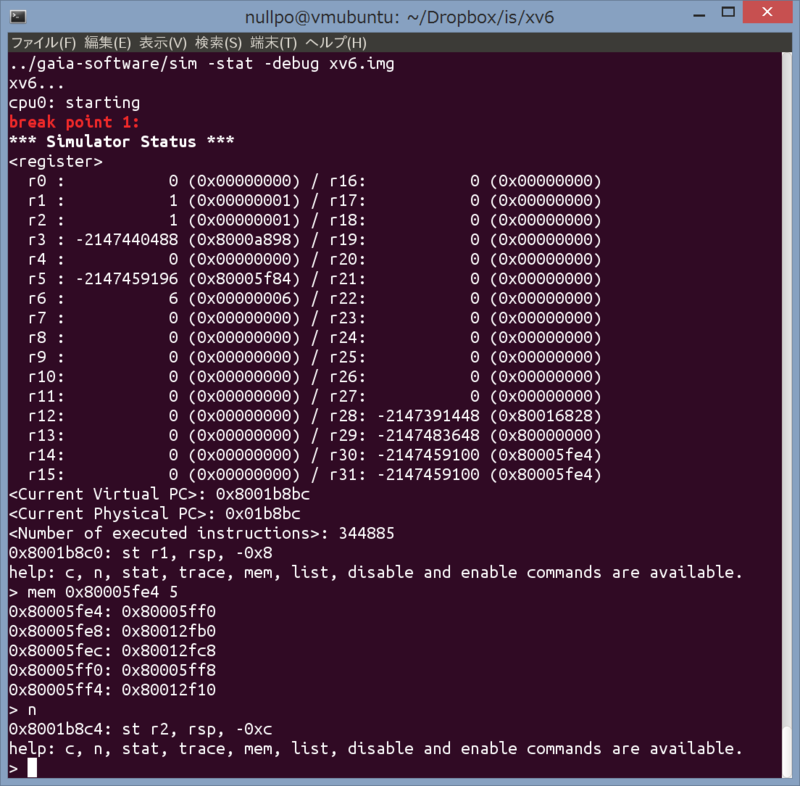
---
points out that labels can be the only thing in a line.
i think labels should be the only thing in a line, and those lines should always start with :
---
the goal of LOVM is to be a portable 'assembly-like' language which is somewhat efficient and a somewhat good IL for transpilation:
---
consider having offset ranges like MIPS (which is greater than RISC-V):
---
mb define an optional 'status register' (which CANT be used as a gpr, to ease efficient implementation ) and optional GPR 'accumulator' to (1) allow bigger immediates in special instr forms and (2) ease an orthogonal 8bit instruction set
---
could specify that instruction boundaries msut be consistent throughtout the program, that is u cant jump into the middle of an jnstruction as viewed by the alignment implied by decoding starting from the PC (and going forward or back) at any other time
---
my calculation at the top of lowEndTargetsUnsorted5 regarding the NXP i.MX 6ULZ suggests that we stay under:
in units of 32-bit words (4 bytes), that's:
so if we have 2 banks of 32 registers each, plus 2 smallstacks of 32 items each, that's already at the limit of 128 words, and we don't have room for metadata! So maybe that's too much.
It's still less than Erlang's processes though, which are at least 309 words [1] -- but that includes some non-stack heap as well as the stack (the process heap, which contains the stack, is 233 words).
so this suggests that we reduce the registers in each bank and each smallstack from 32 to 16. If we allow direct access to deep smallstack (indexed to TOS) as if it were another register bank, then a program can ignore the smallstack and effectively have 32 registers in each bank if it wants, which is enough.
So in each bank (before making space for the special registers) we'd have: 8 caller-save (temporary) GPRs 8 callee-save GPRs 16 smallstack GPRs
are arguments passed on the smallstack, or in the caller-save GPRs, or on the memory stack? With this setup we have more stack locs, so maybe on the smallstack.
---
so we're looking at:
one concern is that this proposal doesn't seem to provide enough caller-saves; in fact you want more caller-saves than callee-saves, not less. I suppose if arguments are passed on smallstack, though, those arguments can be thought of as caller-saves.
so maybe take the special registers out of callee-saves.
also, you probably want to interleave the caller- and callee-saves a little so that the 16-bit encoding, which can only easily access the first 8 regs, can access some of each. Just extend the Boot convention, i guess.
---
Looking ahead to the 64 8-bit encoding shortcuts, probably what we want to do is analyze and find the common things and then rationalize it so that we have a regular ISA subset. Initial thoughts, according to some stuff in my plChAssemblyFrequentInstructions:
Note that R1 thru R4 comprise the accumulator, TOS of SMALLSTACK, TOS-of-SMALLSTACK-with-implicit-push-pop, memstack pointer.
