![[Home]](http://www.bayleshanks.com/cartoonbayle.png)
" this test by Alexander Medvednikov, the creator of the V programming language. This is a test of compiling a file with a 400 K function:
https://vlang.io/compilation_speed
I came across this test by Alexander Medvednikov, the creator of the V programming language. This is a test of compiling a file with a 400 K function:
C 5.2s gcc test.c
C++ 1m 25s g++ test.cpp
Zig 10.1s zig build-exe test.zig
Nim 45s nim c test.nim
Rust Stopped after 30 minutes rustc test.rs
Swift Stopped after 30 minutes swiftc test.swift
D Segfault after 6 minutes dmd test.d
V 0.6s v test.v"
" ... the following pair of statements 200 000 times:
a = 1 println(a)
a = 2 println(a) ... " -- https://vlang.io/compilation_speed
"
forgotpwd16 3 days ago [–]
Supposing you got interested because of the speed it claims, comparisons on the site shouldn't be taken at face value. Fixing any errors* and for N=2 (2K prints), the times for some of the languages (running ten times and taking the average) are:
C 0.24s (gcc 9.3.0, gcc $file) C++ 0.96s (gcc 9.3.0, g++ $file) Go 0.12s (go 1.15.2, go build $file) Nim 0.44s (nim 1.2.6, nim c $file) V 1.37s (v 0.1.29, v $file) Zig 16.9s (zig 0.6.0, zig build-exe $file)
I guess Zig does some optimizations but not sure how to turn them off. Someone should do an analytical comparison for all of them and different values of N.
reply "
---
https://en.wikipedia.org/wiki/Persistent_data_structure
---
https://github.com/markshannon/faster-cpython/blob/master/plan.md
---
McLaren? Stanley @StanTwinB? Replying to @StanTwinB? But once Swift started to scale past ten engineers the wheels started coming off. The Swift compiler is still much slower than Objective-C to then but back then it was practically unusable. Build times went though the roof. Typeahead/debugging stopped working entirely. 9:18 PM · Dec 9, 2020·Twitter for Mac
McLaren? Stanley @StanTwinB? · 21h Replying to @StanTwinB? There’s a video somewhere in one of our talks of an Uber engineer typing a single line statement in Xcode and then waiting 45 seconds for the letter to appear in the editor slowly, one-by-one.
McLaren? Stanley @StanTwinB? · 21h Then we hit a wall with the dynamic linker. At the time you could only link Swift libraries dynamically. Unfortunately the linker executed in polynomial time so Apple’s recommend maximum number of libraries in a single binary was 6. We had 92 and counting.
McLaren? Stanley @StanTwinB? · 21h Replying to @StanTwinB? As a result It took 8-12 seconds after tapping the app icon before main was even called. Our shinny new app was slower than the old clunky one. Then the binary size problem hit.
...
@StanTwinB? · 21h So we rolled up our sleeves, and put our best people on each of the problems and prioritized the launch critical issues (dynamic linking, binary size). I was assigned to both dynamic linking and binary size in that order. McLaren? Stanley @StanTwinB? Replying to @StanTwinB? We quickly discovered that putting all of our code in the main executable solved the linking problem at App start up. But as we all know, Swift conflates namespacing with frameworks; so to do so would take a huge code change involving countless namespace checks.
...
McLaren? Stanley @StanTwinB? · 20h We also replaced *all* of our Swift structs with classes. Value types in general have a ton of overhead due to object flattening and the extra machine code needed for the copy behavior and auto-initializers etc. This saved us space so we pressed on.
...
" Airbnb is 75% executables, 9.5% assets and 8% localizations. This is pretty different from Uber which is 60.7% executables, 26% localizations and only 3.8% assets. While the Uber executables are large, ~10mb more than Airbnb (note: this is only the Uber rider app, while Airbnb has host+guest in one app), their localizations seem to be driving a lot of the app’s 300+mb install size.
