![[Home]](http://www.bayleshanks.com/cartoonbayle.png)
If you're looking for a bit of an unconventional entry point, I recommend the seminal text 'Elements of Information Theory' by T. Cover (skipping chapters like Network Information/Gaussian channel should be fine), paired with David MacKay?'s 'Information Theory, Inference and Learning Algorithms'. Both seem available online:
http://www.cs-114.org/wp-content/uploads/2015/01/Elements_of_Information_Theory_Elements.pdf
http://www.inference.org.uk/itprnn/book.pdf
They cover some fundamentals of what optimal inference looks like, why current methods work, etc (in a very abstract way by understanding Kolmogorov complexity and its theorems and in a more concrete way in MacKay?'s text). Another good theoretical partner could be the 'Learning from data' course, yet a little more applied: (also available for free)
https://work.caltech.edu/telecourse.html
Excellent lecturer/material (to give a glimpse, take lecture 6: 'Theory of Generalization -- how an infinite model can learn from a finite sample').
Afterward I would move to modern developments (deep learning, or whatever interests you), but you'll be well equipped.
reply
https://en.m.wikipedia.org/wiki/Convergent_cross_mapping
I have been using Spacy3 nightly for a while now. This is game changing.
Spacy3 practically covers 90% of NLP use-cases with near SOTA performance. The only reason to not use it would be if you are literally pushing the boundaries of NLP or building something super specialized.
Hugging Face and Spacy (also Pytorch, but duh) are saving millions of dollars in man hours for companies around the world. They've been a revelation.
reply
JPKab 12 hours ago [–]
Everything in the above paragraph sounds like a hyped overstatement. None of it is.
As someone that's worked on some rather intensive NLP implementations, Spacy 3.0 and HuggingFace? both represent the culmination of a technological leap in NLP that started a few years ago with the advent of transfer learning in NLP. The level of accessibility to the masses these libraries offer is game-changing and democratizing.
reply
-- [2]
binarymax 14 hours ago [–]
I have lots of experience with both, and I use both together for different use cases. SpaCy? fills the need of predictable/explainable pattern matching and NER - and is very fast and reasonably accurate on a CPU. Huggingface fills the need for task based prediction when you have a GPU.
reply
danieldk 12 hours ago [–]
Huggingface fills the need for task based prediction when you have a GPU.
With model distillation, you can make models that annotate hundreds of sentences per second on a single CPU with a library like Huggingface Transformers.
For instance, one of my distilled Dutch multi-task syntax models (UD POS, language-specific POS, lemmatization, morphology, dependency parsing) annotates 316 sentences per second with 4 threads on a Ryzen 3700X. This distilled model has virtually no loss in accuracy compared to the finetuned XLM-RoBERTa? base model.
I don't use Huggingface Transformers, but ported some of their implementations to Rust [1], but that should not make a big difference since all the heavy lifting happens in C++ in libtorch anyway.
tl;dr: it is not true that tranformers are only useful for GPU prediction. You can get high CPU prediction speeds with some tricks (distillation, length-based bucketing in batches, using MKL, etc.).
[1] https://github.com/tensordot/syntaxdot/tree/main/syntaxdot-t...
reply
ZeroCool?2u 13 hours ago [–]
SpaCy? and HuggingFace? fulfill practically 99% of all our needs for NLP project at work. Really incredible bodies of work.
Also, my team chat is currently filled with people being extremely stoked about the SpaCy? + FastAPI? support! Really hope FastAPI? replaces Flask sooner rather than later.
reply
langitbiru 12 hours ago [–]
So with SpaCy? 3.0, HuggingFace?, do we still have a reason to use NLTK? Or they complement each other? Right now, I lost track of the progress in NLP.
reply
gillesjacobs 9 hours ago [–]
NLTK is showing its age. In my information extraction pipelines, the heavy lifting for modelling is done by SpaCy?, AllenNLP?, and Huggingface (and Pytorch or TF ofc).