That's already all of our budget! But if it weren't, what else is common? Going thru everything in plChAssemblyFrequentInstructions, and writing down the stuff that appears in spot #1 in the various lists:
totals (top only): 10 mv, 11 ld, 2 lm, 2 addi, 2 call
writing down the stuff that appears in spot #2 in the various lists:
totals (top only): 3 mv, 8 ld, 3 lm, 5 cond branch or compare, 2 add
so i think it's clear that mov and ld are the most common, all things considered. After that maybe lm, and then maybe a conditional branch.
HOWEVER we won't have the offsets that these things usually do, so these might not be right for us, we'll have to see.
if we really do just have 32 MOVs between R1-R4 and 32 LDs between R1-R4, then we can completely regularize:
let's go with that for now, as this high degree of regularization may keep the interpreter code smaller
---
i think when making the calling convention we really need to think about making calling not very costly, a la Forth
---
And remember that if we only use 64 registers specifiers then we can use four addressing modes even in the 32-bit encoding
Lovm can have a limited number of registers but ovm can have 255. Lovm can have four addressing modes, or 8 if we don't specify the register bank in the operand.
---
RISC-V says that they didn't use a CAS instruction because it would have 3 source operands (or 5, for double-wide CAS) (and apparently the maximal number of input operands over the entire instruction set determines how many ports are required on the register file, which makes hardware power and mb perf worse).
Here's some things with 3 source operands:
i think we want those in LOVM (and probably even in BootX?). Mb not in Boot tho.
similarly, yeah, addressing modes makes things slightly harder for hardware, so they are in LOVM but not in Boot.
in fact, right now in Boot, i think we're already good; the STore instructions have only an immediate offset. So i don't think any instruction in core Boot reads 3 input registers.
---
i guess that if you pass operands in registers, then basically you could just say that up to all of the temporaries (caller-save) registers are used for arguments, in their are that many (non-vararg) arguments, then the last two are used for #rest-of-args and for ptr to the rest of the args.
---
---
consider a pointer to data storage area(s), and mb thread-local data, as part of register convention
Describe convention including stack pointer. Consider zero page like addressing mode.
---
for assembler:
look at example from https://www.muppetlabs.com/~breadbox/software/tiny/teensy.html. of empty elf file; it has $ and $$ for locations of stuff in the file, as well labels whose location can be subtraced from $, as well as db for data, dv for variable data, and equ to set a variable. i think: variables and labels are the same hthing. $$ is label of beginning of file and $ is label for current location
---
---
201021
The next big question for Lovm is Whether it is really just an assembly language and therefore has a normal-ish amount of registers, or alternately whether it is a high-level assembly language of some sort whatever that means. hence, Can it have a large number of potential registers without actually taking up space for those if they are unused. this might(?) imply that it always knows Which function it is in and how many registers that function actually needs. We know that it is somewhat aware of calling conventions and memstack, like LLVM. But it is not as high level of Lua, which encapsulates the actual location function locals This question is important right now because it determines how much space in the encoding we need for registers therefore how many addressing modes we have, and Probably more importantly, the amount that the architecture constrains what we do in order to stay aware of how many registers are in use. i guess the real question is, Can I come up with a set of zero-cost conventions That allow the architecture to have a zillion registers in theory and yet never have to actually have them If the program never requests them. Some constraints that might bear on whether we have lots of registers or not: we're going to be doing stuff like tail calls and yielding between coroutines and green threads, so we are going to have to serialize state possibly to places other than a linear stack. We want compilation to be fast, so this might rule out a lot of global stuff in the language because we probably want to emit code as we encounter the first time (is that what is meant by a single pass compiler?). We want compilation to be simple if we target boot or LLVM. We don't want to be doing lots of allocations unnecessarily. we don't want to have mandatory minimal state per greens thread be large. If we have a lot of registers we probably want a single instruction To save / restore state that can be used during green threads. To keep it zero cost we should probably tell it how much state there is. If we have four types of state (two register banks and two small stacks) and each type has a 64 item max, then it takes six bits to describe each of these four types for a total of 6 * 4 = 24. How many data bits do we have in a 32-bit instruction encoding? 8 * 3 = 24. So it's not crazy to think that we could do this.