Looking at how the localizations are laid out in the app bundle, there are thousands of *.strings files in separate bundles, seems to be one for each feature. Many of these files have comments to provide context for the strings. An example from the app is: "Various screens show this as a title in a snackbar message when there is no network connectivity available". Just stripping these comments out of the localization files would save about 17.6mb of the install size. Another side effect of splitting localizations into so many files is there are over 23k duplicated strings throughout these bundles. "
---
rurban 14 hours ago [–]
This is exactly the reason why python is so slow. The everything is an object approach has no real benefit, as the code is still full of special cases. Faster VMs of course special-case int and float. Best at compile-time.
reply
pfalcon 9 hours ago [–]
Special-casing (only) ints and floats in VM is too trivial and a bloat for quite minor benefit. To start with, faster VMs are not VMs, but JITs. And they are able to specialize for arbitrary types, not just 2 random ones. I thought there were some "lessons learned" from ParrotVM?... ;-).
reply
---
moonchild 12 hours ago [–]
> C libraries typically return opaque pointers to their data structures, to hide implementation details and ensure there's only one copy of each instance of the struct. This costs heap allocations and pointer indirections. Rust's built-in privacy, unique ownership rules, and coding conventions let libraries expose their objects by value
The primary reason c libraries do this is not for safety, but to maintain ABI compatibility. Rust eschews dynamic linking, which is why it doesn't bother. Common lisp, for instance, does the same thing as c, for similar reasons: the layout of structures may change, and existing code in the image has to be able to deal with it.
> Rust by default can inline functions from the standard library, dependencies, and other compilation units. In C I'm sometimes reluctant to split files or use libraries, because it affects inlining
This is again because c is conventionally dynamically linked, and rust statically linked. If you use LTO, cross-module inlining will happen.
reply
dan-robertson 4 hours ago [–]
The reason Common Lisp uses pointers is because it is dynamically typed. It’s not some principled position about ABI compatibility. If I define an RGB struct for colours, it isn’t going to change but it would still need to be passed by reference because the language can’t enforce that the variable which holds the RGBs will only ever hold 3 word values. Similarly, the reason floats are often passed by reference isn’t some principled stance about the float representation maybe changing, it’s that you can’t fit a float and the information that you have a float into a single word[1].
If instead you’re referring to the fact that all the fields of a struct aren’t explicitly obvious when you have such a value, well I don’t really agree that it’s always what you want. A great thing about pattern matching with exhaustiveness checks is that it forces you to acknowledge that you don’t care about new record fields (though the Common Lisp way of dealing with this probably involves CLOS instead).
[1] some implementations may use NaN?-boxing to get around this
reply
kazinator 45 minutes ago [–]
Lisp users pointers because of the realization that the entities in a computerized implementation of symbolic processing can be adequately represented by tiny index tokens that fit into machine registers, whose properties are implemented elsewhere, and these tokens can be whipped around inside the program very quickly.
reply
rectang 12 hours ago [–]
> ABI compatibility
Rust provides ABI compatibility against its C ABI, and if you want you can dynamically link against that. What Rust eschews is the insane fragile ABI compatibility of C++, which is a huge pain to deal with as a user:
https://community.kde.org/Policies/Binary_Compatibility_Issu... https://community.kde.org/Policies/Binary_Compatibility_Issues_With_C%2B%2B
I don't think we'll ever see as comprehensive an ABI out of Rust as we get out of C++, because exposing that much incidental complexity is a bad idea. Maybe we'll get some incremental improvements over time. Or maybe C ABIs are the sweet spot.
reply
anfilt 12 hours ago [–]
Rust has yet to standardize an ABI. Yes you can call or expose a function with C calling conventions. However, you cant pass all native rust types like this, and lose some semantics.
