![[Home]](http://www.bayleshanks.com/cartoonbayle.png)
i'm still wondering where to put stuff like thread control, a scheduler, IPC primitives like as seen in microkernels. Also, i'm thinking one layer should support only cooperative multitasking and only the next layer up from that should support preemptive multitasking, but which layers?
OVM should have preemptive multitasking provided, so if cooperative multitasking comes first, it has to be, at the highest, somewhere in the layer below OVM (even if just as a library).
BootX? provides a bunch of optional platform primitives, plus instructions that can be simply implemented as a few macroinstructions, so if scheduling is going to be programmed de novo by our toolchain on some platforms, then it should be on a layer higher than BootX?.
Which leaves LOVM as the only option. The issue there is that a big part of the point of LOVM is that it's too annoying to write e.g. a garbage collection directly in Boot (or Boot+BootX?). And the same thing applies to a scheduler.
hmm, i guess though that if it's a library in LOVM then that objection doesn't apply -- the library can itself be written in LOVM.
so it's looking like this stuff should be in a library in LOVM.
---
regarding smallstack size:
" Most Microchip PIC 8-bit micros have a hardware stack with a depth of only 8! (the size will vary for different PIC devices). Because the stack depth on these micros is so small it is used only for function calls. Each function call will consume one level of the hardware stack. The rest of the variables are pushed into a software stack which is automatically handled by the compiler....Your microcontroller (PIC16F1709) has a 16-level hardware stack, which is a fairly good depth." -- [1]
---
yknow, actually, let's take the macros out of the LOVM assembly and put them in Lo only.
done.
---
can we do this thing called 'NaN? tagging' that wren does? It apparently allows you to have a uniform 8-byte representation for 32-bit ints, 64-bit doubles, and x64-64 pointers, avoiding the need to box floats and either use pointers or >8 byte representations:
" A compact value representation #
A core piece of a dynamic language implementation is the data structure used for variables. It needs to be able to store (or reference) a value of any type, while also being as compact as possible. Wren uses a technique called NaN? tagging for this.
All values are stored internally in Wren as small, eight-byte double-precision floats. Since that is also Wren’s number type, in order to do arithmetic, no conversion is needed before the “raw” number can be accessed: a value holding a number is a valid double. This keeps arithmetic fast.
To store values of other types, it turns out there’s a ton of unused bits in a NaN? double. You can stuff a pointer for heap-allocated objects, with room left over for special values like true, false, and null. This means numbers, bools, and null are unboxed. It also means an entire value is only eight bytes, the native word size on 64-bit machines. Smaller = faster when you take into account CPU caching and the cost of passing values around. " -- https://wren.io/performance.html#a-compact-value-representation
that page links to http://wingolog.org/archives/2011/05/18/value-representation-in-javascript-implementations for further explanation, which explains that NaNs? have 53 bytes free, and x64-64 pointers have only 48 usable bits.
i don't want to hardwire it in, i just want to make it possible to do this.
---
"What kind of CPU features required for operating system?
Privilege protections? Virtual address? Interrupt?
...
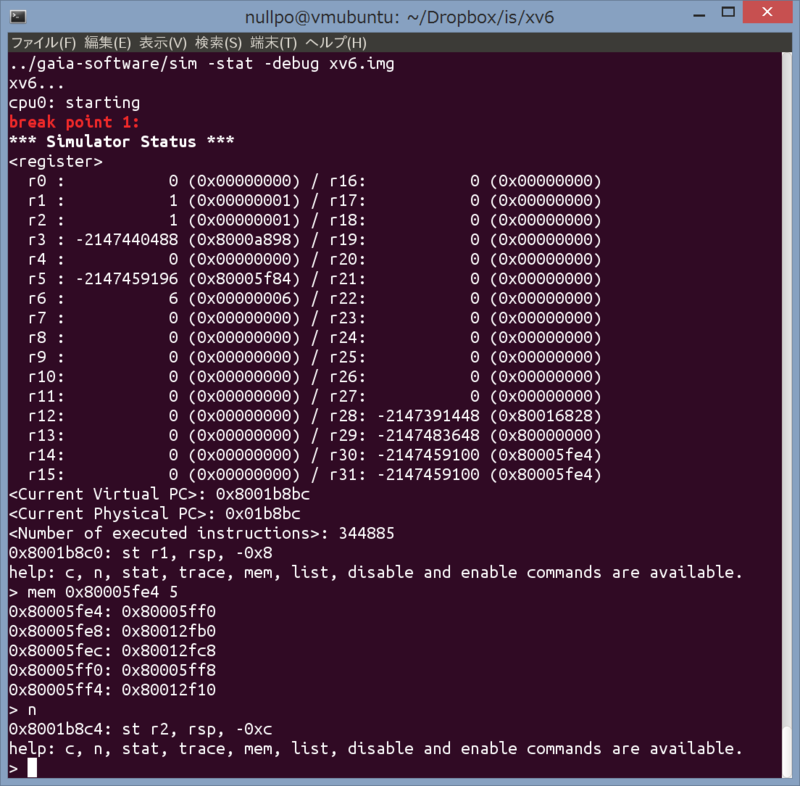
Based on this experience, I made the draft specifications of the interrupt and virtual address translation for our homebrew CPU. In order to keep it simple, we decided to omit hardware privilege mechanisms like Ring protection. ... I added interrupt simulation capability to our simulator which Wataru had made in the core part of CPU experiments, and also completed support for virtual address translation. This gave the simulator enough functionality to run the OS. ... When I ported Xv6 to MIPS, I had GDB, so it was rather OK, but our own simulator didn’t have any debug features, so it must have been very difficult to debug. Shohei couldn’t bear the difficulty of debugging, so he added a disassembler and a debug dump function to the simulator. After this, the simulator’s debugging features were rapidly upgraded by the OS team, and finally the simulator grew to look like the following picture.
---
For call3, if there are 4 operands, then you have to pass them in eight registers (or maybe eight positions on the small stack) because for each operand you need to pass both the value and the address to allow for all the various addressing modes. Alternately just the address of the operand is passed, and if the caller provides an immediate value then the implementation copies it into otherwise in accessible memory, and if the caller provides a register value, then the implementation copies it into otherwise inaccessible memory and copies it back into the register at the end of the call (Don't have to worry about it being in the register in the middle of the call if something else is called because instructions are "atomic")
so if You have two register banks and two small stacks and you need to have four extra arguments to CALL to say how many things need to be saved / Or on the other hand 4 extra arguments to ENTRY to say how many callee-saved things need to be saved. Or you could just say that SMALLSTACK is caller-saved, and then don't provide facilities for in caller saving, which means you'd only have two things to specify and only upon ENTRY.
alternately, you could specify how many SMALLSTACK locations in each bank will be needed in ENTRY and then a primitive could be provided to free that many locs in SMALLSTACK one way or another; maybe by popping stuff from the top of the stack, or maybe by spilling stuff from the bottom of the stack; the convention would be that you can't make any assumptions that you can access the callers stack from the Callee (negating the opportunity to use the stack to pass arguments through many levels of calls).
---
some other ideas for SMALLSTACK:
---
Regarding the advantage of multiple stacks, the stack computers book just says "In the case where the parameter stack is separate from the return address stack, software may pass a set of parameters through several layers of subroutines with no overhead for recopying the data into new parameter lists.
An important advantage of having multiple stacks is one of speed. Multiple stacks allow access to multiple values within a clock cycle. As an example, a machine that has simultaneous access to both a data stack and a return address stack can perform subroutine calls and returns in parallel with data operations." [2]. Neither of those are too important to us (the first is provided by argument registers, and the second is lower-level than we care about).
---
reflecting on the previous section, i think that for us, the only important advantages of SMALLSTACK is:
---
more notes on how many registers we need/ how large smallstack should be
I keep coming back to register and stack sizes of 16. If we had two register banks and two stack banks then if each of those wears a size 16 we have 64 locations total which is exactly 1/4 of 256 allowing easy addressing of registers by the implementation if everything is 32 bits. if Each register bank is a size 16 and that leaves eight for callersave registers and 8 for callee-save
the riwcv c extension has shortcuts for the eight most popular registers.