what are our goals here? well, although we want to be easily compilable to Boot, really we could do without Boot; Boot is just there to make it easier to implement our stack in case someone who doesn't have the time to implement LOVM directly. So Boot is kind of like training wheels (although there's nothing wrong with just implementing Boot on a platform and then never implementing LOVM; performance may be worse but everything else should work). Really we should be thinking of LOVM as our lowest-level 'assembly-like' VM. So we don't want to be climbing the abstraction ladder yet, unless we can do so at (close to) zero cost. For example, we don't want to force the implementation to do things like register allocation just to compile LOVM to Boot; it should be feasible for the extra registers in LOVM to just be straightforwardly mapped to memory. On the other hand, the reason we even bother with LOVM given that we already have Boot is that we don't just want any old assembly-like language, we want a kick-ass assembly-like language (as noted elsewhere, partially so that LOVM can serve as an intermediate language for transpiliation; but also partially just because if we have to make up an assembly language and then use it for writing all of OVM, it may as well be a kick-ass one, so that the OVM implementation is both readable and performant; yet the LOVM implementation still has to be small and simple).
---
so i guess the thing to do is think about: if we have an abundance of registers, but the program doesn't need them, does the implementation end up causing the possibility of using the others to have a significant cost? Since we are choosing between 16-regs-per-bank and 64-regs-per-bank, our goal is to imagine we have 64-regs-per-bank and see if we can find a situation in which that has to be worse than 16-regs-per-bank.
so let's imagine that we have 64 registers in each bank, but a program/function P only uses 16 of them. What happens during:
---
function calls: P, who only uses 4 registers, nevertheless will be forced to use a lot more when P calls another function who takes a lot of arguments, if the calling convention says that a large number of registers are available for passing arguments and that they should be used first.
so, if we want the 64-reg case to be no worse than the 16-reg case, we should have at most 16 argument-passing registers.
---
if there are some implementations that dont track the smallstack stack depth (using just a circular stack, for example), they will have to spill the entire smallstack if a callee needs to push anything. So if there are many regs, either the implementation must track stack depth, or the program must and must pass that information to callees, who uses or passes that information to the implementation when it is/may be time to spill.
---
i think the possibility of tail calls implies caller-cleanup?
(assuming we dont want a separate calling convention for tail calls)
---
if some greenthreads have less state than others than we need to store the length of state being stored. if maximal state is 16*4, that's 4 bits*4 = 16 bits, and if it's 64*4, that's 6 bits*4 = 24 bits. So, two bytes vs 3 (or maybe 4 if 16-bit alignment is needed). Not a big deal.
---
if LOVM provides special instructions to save and restore state, and if there's a lot of potential state, then you have to pass arguments to these instrs saying how much state there actually is. If this is 16 bits then you still have a third operand for another purpose, but if it's 24 bits then all of your operands are used up, and these instructions must have hardcoded input and output registers that are the only ones they can use. Ugly but not a big deal.
---
in 24 bits there's not enough space to separately specify how many caller-save vs how many callee-save registers are in use for 4 register sets (2 banks, 2 smallstacks). If you need that granularity then you're going to have to have multiple instruction calls to pass along the register usage info.
---
mb see https://cs.stackexchange.com/questions/35760/what-are-the-disadvantages-of-having-many-registers
---
i'm 1/2 way thru reading https://cs.stackexchange.com/questions/35760/what-are-the-disadvantages-of-having-many-registers
so far:
however, if the bits to say how many registers are in use is such a big deal, we can just say that only powers-of-two registers can chosen to be in use. That is, for each bank, you can only choose between:
that's 8 choices, so it takes 3 bits instead of 6, times 4, is 12 bits total. So there are 12 bits left for the other operands. That's not a multiple of 8, however, so it means that we only have 1.5 other operands to work with.
If we wanted to fit this information in just 1 operand, we'd only have 8 bits total, which is 8/4=2 bits per bank, so we could only have 4 choices. What might those be?
we probably want to preserve the '0 registers' choice, because we may have substantial savings when we can skip saving one bank altogether. And if we are talking about having 64 regs then we'd better save that choice. Which others to get rid of? On the one hand, the cost of going from 32 to 64 registers is substantial, so we may want to save 32. On the other hand, functions that use few registers are probably more common, so distinguishing between them probably saves more.
Design of the RISC-V Instruction Set Architecture by Andrew Waterman Figure 5.2: Cumulative frequency of integer register usage in the SPEC CPU2006 benchmarksuite, sorted in descending order of frequency shows that even as little as 1 register in use occurs 20% of the time, with a very smooth curve up as you get more registers. Looks sort of like an inflection point is 8 registers, however.
we have 4 banks so is 8 registers for them like 2 for us? probably more like 4 for us.
also probably either '8 registers per bank' or '16 registers per bank' is conceptually attractive because would also be good choices for the total number of registers available period.