However, as the parent comment you responded to you can enable LTO when compiling C. As rust is mostly always statically linked it basically always got LTO optimizations.
reply
johncolanduoni 9 hours ago [–]
Even with static linking, Rust produces separate compilation units a least at the crate level (and depending on compiler settings, within crates). You won't get LTO between crates if you don't explicitly request it. It does allow inlining across compilation units without LTO, but only for functions explicitly marked as `#[inline]`.
reply
moonchild 11 hours ago [–]
Swift has a stable ABI. It makes different tradeoffs than rust, but I don't think complexity is the cliff. There is a good overview at https://gankra.github.io/blah/swift-abi/
reply
kelnos 10 hours ago [–]
Swift has a stable ABI at the cost of what amounts to runtime reflection, which is expensive. That doesn't really fit with the goals of Rust, I don't think.
reply
skohan 10 hours ago [–]
Do you have a source on this? I didn't think Swift requires runtime reflection to make calling across module boundaries work - I thought `.swiftmodule` files are essentially IR code to avoid this
reply
kelnos 9 hours ago [–]
Pretty sure the link the parent (to my comment) provided explains this.
It's not the same kind of runtime reflection people talk about when they (for example) use reflection in Java. It's hidden from the library-using programmer, but the calling needs to "communicate" with the library to figure out data layouts and such, and that sounds a lot like reflection to me.
reply
saagarjha 9 hours ago [–]
This is misleading, especially since Swift binaries do typically ship with actual reflection metadata (unless it is stripped out). The Swift ABI does keep layout information behind a pointer in certain cases, but if you squint at it funny it's basically a vtable but for data. (Actually, even more so than non-fragile ivars are in Objective-C, because I believe actual offsets are not provided, rather you get getter/setter functions…)
I don't disagree that Rust probably would not go this way, but I think that's less "this is spooky reflection" and more "Rust likes static linking and cares less about stable ABIs, plus the general attitude of 'if you're going to make an indirect call the language should make you work for it'".
reply
kazinator 1 hour ago [–]
> This costs heap allocations and pointer indirections.
Heap allocations, yes; pointer indirections no.
A structure is referenced by pointer no matter what. Remember that the stack is accessed via a stack pointer.
The performance cost is that there are no inline functions for a truly opaque type; everything goes through a function call. Indirect access through functions is the cost, which is worse than a mere pointer indirection.
An API has to be well-designed this regard; it has to anticipate the likely use cases that are going to be performance critical and avoid perpetrating a design in which the application has to make millions of API calls in an inner loop. Opaqueness is more abstract and so it puts designers on their toes to create good abstractions instead of "oh, the user has all the access to everything, so they have all the rope they need".
Opaque structures don't have to cost heap allocations either. An API can provide a way to ask "what is the size of this opaque type" and the client can then provide the memory, e.g. by using alloca on the stack. This is still future-proof against changes in the size, compared to a compile-time size taken from a "sizeof struct" in some header file. Another alternative is to have some worst-case size represented as a type. An example of this is the POSIX struct sockaddr_storage in the sockets API. Though the individual sockaddrs are not opaque, the concept of providing a non-opaque worst-case storage type for an opaque object would work fine.
There can be half-opaque types: part of the structure can be declared (e.g. via some struct type that is documened as "do not use in application code"). Inline functions use that for direct access to some common fields.
reply
pornel 4 minutes ago [–]
Escape analysis is tough in C, and data returned by pointer may be pessimistically assumed to have escaped, forcing exact memory accesses. OTOH on-stack struct is more likely to get fields optimized as if they were local variables. Plus x86 has special treatment for the stack, treating it almost like a register file.
Sure, there are libraries which have `init(&struct, sizeof(struct))`. This adds extra ABI fragility, and doesn't hide fields unless the lib maintains two versions of a struct. Some libraries that started with such ABI end up adding extra fields behind internal indirection instead of breaking the ABI. This is of course all solvable, and there's no hard limit for C there. But different concerns nudge users towards different solutions. Rust doesn't have a stable ABI, so the laziest good way is to return by value and hope the constructor gets inlined. In C the solution that is both accepted as a decent practice and also the laziest is to return malloced opaque struct.
reply
---
>It's convenient to have fixed-size buffers for variable-size data (e.g. PATH_MAX) to avoid (re)allocation of growing buffers. Idiomatic Rust still gives a lot control over memory allocation, and can do basics like memory pools, combining multiple allocations into one, preallocating space, etc., but in general it steers users towards "boring" use or memory.