The riskv base has 32 int registers, And E profile has s16
---
"As a practical matter, a stack size of 32 will eliminate stack buffer overflows for almost all programs." -- [3]
---
"With how many local variables must a C compiler be able to deal? "
"The C standard (C99 and C11) states, in the Translation Limits section, that a compiler implementation must be able to handle at least “511 identifiers with block scope declared in one block.” (See C99 and C11, section 5.2.4.1. Previously, in C89/90, the limit was 127 identifiers, stated in section 5.2.4 Environmental Limits.) "
" Cliff Click , Wrote my first compiler at age 15, been writing them for 40 years Answered January 5, 2018 · Author has 100 answers and 99.4K answer views
Interesting answers below, but my experiences vary significantly. The standard limit is useless, real code that people really wrote and really want to compile routinely exceeds several hundred variables. No judgement from the compiler on the quality or maintainability of such code, we just did our best effort to make it work.
For machine generated code, the sky’s the limit. On at least one compiler I worked on, we raised the limit from 32K (16-bit signed short) to 64K (removed the sign extension issues) and finally switch to a 4-byte index to survive really abusive machine generated code.
Cliff 661 viewsView 13 Upvoters "
" Ed Bell , C is my language of choice. Answered December 30, 2017 · Author has 4K answers and 1.3M answer views
I know of no limit intrinsic to the standard, but the other answers about the stack are spot on.
Years ago, when I was writing code for MS-DOS using Tubo C, my heavily recursive algorithm required I bump the STKLEN up to 2048 to eliminate stack overflows.
So, if there is a limit, there should be a workaround. 91 views · Answer requested by Pedro Izecksohn "
---
so those make me think that maybe 8 callee-save registers in each bank just isn't enough. I think we really want at least 64 callee-save locations in total, so if SMALLSTACK isn't going to have any, that implies that each bank should have at least 32 callee-save locations, so 64 total locations. So we'd be looking at 2 banks of 64 registers and 2 SMALLSTACKS of 64 each.
But now that sounds like overkill.
So maybe 2 banks of 32 registers each (that's no worse than RISC-V, which has 32 base regs total; here, each register type (int, ptr) would have 32, so in fact it's already more regs than RISC-V), and 2 SMALLSTACKS of 32 locs each. For a total of 128 locations. Now we have 16 callee-save locs per bank; and it takes only one byte in ENTRY to specify how many callee-save locs we need to spill across both banks.
This also has the advantage that it uses up the greatest number of registers possible while still one power-of-two for the implementation (assuming we only have one byte to store register specifiers). This also has the advantages that each bank of callee-save things is only size 16, and so the number of callee-saves used in two such banks can be specified in one byte (via 2 4-bit fields)
---
And we could still decide to make half of each SMALLSTACK callee-save. That would give each subroutine a total of 32 callee-save locations of each type, handily beating RISC-V (which presumably has only ~16 callee-save total). What would that look like? The convention could be:
you could consider using two more bytes to specify the max number of caller-saves used, so that some implementations know how many registers really need to be allocated here; not sure that's worth it though.
for the caller-save portions, does the caller really need to clear the stack, or can they rely on the callee to do that only if they really need it? the latter only makes a lot of sense if there is a quick 'wipe stack' instruction.
however one issue with this is that you might not want the callee-saves on each SMALLSTACK to be beneath the temporaries. Maybe you'd want 4 SMALLSTACKS (2 for each reg bank). This actually isn't too crazy on the addr modes; in SMALLSTACK addr mode you only need an offset of 16, so with one-byte operands you have 4 bits free to choose among 4 SMALLSTACKS (and you only really need 2, since you have different instructions for each bank; mb we can have 2 MEMSTACKS also (actually for the MEMSTACKS, since they mix both ints and ptrs, you probably really want at least 2 4-bit fields so that you can indicate up to 16 ints and up to 16 ptrs to skip over; which means you do want a separate instruction for those)).
---
"While 16-bit instructions may seem wastefully large, the selection of a fixed length instruction simplifies hardware for decoding, and allows a subroutine call to be encoded in the same length word as other instructions. A simple strategy for encoding a subroutine call is to simply set the highest bit to 0 for a subroutine call (giving a 15 bit address field) or 1 for an opcode (giving a 15 bit unencoded instruction field" https://users.ece.cmu.edu/~koopman/stack_computers/sec3_2.html
---
it's kinda cool to have 2 SMALLSTACKS of each type, but otoh it might make sense to have just 1 SMALLSTACK of each type and have a convention of having half of it free upon calling. One of the points of a stack is that you don't have to save and restore registers because 'your' registers are numbered from the TOS at the time you are passed control.
note that this suggests that even when accessing deep stack like registers (eg read and overwrite instead of POP and PUSH), that the items should still be indexed according to their distance from TOS
--
oo, just realized! fitting all these things in one byte allows you to access both registers and SMALLSTACKs in ANY addressing mode, rather than devoting extra addressing modes to them. You can even fit both kinds of SMALLSTACK access! e.g.:
(and we still have 63 spaces left; maybe these could be left to the implementation, and/or maybe some of these could be positions on MEMSTACK!)
---
so it's looking like ENTRY has 3 operands:
maybe the 4th could be int/ptr MEMSTACK space needed..
and btw i realized, to access a position on MEMSTACK, you don't need to sum int spaces to skip over, ptr spaces to skip over, if the implementation can keep track of that (and probably the implementation will keep all the ints together and all the ptrs together); then you only need to specify int vs ptr (1 bit), plus an index as to which integer/ptr.
---
mb we don't need to provide a stack depth primitive as long as we provide:
this would allow some implementations to eg use a circular buffer without tracking stack depth (when they spill they might have to assume that the entire circular buffer is in use tho).
if a non-circular buffer, the stack ptr and hence stack depth could be discovered from inspecting the in-memory copy of the stack (which might have a defined representation?); but if a circular buffer, it would always appear to be at the maximal depth
or, to help in not over-allocating memory when copying stack to memory (assuming the user pre-allocates and passes a pointer ot the empty space), we could have a stack depth primitive, but make it optional; it's okay for the implementation to always return the max (which is 32 items)
---
https://keleshev.com/ldm-my-favorite-arm-instruction/
ldm is 'load multiple'. There is also stm , store multiple. push and pop also have 'multiple' forms. These can all do any subset of the 16 registers.
arm64 only allows dealing with pairs of registers.
---
"
Paged Segments
The memory model introduced by the 386 is wonderfully Byzantine. It supports not just paging, but segmentation. If you've read an operating systems textbook, you'll know that operating systems prefer paging, because it makes fragmentation of physical memory much rarer. Programmers, however, prefer segments.
For example, consider the mprotect() system call, which alters the permissions on a range of memory. When you call it on a system using paging, the permissions must be set on a page boundary, typically 4KB, but sometimes much larger—64MB on some mainframes. If you're protecting a small structure, the side effect is that you also change a lot of unrelated memory. This situation is particularly bad in a language like C, where malloc() may service two requests from the same page, preventing you from setting different permissions on them.
In contrast, segments are variable-sized. You can set permissions on any arbitrary block of memory with x86 by using the segmentation mechanism. The aim was for programmers to use segments and not care about pages, while operating systems would use pages but not care about segments. The segments map from a segment address to a linear address, which is then mapped to a physical address by the paging mechanism.
With an object-oriented language, you might use a new segment for each object, using the segment ID instead of object pointers, and then have automatic bounds checking on every instance variable access and every array access.
Even better, you could implement a copying garbage collector trivially, by marking the segment as no-access during the copy and then waiting on a lock in the segmentation-violation signal handler. Because all accesses would be segment-relative, you would never have to worry about inner pointers—every access would be a segment ID and an offset within that segment.
Unfortunately, this plan didn't work out. C didn't allow segments, so only systems like iRMX, written in PL/M, could use them. More seriously, you were limited to 8192 segments per process, with another 8192 global segments. This number is too low for even a relatively simple object-oriented system. Rather than increasing this limit with x86-64, AMD simply removed the segmentation system.