4 registers per bank is just enough to have:
(although if we have addr modes we may not need a smallstack register and/or a smallstack TOS register)
So maybe something like:
---
to summarize the previous section: i'm still reading that thing but one thing i though of was:
for 4 choices, good choices might be:
recall that these are each 'per bank'.
---
one issue is that if you are jumping into library code or you are the scheduler jumping into a greenthread, you dont statically know how many registers it needs, so you have to read this from a register or memory or something. But other times you do statically know, and you probably want to surface that to the implementation by using an immediate. So you want addressing modes on the information about how many registers are in use. But with even 8 bits, there's no space for that. I guess you could just use multiple opcodes for different addressing modes. Or, with 8 bits (but not 12 bits), you could use 2 operands.
i'm kind of thinking there might be unknown benefits to having a small menu of choices about how many registers are active, even besides having more operands free (physical registers could have sleep modes, virtual ones could use slab allocation to reduce fragmentation, register save/restore code could be unrolled/specialized/'monomorphized' to these choices, etc). So yeah, if we decide to do >16 regs per bank at all, then i like:
---
but now imagine you're jumping back to someone else's code. Now you have to store both (a) the return address, and (b) their register usage configuration. So you can't just use a link register, you have to store 2 things on the stack, etc.
mb the implementation could ease this by storing the return address together with the register usage config using tag bits. How many tag bits are available? on x64 right now memory addrs are only 48 bits but i've heard intel is switching to '5 level paging' which will use 57 bits (leaving 6 or 7, i guess). and i guess from first principals, if a 32-bit address must be 32-bit aligned then you get 4 bits free.
now, 4 bits is only half of the 8 bits needed for the above. Having one bit for each bank isn't too useful (16 vs 64? off vs on? you'd really like to go at least off/16/64, in which case you have 4 bits so you may as well throw in another choice). Maybe restrict the combinations across banks? e.g. obviously you'll probably never want all 4 banks off.
so, with 4 bits, you get 16 choices across all 4 banks.
maybe:
that seems to be working out reasonably, if not great. However merely storing this table adds cost and complexity, so i dunno. but i expect i can find some regular function on 4 bits to come up with that sort of thing. Something like: the sum of the 4 bits determines the two choices of values between the slashes, and then where the bits are determines where the bigger value is. This rule (as with most regular ones, i bet) still leaves an all-zero, however -- whatevs. eh, the table is probably fine.
the table is 4x16 entries, where each entry is 6 bits, so 4*16*6/8 = 48 bytes. Not nothing, but it's only 12 words.
however, one issue i have with this is that some architectures may not have ANY tag bits available. i don't want the program to be able to just assume that any pointer can always hold 4 tag bits, do i? or am i happy with the implementation falling back to saving 256 registers every time on platforms with no tag bits?
wait a minnit i'm dumb: fitting the register state configuration into four tag bits is kind of stupid because the register state itself has to be saved somewhere else, so it can easily have a length header. The only time you need to describe the amount of state is when you're creating that state -- either an ENTRY instruction to allocate the registers before us, and/or before you jump away when you save them to say how many are currently in use
---
so far i see no (good enough) reason not to allow up to 64 registers, while allowing an 8-bit selection of how many of those are active e.g. within each function.
---
if ENTRY selects a # of regs, could store this choice of # of registers in a register itself; then the program can save it on the stack before a call the same way a non-leaf function saves the link register (although a special instruction will be provided to do this stuff; each program doesn't have to implement it manually).
---
so, i'm tired right now and probably making mistakes, but i think we're looking at:
the cost is:
and the benefit is:
if the machine knows, it might be able to implement something like register windows instead of just spilling to the stack always
if the machine doesn't need to know, or if it can just have hidden state (or special state in a similar manner to the PC) that remembers how many registers are currently active, we might be able to avoid the #register register. Upon RET, we know how many registers to restore because that information can be saved with the saved register states themselves. Upon CALL, we provide the number of caller-saves as an operand. Currently, this sounds better to me.
one reason to mb keep the #registers register, and the secondary #registers register, is that, consider a function that uses no caller-saved registers. There is no reason for this function to need to save anything on the stack before a CALL, but it does have to save its #registers state. So maybe, like a link register, it would prefer to save that state in another register, rather than on the stack.
---
I'm overthinking it; most of this can be done by calling sequences in software without ISA support.
(note: see next section for a more readable summary of the following thoughts)
The real problem is in pre allocating resources for a new thread (green thread or otherwise); Even if the main routine doesn't use that many registers, it could conceivably use a library that calls another library that uses a lot. You could say oh hey I'll just never call libraries that do that, but the language-wide convention as to how many registers are available will probably lead to some libraries using most of them.