I only use NLTK since it has some base tools for low-resource languages for which noone has pretrained a transformer model or for specific NLP-related tasks. I still use their agreement metrics module, for instance. But that's about it. Dep parsing, NER, lemmatising and stemming is all better with the above mentioned packages.
reply
Object detection:
Try and combine all (or many) of the classifiers (not via ensemble methods, but by combining their core concepts to make a new algorithm).
eg combine random forest, neural net, svm, genetic alg, stochastic local search, nearest neighbor
eg deep neural decision forests seem to be an attempt to combine the first two
perhaps some of the combinations would only be a linear combination of the output scores, but it would be better to find 'the key idea(s)' of each one.
https://blog.openai.com/robots-that-learn/
How to avoid machine learning pitfalls: a guide for academic researchers
When CPPNs are used to generate the connectivity patterns of evolving ANNs, the resulting algorithm, also from my lab, is called HyperNEAT (Hypercube-based NEAT, co-invented with David D’Ambrosio? and Jason Gauci) because under one mathematical interpretation, the CPPN can be conceived as painting the inside of a hypercube that represents the connectivity of an ANN. Through this technique, we began to evolve ANNs with hundreds of thousands to millions of connections. Indirectly encoded ANNs have proven useful, in particular, for evolving robot gaits because their regular connectivity patterns tend to support the regularity of motions involved in walking or running. Researchers like Jeff Clune have helped to highlight the advantages of CPPNs and HyperNEAT? through rigorous studies of their various properties. Other labs also explored different indirect encoding in neuroevolution, such as the compressed networks of Jan Koutník, Giuseppe Cuccu, Jürgen Schmidhuber, and Faustino Gomez."
"
moultano 5 hours ago [-]
A practical issue for Naive Bayes that also infects linear models is bias w.r.t. document length. Typically when you are detecting a rare, relatively compact class such as sports articles (or spam) you will tend to have a strongly negative prior, many positive features, and few negative ones. As a consequence, as the length of your text increases, not only does the variance of your prediction increase, but the mean tends to as well. This leads to all very long documents being classified as positive, regardless of their text. You can observe this by training your model and then classifying /usr/dict/words.
This is the most common mistake I've seen in production use of linear models on document text. Invariably, they'll misfire on any unusually long document.
reply
mooman219 3 hours ago [-]
I agree, there are issues with NB such as the ones you brought up. I don't think document length is the real offender here though. This really boils down to noise and how well you filter and devalue it. Stacking more filters like stemming, stopwords, and high frequency features definitely helps in this case to the point where longer documents can actually improve accuracy. Additionally, tuning your ngram lengths or using variable lengths, choosing between word or character ngrams, and limiting your distribution size all will help depending on what you're trying to categorize.
reply
intune 4 hours ago [-]
Is there some way to normalize the document length?
reply
moultano 4 hours ago [-]
Lots of reasonable hacks.
1. Use only the beginning of the document, as that's probably the most important part anyways, and it's fast.
2. Divide the sum of your feature scores by sqrt(n) to give it constant variance, and hopefully keep it comparable with your prior.
3. Split the doc into reasonably sized chunks, and average their scores rather than adding them.
reply
Houshalter 3 hours ago [-]
You can use term frequency instead of binary features. This is invariant to the size of the document. This is called multinomial naive Bayes: https://en.m.wikipedia.org/wiki/Naive_Bayes_classifier#Multi...
reply
moultano 2 hours ago [-]
This is not invariant to the size of the document (though agreed, generally better). It doesn't solve the problem of having mostly positive features and a negative prior.
Stated more formally, your model is b + wᵀx. Generally, b is < 0, and E[wᵀx] > 0. As the document grows, wᵀx tends to dominate b. You'll have bias with length as long as E[wᵀx]≠0 and there aren't any constraints on w that would force this.