Since I write a lot of memory-constrained embedded code this actually annoyed me a bit with Rust, but then I discovered the smallvec crate: https://docs.rs/smallvec/1.5.0/smallvec/
Basically with it you can give your vectors a static (not on the heap) size, and it will automatically reallocate on the heap if it grows beyond that bound. It's the best of both world in my opinion: it lets you remove a whole lot of small useless allocs but you still have all the convenience and API of a normal Vec. It might also help slightly with performance by removing useless indirections.
Unfortunately this doesn't help with Strings since they're a distinct type. There is a smallstring crate which uses the same optimization technique but it hasn't been updated in 4 years so I haven't dared use it.
reply
totalperspectiv 3 hours ago [–]
I’ve been using smartstrings, which is both excellent and maintained. https://github.com/bodil/smartstring
reply
---
AndyKelley? 1 day ago
| parent | flag | favorite | on: Speed of Rust vs. C |
> computed goto
I did a deep dive into this topic lately when exploring whether to add a language feature to zig for this purpose. I found that, although finnicky, LLVM is able to generate the desired machine code if you give it a simple enough while loop continue expression[1]. So I think it's reasonable to not have a computed goto language feature.
More details here, with lots of fun godbolt links: https://github.com/ziglang/zig/issues/8220
[1]: https://godbolt.org/z/T3v881
Measter 1 day ago [–]
Rust's output[0] is basically the same as Zig in this case. The unsafe is needed here because it's calling extern functions.
However, in this specific instance at least, this isn't as optimal as it could be. What this is basically doing is creating a jump table to find out which branch it should go down. But, because all the functions have the same signature, and each branch does the same thing, what it could have done instead is create a jump table for the function to call. At that point, all it would need to do is use the Inst's discriminant to index into the jump table.
I'm not sure what it would look like in Zig, but it's not that hard to get that from Rust[1]. The drawback of doing it this way is that it now comes with the maintenance overhead of ensuring the order and length of the jump table exactly matches the enum, otherwise you get the wrong function being called, or an out-of-bounds panic. You also need to explicitly handle the End variant anyway because the called function can't return for its parent.
I don't know Zig, but from what I understand it has some pretty nice code generation, so maybe that could help with keeping the array and enum in step here?
[0] https://godbolt.org/z/sa6fGq
[1] https://godbolt.org/z/P3cj31
reply
---
" VMs have a lot of nice advantages in theory, chiefly that they are very cross-platform and come with state-of-the-art runtime tools (like garbage collection) that you’d otherwise have to build yourself. Unfortunately, they traditionally have some weird problems that are showstoppers for many languages, such as the lack of value types on the JVM. No major VM supports coroutines, the clear winner in approaches to composable concurrency, so if you want this feature you’re back to building your own runtime. Project loom and the Wasm effect handlers proposal are exciting here, though. If and when wasm achieves its ambitious goals2 there will be far fewer reasons left to go native, and VMs have every chance to play a starring role in future language innovation – much as LLVM has over the last decade. https://wiki.openjdk.java.net/display/loom/Main https://github.com/effect-handlers/wasm-effect-handlers " [1]
---
"
---
" Windows
Excluding the issue of site isolation, only the Firefox sandbox on Windows is comparable to the Chromium sandbox but even then, it still lacks win32k lockdown. Win32k is a set of dangerous system calls in the NT kernel that expose a lot of attack surface and has historically been the result of numerous vulnerabilities. Microsoft aimed to lessen this risk by introducing a feature that allows a process to block access to these syscalls, therefore massively reducing attack surface. Chromium implemented this in 2016 to strengthen the sandbox but Firefox has yet to follow suit — Firefox currently only enables this in the socket process. "