And you probably don't want to allocate space for registers and then have to reallocate later, although actually maybe that's okay cuz isn't that what golang and erlang do with stacks? Although i guess the real problem here is that if registers are being used right from the memory that they're allocated in for each greenthread, then this forces a check on every register write to see if it's too large to fit in allocated memory.
So the problem is really just for massive parallelism. But do we care; LOVM is already too beefy for the kind of small chip we expect to find in a massively parallel system; LOVM already supports 64-bit integers and floating point, which may not be available in such a system so we might just say that we expect that LOVM would have to be subseted or compiled down for that application anyway. If you did actually have massively parallel hardware, it would be relatively trivial just to recompile all applications and system libraries register allocating down to less registers. And you probably have to anyway because LOVM is probably too beefy for a small chip like that.
So the remaining problem case is green threads. In green threads, if you store registers in physical registers, you have to load those in on each task switch anyway, so I guess it's okay for different green threads to have different numbers of registers; again if libraries use more you can always compile four versions of each library with various register usages. In this case, though, it may be useful to make the programs declare how many registers they are using at any given time, so that the implementation knows how many to bother copying into the physical registers upon a context switch.
However the more problematic case is what if the implementation wants to execute each green thread by accessing the registers directly out of memory without copying them to one standard location? Here we have more of a problem because now before each register access you have to check if that register is really there in that green thread's TCB, whereas if there are few enough registers that you just always allocate enough space for all of them, you don't have that problem.
So here again we might find use for a special register allocation instruction declaring a change in the number of registers being used, which probably leads to calling conventions with a register containing the number of currently active registers. In this case, if a green thread is executing directly out of memory, and it calls the library using more registers than it uses, the library's register allocation instruction will notify the runtime, which can do the check once at that time to see if there are enough registers in this green threads TCB and if not, to allocate more; then you don't have to consider this possibility when accessing registers, only when you hit those #register instructions. However that's pretty complicated, I think it might actually be simpler just to tell users that if they need a massive number of threads, just recompile everything to use less registers. So the idea is the encoding supports lots of registers, but the implementation (to the extent that "implementation" includes library binaries) has (at least four) different profiles depending on how much concurrency you need.
In other words, for a very concurrent implementation, just compile LOVM code to use less registers at compile time.
Now consider again the more likely case where some registers are actually copied into target platform registers. The target platform probably has fewer registers than LOVM in any case. So LOVM is probably going to have some registers stored in platform registers and others stored in memory. So it's already doing some sort of check (or compile time specialization) on the register number and treating them differently. In the case of green threads where we initially allocated too few registers, we're just adding one more check here.
Also in the green thread case, when you think about the objection that a small program might call a library that needs to use lots of registers and worry about how that means we can use less concurrent threats, that doesn't quite make sense because the actual amount of memory needed to store each thread state is dependent on the program not the ISA; that library had to store that state somewhere whether it's in registers or in heap allocated to that green thread, so using a different ISA with less registers would not have allowed you to run more green threats concurrently in total anyway! So it may not be a big deal; The real cost is offering more registers than the platform offers, which we probably do want to do at this level.
i guess what i'm saying is that if you really care about maximizing concurrency by having little state per thread, then you have to only call library calls that actually don't need much state, which is a property independent of how many registers it uses. If you don't meet that condition, no ISA can help you; you need to store more state than you have memory available. If you do meet that condition, then you can compile LOVM down to LOVM-with-less-registers if you need to.
---
to rewrite the previous section more readably:
the question is, how many registers should the LOVM ISA have?
i've been worrying about how this affects the calling conventions, but i think i've been overthinking that; even if the ISA provides no support for keeping track of how many registers are in use, if the software saves and restores registers itself before/after calls using calling sequences, then it can do whatever is needed. For calling conventions and register save/restore, there is not much benefit to explicitly declaring how many registers are in use in a way that other parts of the system can read that, because even if a caller isn't using all of the callee-saves, it's possible that a grandfather caller is using the other ones, so the callee must still save them if it needs to use them. And symmetrically, even if a callee is not using all of the callee saved, the caller still needs to save them if it needs them to persist across calls, because a grandchild callee might overwrite them. (and, much of the time you will be deep in the call stack so it's likely that SOME grandfather is using each caller-save register, up to some point (64*4 may be way past that point)). So you'd need whole program analysis to take advantage of that sort of thing (which could be implemented with low cost with just declarations in the object file format of how many registers are being used by each function plus anything it might call), but it's not useful if you can only consider the register usage of the current caller and the current callee.