reply "
" There is a temptation to use just the word pair counts, skipping SVD, but it won't yield in the best results. Creating vectors not only compresses data, but also finds general patterns. This compression is super important for less frequent words (otherwise we get a lot of overfitting). See "Why do low dimensional embeddings work better than high-dimensional ones?" from http://www.offconvex.org/2016/02/14/word-embeddings-2/. "
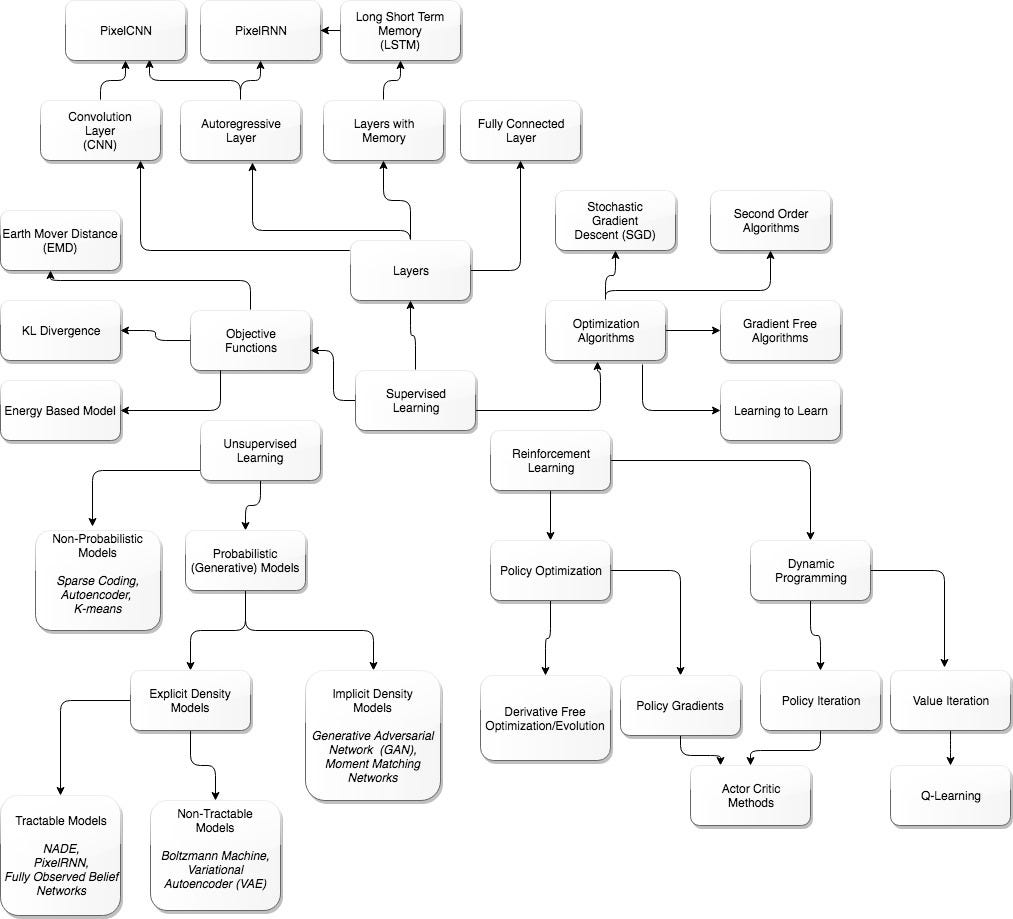
andy99 2 days ago [–]
Uncertainty quantification and OOD detection in machine learning. It's on some people's radar, but has the potential to get ML adopted much more widely as people understand what it is actually really good at, and stop giving it things to do that it's bad at.
For a great recent example that get at some of this, see "Does Your Dermatology Classifier Know What It Doesn't Know? Detecting the Long-Tail of Unseen Conditions" - https://arxiv.org/abs/2104.03829
I'm not affiliated with this work but I am building a company in this area (because I'm excited). Company is in my profile.
reply
---
https://arxiv.org/abs/2011.11082 Massively Parallel Causal Inference of Whole Brain Dynamics at Single Neuron Resolution mpEDM Empirical Dynamic Modeling (EDM)
---
http://graphics.stanford.edu/courses/cs468-20-fall/schedule.html non-Euclidean machine learning
http://web.stanford.edu/class/cs224w/ CS224W: Machine Learning with Graphs
http://graphics.stanford.edu/courses/cs233-21-spring/ Geometric and topological data analysis
https://www-users.cs.umn.edu/~saad/PDF/umsi-2009-31.pdf TRACE OPTIMIZATION AND EIGENPROBLEMS IN DIMENSIONREDUCTION METHODS
---
machine scientific discovery
https://scitechdaily.com/artificial-intelligence-discovers-alternative-physics/
Discovering faster matrix multiplication algorithms with reinforcement learning
---
https://github.com/ctgk/PRML Python codes implementing algorithms described in Bishop's book "Pattern Recognition and Machine Learning"
---
---
https://www.google.com/search?q=expert+exponential+learning+weights+ensemble
---
the transformer paper: https://arxiv.org/abs/1706.03762 Attention Is All You Need
---