https://chromium.googlesource.com/chromium/src/+/master/docs/design/sandbox.md#win32k_sys-lockdown https://github.com/microsoft/MSRC-Security-Research/blob/master/presentations/2018_10_DerbyCon/2018_10_DerbyCon_State_of%20_Win32k_Security.pdf https://docs.microsoft.com/en-us/windows/win32/api/winnt/ns-winnt-process_mitigation_system_call_disable_policy
---
on using Clang's new 'musttail' tail calls for more efficient interpreter loops:
https://blog.reverberate.org/2021/04/21/musttail-efficient-interpreters.html https://news.ycombinator.com/item?id=26931581
the author of that blog post says that it is even better than computed gotos on architectures that, like x86-64 ABI, guarantee that the first 6 function params are passed in registers
---
" A correctly-specified ABI should pass large structures by immutable reference, usually obviating the copy. In the event that a copy is needed, it will happen only once, in the callee, rather than needing to be repeated by every caller. The callee also has more flexibility, and can copy only those portions of the structure that are actually modified. "
-- [2]
"
nneonneo 2 hours ago [–]
Hmm, I don’t agree. If you pass a structure by value, that is supposed to make a copy. The callee is free to modify the copy any way it likes (unless you use const, and that’s not much protection in C). Doing as the author suggests, and passing in an immutable parameter, would introduce copy-on-write semantics.
If the concern is the overhead of copying large structures around, the obvious solution is to not do that and simply pass structure pointers (like most APIs do). This also gives the API implementer (i.e. callee) full control over whether copies get made or not.
In fact, I think I’d argue that if you’re passing large structures by value, Your API Is Probably Wrong and this is absolutely not the ABI’s problem in the first place.
reply
foobiekr 1 hour ago [–]
"A correctly-specified ABI should pass large structures by immutable reference"
There is no such thing at the level that the ABI works, especially at a kernel-userland boundary (where the choice is to fully marshal the arguments or accept that you have a TOCTOU issue).
reply
legulere 1 hour ago [–]
Callee saved registers kind of work like that. You either don't touch those registers, or you restore them before returning.
reply
gumby 28 minutes ago [–]
> Unfortunately, that doesn’t work anymore; compilers are smart now, and they don’t like it when objects alias.
Let's be specific: compilers for languages that support aliasing. For example, FORTRAN does not permit aliasing and therefore has all sorts of optimizations that languages that do permit aliasing cannot have.
It's a tradeoff like any other, and isn't specific to a compiler beyond the fact that a given compiler X can compile language Y.
cokernel_hacker 1 hour ago [–]
My reading of the C++ standard is that this behavior is effectively mandated and that one can write a program which can tell if an ABI observed the proposed optimization.
[expr.call]: "The lvalue-to-rvalue, array-to-pointer, and function-to-pointer standard conversions are performed on the argument expression."
[conv.lval]: "... if T has a class type, the conversion copy-initializes the result object from the glvalue."
The way a program can tell if a compiler is compliant to the standard is like so:
struct S { int large[100]; };int compliant(struct S a, const struct S *b);
int escape(const void *x);
int bad() {
struct S s;
escape(&s);
return compliant(s, &s);
} int compliant(struct S a, const struct S *b) {
int r = &a != b;
escape(&a);
escape(b);
return r;
}There are three calls to 'escape'. A programmer may assume that the first and third call to escape observes a different object than the second call to escape and they may assume that 'compliant' returns '1'.
reply
~ MrSmith?33 26 hours ago
| link | flag |
How do you solve this problem with proposed ABI?
struct Big { int a = 11; ... } sizeof == 32 bytes Big big;
void foo() { bar(big); }
void bar(Big param) { qux(); print(param.a); will print 42 instead of 11 }
void qux() { big.a = 42; }
~
cmcaine 25 hours ago | link | flag | The proposed ABI says that the passed object should be immutable, I think.