The real problem is, how much space do we allocate for registers for each process in a massively concurrent system?
first, you may think that having too many registers limits the amount of concurrent processes that a system can support (assuming a fixed total amount of memory). This isn't quite true: consider three cases:
A) the code needs to use all those registers for concurrently live variables B) the code doesn't need to use all those registers for concurrently live variables, but it does anyways because it is inefficient C) the code doesn't use all those registers
A: even if there were less registers, the program still needs this much state per process, so the total number of concurrent processes that you can fit into a fixed amount of memory is the same, whether or not you have lots of registers.
B: this can be turned into case C by writing the program to be more frugal in its register usage
C: some of the registers are unused, so it's possible for the implementation to get away with never allocating space for them. So let's explore the consequences of this.
Let's consider a few possibilities:
case 1a: this is unlikely because in this case the cores need to be small and simple and LOVM is probably too heavyweight anyways. So LOVM is probably not the ISA of each of these cores; even if something LOVM-like is there, it's probably a restricted subset (e.g. no 64-bit integer math) so we can also have a restriction on # of regs.
case 1b: we have a compilation step, so we do register allocation during that compilation and we can compile down to however many registers are physically available.
case 1c: here we have a problem. However it's not too terrible to say that these cores only implement a restricted profile of LOVM that supports less registers. Any LOVM program can be compiled (or even JIT-compiled) to one in this restricted profile using register allocation. So, the result is that we are forced to do some compilation (even if only in the form of JIT) even though we wanted to do interpretation. If we insist on JIT-compilation this affects throughput, if we use AOT it affects latency, but otherwise it's fine.
case 2a: here we have a problem because, if we initially allocate less memory for the registers in hopes that it won't need all of them, but then it does, we have to detect that and reallocate memory; which means that we have to do a check before each register write, or we have to think of registers as 'low' registers (for which space is allocated in the default initial allocation) or 'high' ones (which must be treated specially). In the latter case, either we do checks before each acces of high registers or we compile multiple variants of each piece of code for use in the situation before and after we've reallocated, and branch to one of them upon each entry.
in the former case (check before variable accesses), upon each access to a 'high' register (a high reg is one that isn't included in our default initial allocation), we have to first do a check to see if we've done the necessary reallocation yet (or, we compile multiple variants of each piece of code for use in the situation before and after we've reallocated, and branch to one of them upon each entry).
this is the sort of thing golang and erlang have to do to grow their stacks in their greenthreads anyways, so it's not too terrible, but here we're talking about it for registers, rather than stacks!
there's two kinds of costs here:
And again, if we really care about perf, we can do whole-program compilation.
In the latter case (compile multiple variants of each piece of code), this adds the overhead of storing that extra code, and the overhead of that extra branch (which isn't much i guess because it only has to happen once, at reallocation; after that, we stay in the part of the code dealing with the reallocated variant, and this is preserved across context switches b/c the PC is preserved).
case 2b: in this case it's only the smaller number of target platform processes which have their memory requirements increased. This is probably okay; if you have this situation, you probably have many fewer target platform processes than greenthreads, so the memory requirements of the target platform process VM probably don't dominate the memory requirements of the system.
case 2c: this is like 2a, except that here we already are treating 'low' and 'high' regs differently, so we can assume that the cost of treating registers differently in a staticly-known way is small.
So, to summarize all that:
If we care about perf that much we can do whole-program analysis, which would detect that less regs are needed. So only thing many registers really prevents is using full LOVM on a tiny chip without subsetting.
---
So my conclusion is that we can use the larger number of registers. Using LOVM directly on a tiny chip without compilation, interpretation, or subsetting to a restrictive variant of LOVM is out of scope.
It seems like we don't need an architecturally visible register for how many registers are in use by the current function; if the implementation wants that, it can just cache the last-seen value of the #registers allocation instructions. #registers allocation instructions may be useful for this reason, however. So ENTRY should include that, and we should provide instructions (or additions to functionality of instructions like RET) which save and restore groups of regs from memory (which will often just be to the stack).
---
So to summarize, we're looking at:
---
removed old text from lovm ref:
---
Rather than Computing Boot "reference opcodes" the way that I did it, could consider "expanding opcodes" and just let the bit pattern of the concatenated opcode field and opcode-like operand fields determine the reference opcode. However this generates OP codes larger than 256, which isn't helpful for reuse in LOVM.
---
some of what compilers use many registers for is loop unrolling. However, in our case, since the many registers probably aren't physical but the first few of them probably are, we don't want compilers doing that. So, we should probably provide special loop instructions to make an affordance that suggest that that's the best way to loop. We should also explicitly mention this issue.