The most frustrating thing about the segmentation limit is that Intel produced another chip, the iAPX 432, which introduced the memory model found on modern IA32 chips. Released in 1981, it was only three years after the 8086 and four years before the 80386. It had a similar segmentation system to the previous chip, but provided 24-bit segment identifiers, giving almost 17 million segments per program. More than enough for a lot of programs—certainly more than enough in the 1980s, although that number might be in need of some expansion by now. " -- https://www.informit.com/articles/article.aspx?p=1676714&seqNum=2
---
toread: https://www.informit.com/articles/article.aspx?p=1077906
---
" RISC-V SIMD, as opposed to classic SIMD, is really something to be excited about. " -- comment on https://www.anandtech.com/Show/Index/15036?cPage=5&all=False&sort=0&page=1&slug=sifive-announces-first-riscv-ooo-cpu-core-the-u8series-processor-ip
" High-performance computing has been largely taken over by GPUs, which are in essence super-wide SIMD machines, using predicate vectors for much of its flow control. (Predicates being only late additions to SSE and Neon) The scalable vector proposal for RISC-V is by some considered so promising that there have been even been talks about building GPUs based around the RISC-V SIMD ISA -- optimised for SIMD first and general-compute second. " -- comment on https://www.anandtech.com/Show/Index/15036?cPage=5&all=False&sort=0&page=1&slug=sifive-announces-first-riscv-ooo-cpu-core-the-u8series-processor-ip
---
A negative comment on RISC-V, from https://www.anandtech.com/Show/Index/15036?cPage=5&all=False&sort=0&page=1&slug=sifive-announces-first-riscv-ooo-cpu-core-the-u8series-processor-ip:
Wilco1 - Wednesday, October 30, 2019 - link ... My point is it's the same people repeating the exact same mistakes. It has the same issues as MIPS like no register offset addressing or base with update. Some things are worse, for example branch ranges and immediate ranges are smaller than MIPS. That's what you get when you're stuck in the 80's dogma of making decode as simple as possible...
A comment on what ARMv8 has changed that is good, from https://www.anandtech.com/Show/Index/15036?cPage=5&all=False&sort=0&page=1&slug=sifive-announces-first-riscv-ooo-cpu-core-the-u8series-processor-ip: ... There is a HUGE amount of learning that informed ARMv8, from the dropping of predication and shifting everywhere, to the way constants are encoded, to high-impact ideas like load/store pair and their particular version of conditional selection, to the codification of the memory ordering rules. Look at SVE as the newest version of something very different from what they were doing earlier.
---
so one of those comments complains about RISC-V branch offset range and immediate ranges in RISC-V, compared to MIPS. How large are those exactly?
According to https://en.wikipedia.org/wiki/MIPS_architecture ,
[4] says "21-bit branch displacements (insufficient for large applications - e.g. web browsers - without using multiple instruction sequences and/or branch islands)"
and one of the comments praises the AArch64 (ARMv8) immediate encoding. Some of which seems straightforward to me, and some of which baroque: https://dinfuehr.github.io/blog/encoding-of-immediate-values-on-aarch64/ . On ARMv7 (and earlier) they have that 'barrel shifter' stuff; 12-bit immediates broken into 8 bits and a 4-bit rotation: https://alisdair.mcdiarmid.org/arm-immediate-value-encoding/ . So presumably the comment was focusing on the straightforward part of saying it's good that ARMv8 dropped the barrel shifter (? although they separately mentioned the dropping of shifting as if it was a different thing).
---
"...But in fairness it looks like conditional move might be getting added to the bit manipulation RISC-V extension which would fix one big pain point."
---
this guy's intro suggests that people really like ARM NEON or maybe ARM v8 (AArch64) in general: https://www.cnx-software.com/2017/08/07/how-arm-nerfed-neon-permute-instructions-in-armv8/
---
could achieve a self-sync code by giving up one bit in each byte (so that a zero indicates the start of a new instruction, and a 1 indicates a continuation). i think that's probably too expensive to be worth it tho. Could achieve a code that would eventually self-resync with less cost by requiring 64-bit sync annotations every so often.
" Dylan16807 on Sept 14, 2018 [–]
But do any self-synchronizing instruction sets exist? (And are in commercial silicon?) It seems like it would be very annoying for density and constant-encoding reasons with 8 bit code units, and none of the variable 16/32 bit encodings I can name do it either.
dezgeg on Sept 15, 2018 [–]
The PIC18 instruction set has this property. Most instructions take up a single 16-bit instruction word, but the few ones that take up 2 words all have the 0b1111 in the high bits of the second word, which would execute as a NOP if branched into.
This encoding is presumably a consequence of the instruction set containing conditional skip instructions. That is, the skip instructions don't have to parse the instruction stream for 2-word instructions but can always just skip a single instruction word and let the second word execute as a NOP. " -- [5]
---
" Despite great effort being expended on a uniform encoding, load/store instructions are encoded differently (register vs immediate fields swapped)
It seems orthogonality of destination register encoding was preferred over orthogonality of encoding two highly related instructions. This choice seems a little odd given that address generation is the more timing critical operation." -- [6]
To elaborate on that, in RISC-V LOAD and STORE encodings are (where the number at the end of each word is the bitwidth of the field:
in other words, i think he is complaining that in one encoding the offsets are split up and in the other they aren't, presumably having something to do with keeping the 'dest' in LOAD in the same place as in other instructions with a dest. I think he is saying that it would be better if, everytime there is an address, that address and everything needed to compute it (eg the offset) would be in the same place.
---
i've seen a lot of complaints that RISC-V doesn't support an address mode with Rbase+Rindex << Scale. We should support that.
---
" 17:27:26 <Bitweasil> Crucially, unlike prior attacks, #LVI cannot be transparently mitigated on current CPUs and requires expensive compiler mitigations that insert an LFENCE after potentially *every* memory load and blacklist the x86 RET instruction-- we measure overheads of factor 2 up to 19(!)"
---
"In the x86 instruction set, there is one instruction for all of these, cmp (which sets a bunch of flags), then you use the appropriate jxx or setxx instruction to look at the flags that interest you (e.g., for the conditional jumps, you use jb, jbe/jna, ja, jae/jnb for unsigned ("below"/"above"), and jl, jle/jng, jg, jge/jnl for signed ("less"/"greater"))." -- https://stackoverflow.com/questions/18647982/why-do-branch-instructions-use-the-status-register
---
another idea would be to say that overflow on 32bit input leads to an undefined value that can be immediately followed by an and with 2^32 to produce the result mod 32; but other further computation with such an undefined value leads to undefined behavior. this would allow for implementations that crash on overflow but use 64bit ints. 32bit processors can simply specialcase elide the AND 2^32. could go further and require an immediately following and 2^32 to avoid a crash, allowing implementation s that crash on overflow to detect when 32bit overflow is needed.
i dont think i'll do that though.
---
now i have more of an appreciation for Agner's
https://www.forwardcom.info/comparison.html
forwardcom is too complicated for me, though
forwardcom doesn't use a link register:
" If we decide to have a link register then it should be a special register...If the link register is included as one of the general purpose registers then it will betempting for a programmer to save it to another register rather than on the stack, and then endthe function by jumping to that other register. This will work, of course, but it will interfere with theway returns are predicted. ...
The only performance gain we get from using a link register is that it saves cache bandwidth bynot saving the return address on leaf function calls....The disadvantage of using a link register is that the compiler has to treat leaf functions and non-leaf functions differently, and that non-leaf functions need extra instructions for saving and restor-ing the leaf register on the stack.Therefore, we will not use a link register in the ForwardCom? architecture "
the forwardcom calling convention is surprisingly similar to the one i already came up with myself
forwardcom has a C-like assembler syntax but it's lowerlevel than Lo; registers don't have variable names (although maybe other stuff in memory does?), and each statement much correspond to a single instruction
i think every instruction can be predicated
---
recently i've been thinking the number of registers in LOVM should be tightly constrained so as not to have too much state. So, maybe 16 registers in each bank, plus two banks of 16-item SMALLSTACKs. However, to me this is a waste of the 32-bit and 64-bit encoding -- recall that i had been imagining that even the 32-bit encoding would permit 255 locals, and now we are saying not just that the 32-bit encoding is only being used for 8 registers times two banks, but also that even the 64-bit encoding only gets 16 registers in 2 banks and 2 smallstacks.
i think i should go back to confining Boot to the 16-bit encoding, and putting LOVM in the 32-bit encoding, and saving the 64-bit encoding for OVM.
Recall that the main issue with this was that we won't be able to fit all of the BootX? instructions that we want to into the remaing 64 opcodes. Which means that we will be back to adding some connections to the target at the LOVM level, rather than saying that a full BootX? implementation is the entire interface between Oot and the target platform native primitives. I think it's probably worth it though -- it just feels wrong to be so wasteful of encoding space.
Currently we have 47 instructions in Boot, which means we have room for 17 more in BootX?.
The bright side is that we have tons of room for syscall extensions in BootX?.