~
MrSmith33 24 hours ago | link | flag | A correctly-specified ABI should pass large structures by immutable reference, usually obviating the copy. In the event that a copy is needed, it will happen only once, in the callee, rather than needing to be repeated by every caller. The callee also has more flexibility, and can copy only those portions of the structure that are actually modified.
Looks like the immutability only applies to the reference that callee holds, not the original lvalue. This paragraph also says that only callee will ever need to do the copy. The only way to fix this that I see, is to do copy on caller side if it cannot guarantee that callee holds the only mutable pointer to the data.
~ Moonchild 19 hours ago
| link | flag |
It’s a good point. I guess my answer is that structures should generally be passed by value, and that global variables should generally be avoided, meaning that there won’t generally be opportunity for aliasing. In the event that there is aliasing you have to make a copy on the caller side, but you’re not much worse off than you would otherwise have been.
-- https://lobste.rs/s/ltroon/your_abi_is_probably_wrong
---
gotta decide if TRUE is 1 or -1 (the all-ones bit pattern)
related: http://lars.nocrew.org/forth2012/core/NEGATE.html https://rosettacode.org/wiki/Boolean_values#Forth https://www.google.com/search?q=boolean+bits+all+ones+bit+pattern+represent+true
---
colanderman on April 14, 2020 [–]
You can enable this in GCC on a compilation unit basis with `-fsanitize=signed-integer-overflow`. In combination with `-fsanitize-undefined-trap-on-error`, the checks are quite cheap (on x86, usually just a `jo` to a `ud2` instruction).
(Note that while `-ftrapv` would seem equivalent, I've found it to be less reliable, particularly with compile-time checking.)
corndoge on April 14, 2020 [–]
And clang!
---
". It's 100% 8-bit-clean, and you should be able to use arbitrary UTF-8 sequences in your identifiers, or control characters for that matter. You can write your programs entirely in Sumerian cuneiform, with the exception of built-in things like parentheses, "if", and "define", if you have a cuneiform font installed." [3]
---
since we prefer compile-time speed to runtime speed, i guess we prefer vtables over monomorphization? ([4] says
" In general, for programming languages, there are two ways to translate a generic function:
1) translate the generic function for each set of instantiated type parameters, calling each trait method directly, but duplicating most of the generic function's machine instructions, or
2) translate the generic function just once, calling each trait method through a function pointer (via a "vtable").
The first results in static method dispatch, the second in dynamic (or "virtual") method dispatch. The first is sometimes called "monomorphization", particularly in the context of C++ and Rust, a confusingly complex word for a simple idea. ... These two strategies represent a notoriously difficult tradeoff: the first creates lots of machine instruction duplication, forcing the compiler to spend time generating those instructions, and putting pressure on the instruction cache, but — crucially — dispatching all the trait method calls statically instead of through a function pointer. The second saves lots of machine instructions and takes less work for the compiler to translate to machine code, but every trait method call is an indirect call through a function pointer, which is generally slower because the CPU can't know what instruction it is going jump to until the pointer is loaded. "
---