---
https://stackoverflow.com/questions/35465373/why-not-have-separate-code-and-data-stacks
no answer is really given except for legacy incompatibility
one thing i can think of: harder to layout stuff in memory/memory fragmentation; you can't just have a heap growing upwards and a stack growing down, now you have two stacks. If you don't want to be segmenting them or moving them around all the time, now you gotta conservatively preallocate enough space for both of them. With our SMALLSTACKS we don't have this problem b/c they are fixed size (but see next section).
http://s3.eurecom.fr/docs/secucode09_francillon.pdf has a good thing to do regarding fragmentation; it puts the data stack on the bottom, growing UP, and puts the return stack (which ONLY holds return addresses) on the top, growing DOWN. This way the sum of both of them is that same that you'd normally allocate to a single stack, and they will never run out of memory unless the traditional single stack would run out of memory.
Of course that only works for two stacks. If we store our smallstacks as ordinary stacks to make it easier to spill things, then we'd have 4 stacks (integer smallstack, pointer smallstack, memory data stack (both data types), memory return stack (only pointers)).
we wouldn't want to unify our pointer smallstack with the memory return stack because the whole point of the memory return stack is that ordinary data processing isn't always mucking around with it, making it easier to secure. Otoh the actual use of a memory return stack in http://s3.eurecom.fr/docs/secucode09_francillon.pdf is to prohibit access to it except by CALL and RET, and we don't want to do that b/c we want to support task switching/coroutines/fibers/greenthreads, which requires swapping out the callstack or at least storing it in memory.
---
"The typical call stack is used for the return address, locals, and parameters (known as a call frame). In some environments there may be more or fewer functions assigned to the call stack. In the Forth programming language, for example, ordinarily only the return address, counted loop parameters and indexes, and possibly local variables are stored on the call stack (which in that environment is named the return stack), although any data can be temporarily placed there using special return-stack handling code so long as the needs of calls and returns are respected; parameters are ordinarily stored on a separate data stack or parameter stack, typically called the stack in Forth terminology even though there is a call stack since it is usually accessed more explicitly. Some Forths also have a third stack for floating-point parameters. " -- wikipedia
so we might decree that the calling convention is that parameters are passed on our smallstack. However that makes it certain that the smallstack will need to be spilled as we get deep in the call chain. Otoh on some implementations the 'small'stack is could just be implemented as an ordinary in-memory stack, then spilling is a no-op. But then with multiple stacks this reintroduces the memory fragmentation issue that our fixed-size stack avoided.
alternately, we might consider not providing facilities to spill the smallstack at all; the calling convention would then be that each function needs a certain amont of smallstack space, and the caller is responsible for making sure that much space is left. Or, more simply, we could make that expectation constant, at half of the stack size; if the caller needs more to persist between calls, they must spill, and if the callee needs more, they must spill.
---
the idea of storing the smallstack in memory and spilling it makes you think however. maybe there doesn't have to be a distinction between registers and the smallstacks at all?
Does there have to be a distinction between smallstacks and memstack? Well, yes, because smallstacks are not addressable. That lets a compiler optimize them better. But smallstacks could be regarded as the 'top of memstack'.
---
if we specify both caller- and callee #registers in use in ENTRY, with 4 choices each (0, 4, 16, 64) that's more than 8 bits; if we only specify that for registers and leave the smallstacks with a single thing, then that's 12 bits. So may as well fully use two 8-bit operands, which gives up 4 extra bits. But now we have 6 things that we are specifying, so i'm not quite sure how to use those 4 bits. I guess you could use them to specify: x2 for all registers, x2 for all stacks, x2 for ints, x2 for ptrs. Or instead of registers vs stack, x2 for caller, x2 for callee. Or we could just specify 4 of those 6 things with a finer grain (3 bits instead of 2, so 8 choices instead of 4: 0,1,2,4,8,16,32,64).
---
if we have a lot of registers all of which are probably not being used, let's make ENTRY be mandatory, so that the implementation can not allocate or not 'turn on' all of the registers until it encounters an ENTRY that requests them.
This also suggests that we do want to specify both caller and callee registers in ENTRY so that we can only turn on the ones we need. The third operand to ENTRY is the place to spill to if needed. If ENTRY should not spill, then this third operand can be immediate zero.
Same convention to not spill in CALL (the register that would ordinarily hold the place to spill to is instead immediate zero).
---
if we have immediates, then we don't need the zero registers. Then we can make those the 'smallstack push/pop' registers instead of #2, which allows us to have Boot compatibility without a 'user profile'.
but wait a minute, we WANT Boot to be able to do smallstack push/pop. So that's no good.