Since this is a big, multi-layer change, I'm going to archive the current versions of the reference docs.
cd ~prog/oot/boot cp boot_reference.md ~/oot/bootReferenceOld201018.txt cp bootx_reference.md ~/oot/bootxReferenceOld201018.txt cdo cp ootLovmReference.md ootLovmReferenceOld201018.md
---
RISC-V is little-endian in the instruction encoding in that it puts the opcode (which must be read first) in the LAST byte of the instruction. i don't think we should do that, because we have a variable-length encoding once we get to LOVM; so we need to be able to read out the length from the FIRST byte. Once we have to do that, may as well put the opcode there as well, right?
---
i was thinking of doing this:
but actually i think that doesn't work, because what about load/store? if we have instructions to specifically load and store an int16, then we should have ones to specifically load/store an int32.
so just leave it at int32.
---
if we're not allowed to do arithmetic on code pointers, and all code pointers are relative, and we can only get the PC with lpc and the offset in that instruction is small, and if there are no pointer immediates in the code, then how do we load a label?
i think we need an lpc32 instruction to load the PC with a given offset so that we can load labels (alternately, the offset could be applied to the beginning of the current code segment). I added lbl32.
Also i added lm so that we could load small immediates.
should offsets be relative to the current instruction pointer, or to the beginning of the code segment? Let's do the PC, in order to avoid making the implementation keep a pointer to the beginning of the code segment in a hidden register.
---
so now that Boot and BootX? are being hard-restricted to 64 instructions, should i include:
?
and/or floating point BootX?? and/or 64-bit BootX?? and/or atomics?
i'm thinking that the app things could NOT be included, if there is not room for both those and some other stuff that i really want. The reason is that Boot is meant to be easy to bootstrap, not an actually good/efficient assembly language.
Otoh, since Boot(X) is also the 16-bit encoding within LOVM, it is also somewhat important to make it efficient. And we probably cant fit FP AND 64-bit AND atomics, so something important will have to be left for LOVM.
also, Boot is focused on the sort of operations that are necessary for the bootstrapping toolchain; and these same sorts of things (data shuffling, basic control flow, 32-bit integer and pointer arithmetic) are the bread & butter of most programs. So there's an argument for focusing on those. And, there's something to be said for choosing one area and doing it right; without an efficient way to do immediate and scaled offsets, Boot is not really good at anything (except being easy to implement); with them, it might at least be good at the 'bread & butter' areas that i gave above.
and the 8-bit short encoding wont save us here because these instructions really benefit from having 3 operands
so i think i'll include those pointer arithmetic shortcut operations.
this is the same reason for including immediate constant and jump variants for a variety of sizes; except those are perhaps less essential b/c the 8-bit encoding instructions could do those.
in fact, i think i'll take out the 16-bit ones.
---
so currently we are at 47 instructions, so we have 17 spaces left.
we want bootx to have 2 integer division instructions (could settle for just 1):
| integer division | div (and mb rem) |
the minimal fp instructions i can come up with are 11:
fadd fsub fmul fdiv fclass fcmp itof ftoi fcp fld fst
and we want 4 misc instrs:
| misc | log break hint impl |
and probably also a fifth, a MORE instruction
and we want 6 atomics:
| atomics (release consistency) | lprc lwrc sprc swrc casrmwrc casprmwrc |
adding those up:
24 new instructions
and we'd also like 64-bit ints, and a few quick i/o instructions.
so we're way over. We can't do all of:
we can't even do all of:
Most of these can really use a bunch of operands, so it's not satisfying to bury them in MORE (although that would be POSSIBLE for many of them, except for some of the atomics).
and it would be nice to leave some room for common efficiency instrs like push, pop, call, ret. In fact, those should probably be prioritized, for the same reasons as prioritized scaled offset pointer arithmetic. However, those are 2-operand things that could fit in a MORE.
looking at my instruction frequency pl chapter, i see push, pop, call, ret in the list of top instructions. For floating point, i only see fld and fst (although mb i wouldnt recognize all the x86/x87 FP mnemonics)https://mitsloan.mit.edu/ideas-made-to-matter/cities-strong-social-distancing-see-stronger-economic-recoveries. Integer division is not common. Concurrency stuff doesn't come up either, but that could be an artifact of the study (x86 uses lock prefixes for some things, also it has a strong degree of always-on atomicity).
the misc instructions are probably pretty important, but rare, and maybe some (BREAK and LOG?) could go inside MORE.
and mb we can just leave MORE an optional until LOVM (e.g. not in the Standard profile).
---
we're almost there if we slim down a little:
| integer division | div |
| misc | more impl |
| atomics (release consistency) | lprc lwrc sprc swrc casrmwrc casprmwrc |
that's 22
mb we could forgo ptr atomics?
| integer division | div |
| misc | more impl |
| atomics (release consistency) | lwrc swrc casrmwrc |
also i guess we can do bitwise NOT with bitwise XOR
that's 18
hmm.. you could combine fclass and fcmp if the result of fcmp is a whole status register, instead of just trinary comp
Some of the floating point ops could be stuffed into more
---
i guess the thing to do then is to put off this decision for now (and focus on the syscall extensions for BootX?).
or, mb not wait.. we're so close
---
RISC-V 'G' profile (extension set) contains: mul, div, atomics, single and double precision.
So our wish list here is not far off.
"Debian and Fedora agreed on RV64GC as base target, the C is compressed instructions (what ARM calls thumb). " [7]
---
justification for including multiplication:
FUZxxl 1 point · 1 year ago
or example, the MSP430 and 8051 instruction sets are quite popular for very low-end cores, and is probably a better choice for the type of application where you might omit multiply/divide.
The 8051 has both a multiplication and a division unit, most MSP430 parts have a multiplication unit as a peripheral accessed through magic memory locations. level 6 psycoee 1 point · 1 year ago
Yeah but the kind of multicycle multiplication/division the 8051 has is basically the same as doing it in software, and very cheap to implement. The msp430 is definitely a more capable core even without multiplication. Either way, my point is that 32 bit processors are not the best choice for extremely low end applications.
---
" The trick is designing an instruction set that has complex instructions that are actually useful. Indexing an array, dereferencing a pointer, or handling common branching operations are common-enough cases that you would want to have dedicated instructions that deal with them.
The kinds of contrived instructions that RISC argued against only existed in a handful of badly-designed mainframe processors in the 70s, and were primarily intended to simplify the programmer's job in the days when programming was done with pencil and paper.
With RISCV, the overhead of, say, passing arguments into a function, or accessing struct fields via a pointer is absolutely insane. Easily 3x vs ARM or x86. Even in an embedded system where you don't care about speed that much, this is insane purely from a code size standpoint. The compressed instruction set solves that problem to some extent, but there is still a performance hit. " -- [8]
---
not relevant, but interesting fact that i wanted to save somewhere:
"There are no integer multiplies in a straightforward circuity AES implementation, just shifts, xors, negations, and ANDs." -- https://www.reddit.com/r/programming/comments/cixatj/an_exarm_engineer_critiques_riscv/evceu0i/
---
" Then why doesn't RISC-V have complex addressing modes?
Most of these are fairly clear. You don't want instructions that read more than two instructions ((i think he meant input operands)) in a cycle, because it means you require an extra register file port and make decode more complex for the very, very small processors. The one I'm less clear about is a load of just a+b, which is still only two reads one write, so I checked Design of the RISC-V Instruction Set Architecture.
We considered supporting additional addressing modes, including indexed addressing (i.e., rs1+rs2). However, this would have necessitated a third source operand for stores. Similarly, auto-increment addressing modes would have reduced instruction count, but would have added a second destination operand for loads. We could have employed a hybrid approach, providing indexed addressing only for some instructions and auto-increment for others, as did the Intel i860 [45], but we thought the extra instructions and non-orthogonality complicated the ISA. Additionally, we observed that most of the improvement in dynamic instruction count could be obtained by unrolling loops, which is typically beneficial for high-performance code in any case.
"
---
hey there's a reddit called 'cpudesign'
https://www.reddit.com/r/cpudesign/
the posts on the MRISC32 over there get a lot of upvotes
should also look again at OpenRISC? sometime i guess
---
openrisc: "Two simple addressing modes: Register indirect with displacement and PC relative"
---
" All 32-bit ops on x86 zero extend into the upper half of the register.