https://github.com/cosmos72/stmx implementation of transactional memory for SBCL (uses SBCL's vops)
---
in some languages (eg Java) 'optionals' might have some perf cost due to heap allocation, forcing the underlying type to be boxed, and disabling inlining. in other languages (eg Rust), not so much: https://pkolaczk.github.io/overhead-of-optional/
---
https://nathanotterness.com/2021/10/tiny_elf_modernized.html says that section headers can be removed and also these fields in the ELF header can be corrupted: 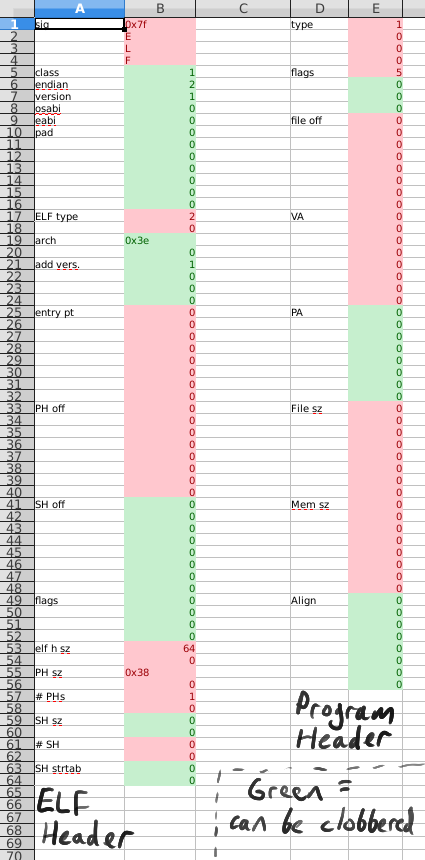 , and Linux will still run the program fine. [5] mentions the amiga HUNK executable format as something minimal and good. https://en.wikipedia.org/wiki/Amiga_Hunk suggests that the HUNK format needed a way to embed metadata: https://en.wikipedia.org/wiki/Amiga_Hunk#Metadata
, and Linux will still run the program fine. [5] mentions the amiga HUNK executable format as something minimal and good. https://en.wikipedia.org/wiki/Amiga_Hunk suggests that the HUNK format needed a way to embed metadata: https://en.wikipedia.org/wiki/Amiga_Hunk#Metadata
agnar says "The ELF format stands out as the most consistent, clear, robust and flexible of the object file formats. The other formats are full of patches and appear kludgy in comparison. I would recommend the ELF format for new applications." -- [6]
so mb start with ELF and HUNK and simplify ELF to get our own simple executable format
also look at Lua, JVM, .NET assembly binary formats
---
perf goals: aws lambda cold start and repeated usage without memory leak: https://filia-aleks.medium.com/aws-lambda-battle-2021-performance-comparison-for-all-languages-c1b441005fd1
---
i think i've been won over to little-endian; when you do arithmetic, you produce the lowest-order values first, so it's nice to be able to write those down, then increment the memory position that you are writing to, and then continue. Also, it's just pretty standard on today's machines.
but i have an issue with hex dumps/hex editors; 0xABCD in little endian would be viewed as CD AB, which is hard to read. There are two ways to fix this (without switching to big endian):
Consider also the right-shift/left shift convention, which implies that the rightmost bit is least significant. This suggests that the latter solution (lower memory addresses on the right) might be least confusing. Now bit 0 is the rightmost bit, and memory address 0 is the rightmost memory address.
In sum, writing memory with the lowest memory address is on the right and the highest is on the left is compatible with all of:
---
to summarize the previous, make a hexdump and hex editor that prints memory right-to-left
also, to make alignment easier to see, mb group bytes like this:
0123 4567 89AB CDEF 1111 2222 3333 4444 5555 6666 7777 8888
as you can see, pairs of bytes (16 bits) are put together without a space (b/c it's pretty easy to pick out each byte by eye within them, even without the space); then there is one space deliminting 2 byte chunks; between each 4-byte chunk there are two spaces; and between each 8-byte chunk there are 3 spaces. In the previous example line there are 66 characters, and if you added one more 8-byte chunk there would be 89; this shows that if you want to stay under 80 columns you can display 3 8-byte chunks in this fashion. If you wanted to put character translations to the right (going over 80 chars), you could put 32 chars like this:
0123 4567 89AB CDEF 1111 2222 3333 4444 5555 6666 7777 8888 ................................
For 102 characters overall. If you wanted to fit within 80 columns total you could have 16 bytes per line:
0123 4567 89AB CDEF 1111 2222 3333 4444 ................