---
ppl say IA-64 failed b/c explicit, instruction-level parallelism (ILP) is too hard for compiler to figure out. But my guess is that (a) even if it was good but backwards incompatibility alone could have killed it, and (b) maybe the way IA-64 worked required it to understand the CPU architectural details too much.
we could put annotations in there that help the implementation know what instruction-level-parallelism opportunities exist. If you say 'here's a packet of instructions to run at once', that . Just annotations that say, hey, if you want to run these at once, you can (or maybe the opposite, assume that you can, and then have required annotations that say, hey, if you want to run these in parallel, you can't).
the simplest way to do this would be to group instructions together into blocks that can all be done in parallel. But the reality is probably more complicated; you might have things like:
A B C
where AB can be done at once, but also BC can be done at once, but A must precede C. You might also have things like:
A B C D
where A must be before B, and C must be before D, but A and B can be in parallel with C and D
However IA-64 just put 'stops' to delineate groups of instructions that could be reordered (in some ways). If it's complicated enough for them, i don't see why we should complicate it any more. One bit per instruction can indicate whether or not a 'stop' is present before that instruction. An 'instruction group' is a group of instructions between stops. If you had more bits you could have multiple 'lanes' for the 'stops' which could encode the more complicated stuff above.
---
wait we don't really have space for 4 addr modes and 64 registers in each bank; we need the encoding format bits. There are 3 of those.
so each operand only has 7 bits, not 8. So we only have 2 addr modes if we have 64 regs (immediate and register).
4 addr modes would be nicer than 2, so that might be enough of a reason to go back to 32 regs per bank.
the opcode could either have 256 instructions, or it could have 128 and we have room for an extra bit (which could be a 'stop bit' for ILP)
256 instructions is pretty nice so we may have to do without those stop bits. Also, is there even any way that a VM in software could really make use of that sort of thing? I guess you could have two physical threads trying to run every one thread in the VM, each one dividing up all of the instructions in the current instruction group between them, and then joining. But something tells me that the cross-thread synchronization there will overwhelm the savings from parallelizations.
--
best guess:
---
cons of register windows:
"You also see stack-like register windows (SPARC, i960, Am29k) and rotating register files (Itanium) but the general consensus seems to be that this is overdesigned and MIPS does just as well with 32 ordinary registers. 16 registers is almost as good in typical code (see: ARM, x64) but the "cost" of increasing from 16 to 32 is low enough that architectures tend to go with 32."
https://www.hpl.hp.com/techreports/Compaq-DEC/WRL-87-5.pdf
only looked for 5 secs but i think it says that the extra indirection in the data path (which is critical) is worse for perf that just not having register windows and having more registers
https://www.cse.msu.edu/~enbody/postrisc/postrisc2.htm offhand note "Register windows add some complexity to register renaming. However as the following processor shows, it is not impossible to have out-of-order execution with register windows."
https://people.inf.ethz.ch/wirth/Articles/GoodIdeas_origFig.pdf "The reason why it must be considered as questionable, is that at any moment only the top registers, those in the most recently opened window, are under direct use and are therefore frequently accessed. The others are quasi dormant, yet consume a scare, expensive resource. Thus, register windows imply a poor utilization of the most expensive resource. "
my thoughts:
these don't seem to apply to us. For us 'register windows' are more about the calling convention and way of expressing register access than they are about cacheing caller-saved register storage. And we are a VM not a CPU, so our 'register access' is already at least somewhat abstracted.
---
speaking of register windows, isn't having a link register (instead of just saving that to the call stack) kinda like having two register windows for the PC? It's the same argument about, a large fraction of calls are from the deepest non-leaf function to a leaf function.
so if that's such a good idea, maybe we should have 2 register windows instead of just 1. And then stuff like the link register is handled transparently.
or, since ordinary code won't need to look at random values from the caller's random registers, but remembering how register windows have an input/locals area and an output area,
we could put this 'architectural stuff' (the previous/caller's PC, the previous/caller's window size, etc) into the output area, which then goes near the beginning of the windowed registers in the callee's perspective.
---
Considering the floating point registers, we have a use for the extra two bits in the number of register specification for entry. Forget about specifying the number of output registers per bank, keep that hard coded at 8
done
---
another option for the 8-bit encoding is to abandon regularity, realize that i only really care about the operands getting 3 different combos, not 4 and add:
we have one empty space above already so we get to add 13.
of course we'd like drop and over, both banks, to be in there (x4), so after that there's 8 left.
that way we can fit in more of the more common instructions and/or possibly also get a basis set for smallstack-only operations.