There are various reasons to prefer zero extend, primarily that 32-bit leave the top half of the register completely static and you can get good power savings there "
" Fabian Giesen @rygorous · Jul 25, 2019 Replying to @erincandescent The sign extend thing really bugs me because if nothing else, it means the cost gradient for uint32 vs int32 for array inds etc. is in the opposite direction from the way it is on ARM and x86_64 (yay gratuitous differences that actually have an impact on cross-platform HLL code) "
---
"
Geoff Langdale @geofflangdale Replying to @erincandescent
@TheKanter? and 2 others Interesting. As a SIMD guy, I can't say their take on SIMD/vectors floats my boat either. Very tailored for the elegant large-scale vector ops, but I've spent a whole career doing grubby things with quick SIMD ops that don't fit the big-vector model. x86 is great for that. "
---
any alternatives to ELF or DWARF?
here's an alt to DWARF called CTF:
https://lwn.net/Articles/795384/
also mb lookup whatever that thing was about wasm source maps
https://hacks.mozilla.org/2018/01/oxidizing-source-maps-with-rust-and-webassembly/
srcmaps encode the DELTAS of the line numbers since the last previous occurence, so it does make sense for them to be variable length.
---
i feel like i have a shaky understanding the interaction of 32-bit and 64-bit operations, signed and unsigned, zero-extend vs sign-extend, and whether the registers are 32- or 64-bit, and the implications for forward compatibility of programs which were written assuming 32-bit registers but end up running on 64-bit registers.
let's work thru some examples. make it 8-bit vs 16-bit for quick notation.
a program is written for 8-bits. it's running on 8-bit registers.
it loads -1 from 8-bits of memory, which is represented as 0xff in memory. This is represented as 0xff in register. It adds 1 to this. Unsigned, this wraps around from 0xff to 0. Signed, this adds 1 to -1 and gets 0. this is written to memory as 0x00. 0 is the expected answer and if you bez, 0 is detected.
let's say the same program is running on a machine with 16-bit registers. the forward compatibility condition is that we want the same result to occur.
| 16-bit unsigned add), write 8-bits, also expect 0: on 16-bit machine |
it loads -1 from 8-bits of memory, which is represented as 0xff in memory. i'm not sure how this is represented in the register; i guess this is the zero-extend or sign-extend question. let's try both.
| 16-bit unsigned add), also expect 0: on 16-bit machine, zero extend |
it loads -1 from 8-bits of memory, which is represented as 0xff in memory. it's zero-extended to 0x00ff in the register. It adds 1 to this. Unsigned 16-bit addition, the result is 255+1=256=0x0100. Signed 16-bit addition, this gets the same result of 0x0100. The lower 8 bits are written to memory as 0x00. HOWEVER, if you do a bez, this fails. FAIL
| 16-bit unsigned add), also expect 0: on 16-bit machine, sign extend |
it loads -1 from 8-bits of memory, which is represented as 0xff in memory. it's sign-extended to 0xffff in the register. It adds 1 to this. Unsigned 16-bit addition, the result is 65535+1=0. Signed 16-bit addition, this is -1+1 = 0. The lower 8 bits are written to memory as 0x00. if you do a bez, this succeeds. PASS
let's try doing 8-bit addition via doing 16-bit addition and then ANDing with the mask 0xff:
| 8-bit unsigned add via 16-bit then AND ), also expect 0: on 16-bit machine, zero extend on load |
it loads -1 from 8-bits of memory, which is represented as 0xff in memory. it's zero-extended to 0x00ff in the register. It adds 1 to this and then ANDs with 0xff. Unsigned 16-bit addition, the result is 255+1=256=0x0100 AND 0xff = 0. Signed 16-bit addition, this gets the same result of 0. The lower 8 bits are written to memory as 0x00. if you do a bez, this succeeds. PASS
| 8-bit unsigned add via 16-bit then AND), also expect 0: on 16-bit machine, sign extend on load |
it loads -1 from 8-bits of memory, which is represented as 0xff in memory. it's sign-extended to 0xffff in the register. It adds 1 to this. Unsigned 16-bit addition, the result is 65535+1=0 AND 0xff = 0. Signed 16-bit addition, this is -1+1 = 0 AND 0xff = 0. The lower 8 bits are written to memory as 0x00. if you do a bez, this succeeds. PASS
so that works. What if we did 8-bit addition by only paying attention to the lower 8 bits of input and also output (so the same AND as before, but also do that AND upon the input)?
| 8-bit unsigned add via ignore ), also expect 0: on 16-bit machine, zero extend on load |
it loads -1 from 8-bits of memory, which is represented as 0xff in memory. it's zero-extended to 0x00ff in the register. It adds 1 to this by ignoring the high bits. Unsigned 8-bit addition, the input is seen as 255 + 1, the result is 255+1=256=0x0100 AND 0xff = 0. Signed 8-bit addition, the input is seen as -1 + 1, the result is 0xff = -1 + 1 = 0. The lower 8 bits are written to memory as 0x00. if you do a bez, this succeeds. PASS
| 8-bit unsigned add via ignore), also expect 0: on 16-bit machine, sign extend on load |
it loads -1 from 8-bits of memory, which is represented as 0xff in memory. it's sign-extended to 0xffff in the register. It adds 1 to this. Unsigned 8-bit addition, the input is seen as 0xff + 1, the result is 255+1=0x0100 AND 0xff = 0. Signed 8-bit addition, the input is seen as -1, the result is -1+1 = 0 AND 0xff = 0. The lower 8 bits are written to memory as 0x00. if you do a bez, this succeeds. PASS
So these two methods of doing 8-bit addition on 16-bit registers appear to be equivalent, and to be sufficient.
so conclusion so far:
ok, on erincandescent's commont and risc-v sign extend/zero extend:
here's er comment:
"RV64I requires sign extension of all 32-bit values. This produces unnecessary top-half toggling or requires special accomodation of the upper half of registers. Zero extension is preferable (as it reduces toggling, and can generally be optimized by tracking an "is zero" bit once the upper half is known to be zero)"
here's something that the RISC-V RV64I spec says:
" The compiler and calling convention maintain an invariant that all 32-bit values are held in asign-extended format in 64-bit registers. Even 32-bit unsigned integers extend bit 31 into bits 63through 32. Consequently, conversion between unsigned and signed 32-bit integers is a no-op,as is conversion from a signed 32-bit integer to a signed 64-bit integer. Existing 64-bit wideSLTU and unsigned branch compares still operate correctly on unsigned 32-bit integers underthis invariant. Similarly, existing 64-bit wide logical operations on 32-bit sign-extended integerspreserve the sign-extension property. A few new instructions (ADD[I]W/SUBW/SxxW?) arerequired for addition and shifts to ensure reasonable performance for 32-bit values "
i think RISCV ADDW etc are 32-bit operations. So i think the assembly term 'ADD' means 32-bit in RV32I but 64-bit in RV64I. However, 32-bit quantities are sign-extended on load, so we don't hit the failure case in the previous section.
so is this saying their solution to the above quandary is just the opposite of what i'm suggesting:
now i still dont understand this twitter comment:
https://twitter.com/BruceHoult/status/1154869837790732288 Bruce Hoult @BruceHoult? · Jul 26, 2019 Incidentally, AFAIK x86 does *not* favour zero extension, it needs explicit sext or zext, so is equally bad for both. The B extension will make RV a lot more neutral for most uses of 32 bit unsigned values on rv64. RV is far from the first to allow arbitrary LR, and it's useful.
---
what if we had done NEITHER extend upon load?
| 8-bit unsigned add via 16-bit then AND ), also expect 0: on 16-bit machine, no extend on load |
it loads -1 from 8-bits of memory, which is represented as 0xff in memory. it's 0xabff in the register. It adds 1 to this and then ANDs with 0xff. Unsigned 16-bit addition, the result is 44031+1=44932=0xac00 AND 0xff = 0. Signed 16-bit addition, this gets the same result of 0: 0xabff = -21505, + 1 = 0xac00 = -21504, AND 0xff = 0. The lower 8 bits are written to memory as 0x00. if you do a bez, this succeeds. PASS
so this is actually fine.
so it looks like we dont need to do any extend/dont care about the extend as long as we AND with the bitmask of the width we want after each arithmetic operation.