(63 chars total; so we have room for additional metadata or UI elements and still fit within 80 columns)
---
hmm, nybble41 has a good point; if memory reads from right to left then English ASCII in the hexdump becomes backwards and hard to read [7]
---
disasm tool:
https://www.capstone-engine.org/
---
if we ever have an SSA-ish IR, keep in mind these arguments for block arguments over phi nodes:
(i also personally think phi nodes are less intuitive)
---
titzer 22 hours ago
| parent | next [–] |
LLVM and other compilers that use SSA but target a stack machine can run a stackification phase. Even without reordering instructions, it seems to work well in practice.
In Virgil I implemented this for both the JVM and Wasm. Here's the algorithm used for Wasm:
https://github.com/titzer/virgil/blob/master/aeneas/src/mach/MachStackifier.v3 reply
---
some interesting stuff here:
http://venge.net/graydon/talks/VectorizedInterpretersTalk-2023-05-12.pdf https://lobste.rs/s/ilpqe5/vectorized_interpreters_mrt_for_pl
the talk is by Graydon (the Rust Graydon) about what he thinks is an overlooked opportunity for PL design/implementation: internally represent arrays-of-structs as multiple arrays, and transform loops over those arrays-of-structs into vectorized loops over the arrays. If most of the program's time is in doing primitive operations within loops like that (if this is the "inner loop"), then the speed of program execution is dominated by that stuff, so compile/hyperoptimize that sort of thing, and it doesn't matter if you interpret or compile the "outer loop", so may as well interpret b/c that's easier. He gives the example of a Python program using numpy. It doesn't hurt too much to interpret most of it as long as the numpy ops that operate in a vectorized fashion on arrays are optimized/compiled/fast.
In the Lobste.rs discussion, andyc makes the point that that's all well and good when the time complexity of the program is dominated by large loops doing basic ops across long arrays, but for many programs you are dealing with trees and strings or trees of variable-sized strings (eg template processing in a web server). doug-moen and andyc talk about some papers they've seen where some compilers managed to flatten their tree processing and vectorize it, and they seem to agree that although that was awesome, it required unnatural and manual optimization. They opine that it would be nice if you could do a similar thing automatically, maybe by using the analogy for vectorized array ops on trees (which reminds me of Haskell).
They make the point that a language implementation can get a lot of perf savings by not dynamically allocating token nodes, parse tree nodes, IR nodes, etc as independent objects.
andyc talks about a related idea he had that i dont completely understand that is sort of like this: http://ezyang.com/slides/ezyang15-cnf-slides.pdf
andy says "I called it “squeeze and freeze”. A the cost of a traversal / copy, you get a compressed immutable block, that’s more type safe than Zig, and more memory safe than Rust idioms. It’s integrated with the garbage collector."
So it sounds to me like the idea of squeeze-and-freeze is for the programmer to identify data structures (for example, consider a tree) that should be “serialized” as follows:
the tree is originally represented by various independently allocated node objects connected by pointers
and then after squeeze-and-freeze transformation, it is represented as a struct-of-arrays (one array for each field within the node object type), where the nodes refer to each other with array indices instead of pointers, and nothing in the frozen tree is allowed to have any pointers to the outside (also, in the Haskell example, the tree must be fully evaluated, eg no lazy thunks in the middle of it). Also, the frozen tree is treated as a single unit by the garbage collector (so the GC doesn’t trace the references between nodes inside the tree, and it won’t reorder them either).
similar thoughts at: https://lobste.rs/s/8gxlj9/implementing_interactive_languages#c_xbi6oj
see also https://lobste.rs/s/ilpqe5/vectorized_interpreters_mrt_for_pl#c_62fk6b
---
https://www.scattered-thoughts.net/writing/implementing-interactive-languages/ is interesting in that i have similar goals (generally just be a low-latency interpreter, but i'm willing to go a little bit into compilation if it only increases the latency a little, and isn't too hard to write). But no conclusions. See also https://lobste.rs/s/8gxlj9/implementing_interactive_languages .
---