---
should we add load register that does neither sign nor zero extend?
so, i'm not 100% sure i got everything, but here is what things look like:
and the answers to some of my previous Qs:
---
yeah, not sure what to do about that. i think the best that can be done is for the dissassembler to always show unsigned with a comment showing the signed value
---
nah/old:
---
i'm questioning the value of having separate banks for int/ptr registers
---
SMALLSTACK could also just be the ordinary registers, accessible with register addressing mode, with a 'stack pointer' to one of them (and implied UNDEF upon pop)
---
some guidance on addr modes:
" I only want to comment about the addressing modes, because many other ISA proposals, including RISC-V, do not seem to have any clue about how they are used in real programs.
There are only 2 possible choices for a set of addressing modes that would allow writing a loop with a minimum number of instructions.
The first possible choice coincides with the subset of the VAX 11 addressing modes implemented in Intel 80386, which, like in the Agner proposal, allows addresses with 3 components, a base register, a scaled index register and an offset included in the instruction.
This choice of addressing modes was probably the only feature of the Intel 80386 ISA that was better than in the earlier Motorola MC68020. Motorola has chosen to implement almost all the addressing modes of VAX 11, not only the subset chosen by Intel, but the addressing modes omitted by Intel were not really useful, so eventually even Motorola abandoned them in the ColdFire? processors.
The second possible choice for the set of addressing modes appeared initially (around 1980) in one of the IBM RISC processors that were later developed into IBM POWER. This choice was also adopted by ARM, after it was published by IBM at one of the early RISC conferences.
This second choice is to allow addressing modes with only 2 components, a base register and an offset either in a register or in the instruction, but to allow updating the base register with the computed address.
I believe that the IBM choice is somewhat better, but both choices are acceptable. Any other set of addressing modes, e.g. RISC-V, is wrong, because it requires in almost all loops the insertion of extra instructions for updating the addressing registers.
Even if the hardware could execute the extra instructions in parallel, there would be a waste of resources anyway, because the extra instructions would occupy decoder slots and space in the instruction caches.
The IBM choice has the advantage that it does not require a second address adder and a shifter for scaling, but the disadvantage that it requires an extra write port into the register file.
From a software point of view, the IBM choice has the advantage that it is universal, i.e. it can be applied to any loop, while the Intel 80386 choice can be applied only to loops where the data structures have been chosen carefully. The reason is that, in order to avoid extra address updating instructions, the scaled index register must be the loop counter, and this, together with the limited set of values that may scale the index, forces that the ratios between the sizes of the elements of the arrays accessed during the loop must belong to the set of scale values (1, 2, 4, or 8 for Intel/AMD).
Nevertheless, these constraints for data layout are acceptable in most cases.
In order to evaluate which choice is cheaper from a hardware point of view, it is necessary to know exactly the technology used for implementation. If a second write port would be needed anyway for the register file due to other reasons, then the IBM choice would be certainly cheaper.
So, in conclusion, the set of addressing modes proposed by Agner is certainly much better than that of RISC-V.
I also completely agree with the use of a set of general registers instead of a dedicated flag register. " -- Adrian Bocaniciu -- https://www.agner.org/optimize/blog/read.php?i=424#424
(that was replying to a post that proposed the following addressing modes:
" Addresses are always relative to the instruction pointer, stack pointer or a register pointer. Absolute addressing does not need not be supported. The following addressing modes are supported:
Instruction pointer + 32 bit sign-extended offset
Instruction pointer + index register + 32 bit sign-extended offset
Base register + 8 or 32 bit sign-extended offset
Base register + index register + 32 bit sign-extended offset
Base register + scaled index register + 32 bit sign-extended offsetThe size of data operands or vector elements is always specified in the instuction. This size is used as a scale factor which is applied to all 8-bit offsets. For example, if the operand size is 32 bits = 4 bytes, then any 8-bit offset is multiplied by 4. 32-bit offsets are never scaled. The index register can also be scaled by the operand size.
Direct conditional and unconditional jumps and calls are always relative to the instruction pointer with 8-bit or 32-bit sign-extended offset, scaled by 4 because all instructions are aligned to addresses divisible by 4. " -- Agner )
---
you would think this would be relevant to me but i don't understand it and don't have time to, right now:
Optimizing Intel EPIC/Itanium2 Architecture for Forth http://www.complang.tuwien.ac.at/anton/euroforth2006/papers/tayeb.pdf
my guess is that it is not relevant, so i'm not putting it on my toread list, but i'm leaving it here in case i find time to read it
and here's a random paper about separate data and return stacks, haven't finished skimming it yet:
http://s3.eurecom.fr/docs/secucode09_francillon.pdf
---
Wikipedia defines GPR specifically in contrast to a split like data vs. address registers; apparently that split was a common thing in the past: https://en.wikipedia.org/wiki/Processor_register
however i did a quick search, and other sources contrast it to stuff like accumulators, stack machines, or just special control registers, or even stuff like stack pointer registers that some instructions treat differently
---
yarg, it would be so nice if:
maybe we should explore giving the 8-bit encoding one encoding format bit and the 16-bit 2 encoding format bits? This means finding another bit from the 16-bit encoding.
reducing the number of opcodes from 64 to 32 would be difficult. but what we were doing before was reducing the range of op0 (from 16 to 8). would that work here? Probably not; the range is already only 8, halving it again would make it 4, at which point it can't reah any of the 'free' registers, meaning that we essentially become a sort of accumulator/stack machine hybrid, where the output for every instruction can only be pushed to the stack (or written to TOS), necessitating a lot of otherwise avoidable CPs in between instructions.
ok let's look at reducing opcodes. We have 46 instructions as of this writing, 46-32 = 14. Recall that we can move some opcodes into 2-operand opcodes, too, if we're willing to go whole-hog on the 'MORE' (extended opcode) encoding. Can we do this?
we can knock off the convenience pointer adds, for 6 instructions. So we'd have 10 left. We can remove the offsets from loads and stores and cps, and move them all into MOREs. There's 12 of those, requiring 2 MOREs, so a net gain of 10. So yes, i think we can do this!
one issue though is this would greatly restrict the ability to add new instructions in BootX?. We'd pretty much have to give up on the idea that BootX? would add all of the remaining stuff that we could need to interface with the platform, and decide that stuff like floating point would probably come only in LOVM. That idea was already under pressure though. We could also make all the extra instructions that we were adding in BootX? into syscalls. That seems fairly attractive, actually.
also, the calculation above leaves out that we need one virtual pseudoinstruction for MORE. We could always make annotations 2-operand if we really have to, and/or sysinfo could also stand to be 2-operand (only 8 sysinfo slots, so we'd give up those constants, but that's totally fine), so i think there's no question that we'll make it.
---
yknow, in LOVM stack addr mode, we can already treat the TOS as a register via operand data 0. So maybe there's not a need for register 2 to be TOS? If we got rid of that, then the 16-bit encoding (Boot) would have one more register but it wouldn't be able to use TOS like a register. It could still mutate the TOS tho via SOMEOPERATION smallstack smallstack. Seems a little cleaner, and one more register is good, and if stack size is 4 then we have room for that. Maybe do it?
---
removed/old from boot:
---
going back and forth AGAIN about whether Boot should be 16 or 32 bit. If it's 32-bit, it doesn't HAVE to take up the whole 32-bit operands; we can restrict it to 8 regs per bank and no addr modes and yet still allow LOVM to have more. Just because Boot is 32-bit doesn't mean that LOVM can't also be.
although.. if Boot doesn't have addr modes then wouldn't that not be compatible, b/c it is assuming that some operands are immediate and some are register? Well we can work with that; we could simply require that the immediate ones are in the LOVM immediate addr mode format in those operands. And what about jump instruction formats? That could be the same in both, too.
would we lose the property that Boot instructions could just be 'executed directly' by LOVM delegating to the existing Boot intrepreter? Not sure, after all they are still compatible, it's just harder to detect them. Also, do we care? An efficient implementation will implement LOVM directly.
pros and cons (todo):
32-bit: pros:
cons:
first impression of the pros and cons: The cons are either about the beauty of the idea that Boot is 16 bits, or the loss of effiency of a LOVM->Boot system. The efficiency argument may not matter because ppl who care about efficiency can just implement LOVM directly. The beauty argument is nice, but i guess it depends; is the 'canonical' stack one with Boot at the bottom, or is LOVM at the bottom and Boot is just 'training wheels' to make it easier for ppl who don't have time to implement LOVM (or are intimidated by the large spec) and who don't care about efficiency?
That is to say, mb LOVM is the 'real' base language, and Boot is just sort of a sideshow bolted on to make it easier to get started?
and otoh, why much all this up just to have fp? Compilers don't need fp. Boot is a perfectly servicable basis set as long as you don't need fp or atomic ops, or if you are willing to do those thru syscalls.
---
also, i'm rethinking having the smallstacks in Boot (!). Right now we have 6 registers per bank plus 4 stack locs per bank, and two banks, so 20 register-like items (plus PC etc). That's perfect for 32-register processors, but it won't fit in 16 registers like on x86_64. Do we care? Even just 7 registers per bank woundn't fit (2 free regs doesn't leave enough for PC + pointer to further memory for interpreter + scratch register).
6 registers per bank with no smallstack would fit tho... just ban the use of register 1
and if smallstacks are stored in interpreter memory, then maybe no prob; you have:
well that's not so bad. So maybe the smallstacks can stay.
although maybe you'd want to store one or more of the program's registers in memory too, so that you can cache the smallstack TOS and maybe more.
or, if you only need 1 scratch register instead of 2, you can cache the TOS already. That would mean hitting memory when you really do need multiple scratch locations (eg to do a SWAP you might first have to store the TOS in memory, then use the TOS register as a second scratch reg, then restore the TOS), but hey.
---
most of the hardware ISAs (such as RISCV) seem to take pains NOT to have jump addresses in data after the instruction. Maybe there's some reason for that. At first glance it would seem impossible to encode a 32-bit jump in a single 32-bit instruction, and for the sake of finding and fixup of address constants i don't want to smuggle addresses via indirect jumps (or even to allow arithmetic on code addresses at all). But actually there's another solution; if you force the alignment of longjumps then you can reduce bits. E.g. if you force 64-bit alignment then you only need 29 bits instead of 32, etc.
i'm not sure if that really helps much because in one 32-bit instruction all we can manage is 21 bits (3*7; recall that we stole 1 bit from each operand for the 3 format encoding bits), unless we devote multiple opcodes to it (eg by devoting 2 opcodes we have 22 bits, by devoting 8 we have 24 bits etc). With 22 bits (2 opcodes spent) we have 10 bits to go to 32, so that means we can only longjump to the nearest 1KiB?. It might make more sense to spend 4 opcodes to get 23 bits of jump, so that at least the Boot instruction j9 can take us the rest of the way.
Still this would mean that the simplest thing for an assembler to do is to only start functions on a 512-byte boundary, which is quite a lot of waste.
i guess this is why the RISC-V design thesis says of SPARC: "SPARC’s architects wisely conserved opcode space by using smaller 13-bit immediates for most instructions. Alas, they squandered it in other ways. The CALL instruction supports unconditional control transfers to anywhere in the 32-bit address space with a single instruction. This simplifies the linking model, but optimizes for the vastly uncommon case at significant cost:CALLconsumesan entire 1/4 of the ISA’s opcode space.":
if you have 32 bits and you need 28 bits for a 32-bit jump's data, you only have 4 bits left, so you are spending 1/4th of opcode space.
so what is ideal? The RISCV design doc thinks that 28 is too much.
https://gist.github.com/erincandescent/8a10eeeea1918ee4f9d9982f7618ef68 thinks that 21 is too little:
" JAL wastes 5 bits encoding the link register, which will always be R1 (or R0 for branches)
This means that RV32I has 21-bit branch displacements (insufficient for large applications - e.g. web browsers - without using multiple instruction sequences and/or branch islands)
This is a regression from the v1.0 ISA!"so it sounds like https://gist.github.com/erincandescent/8a10eeeea1918ee4f9d9982f7618ef68 thinks that whatever "v1.0" of RISC-V had was good. v1.0 is here: https://www2.eecs.berkeley.edu/Pubs/TechRpts/2011/EECS-2011-62.pdf . On page 13 (PDF page 15) we see the J instruction (absolute jump), which has a 25-bit target offset. "The 25-bit jump target offset is sign-extended and shifted left one bit to form a byte offset, then added to the pc to form the jump target address. Jumps can therefore target a+-32 MB range."
So, 16-bit alignment is enforced, which is fine for RISC-V b/c their smallest instruction size is 16 bits, but maybe not so great for us, because we have 8-bit instructions.
If we spent 8 opcodes on jump, then we'd have 24 bits, take away one bit for sign, and we could have +-23 bits (+-8MB) with no alignment restrictions.
Note however that https://gist.github.com/erincandescent/8a10eeeea1918ee4f9d9982f7618ef68 speaks of web browsers. On my system, /usr/lib/firefox/libxul.so is 128MB. That would require 4 more bits, so 28 bits if no alignment restrictions, which again would be 1/4th of opcode space!
btw apparently x86_64 takes 6 bytes to encode a 32-bit jump: https://c9x.me/x86/html/file_module_x86_id_147.html
for now i'm going to stick with just encoding 32-bit immediate jump offsets in the instruction stream.
---
ah, the RISC-V design thesis explains why he thinks SPARC's registers windows were bad:
https://people.eecs.berkeley.edu/~krste/papers/EECS-2016-1.pdf
" To accelerate function calls, SPARC employs a large, windowed register file. At pro-cedure call boundaries, the window shifts, giving the callee the appearance of a freshregister set. This design obviates the need for callee-saved register save and restorecode, which reduces code size and typically improves performance. If the procedurecall stack’s working set exceeds the number of register windows, though, performancesuffers dramatically: the operating system must be routinely invoked to handle thewindow overflows and underflows. The vastly increased architectural state increases the runtime cost of context switches, and the need to invoke the operating system toflush the windows precludes pure user-level threading altogether. The register windows come at a significant area and power cost for all implemen-tations. Techniques to mitigate their cost complicate superscalar implementations inparticular. For example, to avoid provisioning a large number of ports across the entirearchitectural register set, the UltraSPARC?-III provisions a shadow copy of the activeregister window [86]. The shadow copy must be updated on register window shifts,causing a pipeline break on most function calls and returns. Fujitsu’s out-of-order exe-cution implementations went to similarly heroic lengths [5], folding the register windowaddressing logic into the register renaming circuitry. "
my comments vs us:
---
the RISC-V design document criticized some other architectures for 'poor support for position-independent data addressing'.
Maybe we need better support for that ourselves?
grep for 'position' in the RISC-V design document turns up the following (among other instances unrelated to this topic):
https://people.eecs.berkeley.edu/~krste/papers/EECS-2016-1.pdf says (page 20, PDF page 33):
" AUIPC, short foradd upper immediate topc, which adds a 20-bit upperimmediate to thepcand writes the result to registerrd. AUIPC forms the basis for RISC-V’spc-relative addressing scheme: it is essential for reasonable code size and performancein position-independent code. To demonstrate this point, Figure 3.3 shows code sequencesto load a variable that resides 0x1234 bytes away from the start of the code block, with andwithout AUIPC:
auipc x4, 0x1 lw x4, 0x234(x4)
jal x4, 0x4 lui x5, 0x1 add x4, x4, x5 lw x4, 0x230(x4) "
" Position-independent code without AUIPC could be implemented with a different ABI, rather thanusing thejalinstruction to read the PC. The MIPS PIC ABI, for example, guarantees thatr25alwayscontains the address of the current function’s entry point. But the effect is to move the extra instructionsto the call site, sincer25needs to be loaded with the callee’s address "
"The RISC-V JAL instruction ispc-relative and so can be used freely inposition-independent code...In MIPS, by contrast, the J and JAL instructions are pseudo-absolute: the lower 28 bits of the newpcare provided directly from the immediate, whereas the upper bits come from thepcof the delay slotinstruction. They are, as such, effectively useless in position-independent code; all unconditional controltransfers either use the conditional branch instructions (if the target is nearby) or a load from the globaloffset table followed by an indirect jump. SPARC wisely provided apc-relative CALL instruction, but provided no corresponding JUMP instruction
so, it sounds like they want 2 things:
So we should add an AUIPC instruction or something similar.
---
interestingly, RISC-V thinks it's a good idea for each compressed instruction to be a macro that expands into only a SINGLE uncompressed instruction:
"each RVC instruction must expand into a single RISC-V instruction. The reasonsfor this constraint are twofold. Most importantly, it simplifies the implementation andverification of RVC processors: RVC instructions can simply be expanded into their base ISAcounterparts during instruction decode, and so the backend of the processor can be largelyagnostic to their existence. Furthermore, assembly language programmers and compilersneed not be made aware of RVC: code compression can be left to the assembler and linker" [9]
---
"The RISC-V port of the GNU C Compiler has been programmed to favor the register subset that mostRVC instructions may address, but is otherwise ignorant of RVC’s existence. Of course, making the compilermore RVC-aware could avail more opportunities for code compression" [10]
---
i took some notes on the RISC-V COMPRESSED ISA EXTENSION chapter of the RISC-V design thesis https://people.eecs.berkeley.edu/~krste/papers/EECS-2016-1.pdf (notes already copied to plChAssemblyFrequentInstructions.txt)
some conclusions for us from those:
---
" Ranks Instruction Format Base Instruction Meaning 01 03 3 C.MV CR add rd, x0, rs2 Copy register 07 01 7 C.ADDI CI addi rd, rd, imm[5:0] Increment register 02 08 16 C.LWSP CI lw rd, offset[7:2](x2) Load word, stack 09 02 18 C.LW CL lw rd', offset[6:2](rs1') Load word 04 07 28 C.SWSP CSS sw rs2, offset[7:2](x2) Store word to stack -- note: above this point both ranks are always <10 03 16 48 C.LDSP CI ld rd, offset[8:3](x2) Load double-word, stack (RV64) 06 09 54 C.LI CI addi rd, x0, imm[5:0] Load immediate 10 06 60 C.LD CL ld rd', offset[7:3](rs1') Load double-word (RV64) 12 05 60 C.SW CL sw rs2', offset[6:2](rs1') Store word 05 14 70 C.SDSP CSS sd rs2, offset[8:3](x2) Store double-word to stack (RV64) 18 04 72 C.BNEZ CB bne rs1', x0, offset[8:1] Branch if nonzero 08 10 80 C.ADD CR add rd, rd, rs2 Add registers -- note: below this point both ranks are always >10 13 12 156 C.JR CR jalr x0, rs1, 0 Jump register 11 15 165 C.J CJ jal x0, offset[11:1] Jump 17 11 187 C.SRLI CB srli rd', rd', imm[5:0] Logical shift right, immediate 15 19 285 C.SLLI CI slli rd, rd, imm[5:0] Shift left, immediate 14 21 294 C.BEQZ CB beq rs1', x0, offset[8:1] Branch if zero 26 13 338 C.FLD CL fld rd', offset[7:3](rs1') Load double float 20 18 360 C.ADDIW CI addiw rd, rd, imm[5:0] Increment 32-bit register (RV64) 19 20 380 C.SD CL sd rs2', offset[7:3](rs1') Store double-word (RV64) 25 17 425 C.ANDI CI andi rd', rd', imm[5:0] Bitwise AND immediate 16 27 432 C.ADDI16SP CI addi x2, x2, imm[9:4] Adjust stack pointer -- note: below this point both ranks are always >20 21 24 504 C.JAL CJ jal x1, offset[11:1] Jump and link (RV32) 22 25 550 C.ADDI4SPNC IW addi rd', x2, imm[9:2] Compute address of stack variable 24 23 552 C.SRAI CB srai rd', rd', imm[5:0] Arithmetic shift right, immediate 30 22 660 C.AND CS and rd', rd', rs2' Bitwise AND registers 27 26 702 C.FLDSP CI fld rd, offset[8:3](x2) Load double float, stack 23 34 782 C.LUI CI lui rd, imm[17:12] Load upper immediate 28 29 812 C.FSDSP CSS fsd rs2, offset[8:3](x2) Store double float to stack 31 28 868 C.FSD CL fsd rs2', offset[7:3](rs1') Store double float 29 33 957 C.SUB CS sub rd', rd', rs2' Subtract registers 34 30 1020 C.ADDW CR addw rd, rd, rs2 Add 32-bit registers (RV64) 32 32 1024 C.OR CS or rd', rd', rs2' Bitwise OR registers 37 31 1147 C.XOR CS xor rd', rd', rs2' Bitwise XOR registers 33 35 1155 C.JALR CR jalr x1, rs1, 0 Jump and link register 35 37 1295 C.EBREAK CR ebreak Breakpoint 36 38 1368 C.FLW CL flw rd', offset[6:2](rs1') Load single float (RV32) 38 36 1368 C.SUBW CS subw rd', rd', rs2' Subtract 32-bit registers (RV64) 39 39 1521 C.FLWSP CI flw rd, offset[7:2](x2) Load single float, stack (RV32) 40 40 1600 C.FSW CL fsw rs2', offset[6:2](rs1') Store single float (RV32) 41 41 1681 C.FSWSP CSS fsw rs2, offset[7:2](x2) Store single float to stack (RV32) "
I think the apostrophe (single-quote) after registers indicate that the register can only be one of the first 8 registers.
so what can those instructions do that (our current) Boot (16-bit encoding) cannot?
i may be missing some things too
what can our current Boot do that those cannot?
---
the previous makes a case that indeed, if we didn't have to put a basis set of operations in the 16-bit encoding, we could more profitably use it to encode variants of frequent instructions
so, this suggests that we should make Boot a restricted subset of the 32-bit encoding
cp ~/prog/oot/boot/doc/boot_reference.md bootReferenceOld201027.txt
---
can we square the circle and let Boot be a subset of the 32-bit encoding, yet still treat the smallstack register as a register, without having any stack stuff?
what we want is to treat it as TOS.
i think we can do that; register 1 in register addr mode is TOS; register 0 in smallstack addr mode is push/pop; register n!=0 in smallstack addr mode is register read/write. So, we would introduce a little asymmetry to smallstack addr mode; register 0,smallstack acts as the special stack register, whereas everything else in smallstack acts as register-access-to-stack; and register 1 in register addr mode does what register 0 in smallstack addr mode 'should' do.
so now we'd have 7 regs in each bank. How would this square with a 16 register machine like x86_64? Not terribly well; for an interpreter we'd want one register for the PC, and one to point to the runtime's memory, so in this case we don't have any registers left for a runtime scratch register. Otoh i think if we are compiling to x86, we're probably good, because then we don't need to store a PC. If we did need a runtime scratch reg for the interpreter, what we could probably do is treat the link register specially, because in RISC-V's profiling, it's the 8th most common register, including the zero register (well; but is it the 16th most common, including our zero and null? probably not). I almost want to just covertly store it on the memstack, because that's where the Boot program is going to put it anyways, but i guess that doesn't fly b/c the memstack is visible to the Boot program.
i guess the thing to do would be to store one of the two callee-save registers (in each bank) in the interpreter's memory; that way there are two argument registers of each type in registers. This suggests that the two callee-save registers should be in a special place, like the highest-numbered registers, to help the programmer remember that they may be slower. That may be annoying though, if in LOVM we put additional arguments after those. Otoh in LOVM assembler we can give each register a descriptive name like ss s0 sp a0 a1 p0 p1 (smallstack, smallstack position 0, memstack pointer, argument 0, argument 1, persistent (callee-save) 0, persistent 1), etc, so it won't really matter.
---
section "%rip-relative addressing" of https://cs61.seas.harvard.edu/site/2018/Asm1/ explains that, yeah, we probably do want a PC-relative LOAD somewhere. Right now in Boot we can do this already; use lpc to load the address, then LOAD from that. But remember that for addr modes
---
here's what that "red zone" thing is: it's just a guarantee by the OS that there is some memory below the stack that is pre-allocated (apparently in x86_64 the OS watches the stack pointer and allocates more memory for it as needed!)
" The operating system knows that %rsp points to the stack, so if a function accesses nonexistent memory near %rsp, the OS assumes it’s for the stack and transparently allocates new memory there. So how can a program “run out of stack”? The operating system puts a limit on each function’s stack, and if %rsp gets too low, the program segmentation faults.
The diagram above also shows a nice feature of the x86-64 architecture, namely the red zone. This is a small area above the stack pointer (that is, at lower addresses than %rsp) that can be used by the currently-running function for local variables. The red zone is nice because it can be used without mucking around with the stack pointer; for small functions push and pop instructions end up taking time. " [11]
---
random note in a pull request for LLVM for a tail call calling convention that may be of interest:
" There are four cases this handles: regular calls safe, friendly, good, ABI-preserving, opportunistic tail calls, called "sibcalls" in this code musttail calls, which, because of the IR verifier checks, we know will not require moving the return address ABI changing, return-address-moving, guaranteed tail calls " [12]
---
interestingly,
" @Odrinwhite The strategy of "wait until the stack overflows and then activate TCO" is used in Chicken Scheme (and other compilers as well). " [13]
---

 " --
" --