![[Home]](http://www.bayleshanks.com/cartoonbayle.png)
--
if you take a descendent of the root node, and put it in its own variable, but if you change that variable you want to change the original graph, then you have to use references;
def f(bob): &a = &bob.age &a = 32 &bob.age == 32
(note that even though you got a bob, you could use it as &bob; but that you are required to say &bob.age down below when reading it later in the same lexical context, to remind you that bob may have been mutated via a side effect)
otoh if you just want to change a node in one lvalue, you dont need a reference, even though there may be side-effects (including cross-perspective side effects) within the node:
def f(bob): bob.age = 32 bob.age == 32
btw i'm not actually sure that the first case is totally a good idea; i sort of feel that as this is only a 'local side effect', that you should be able to just say bob.age == 32 in the last line, without a reference (hence without an ampersand).
after all, what if later you want to make a copy of bob.age. &bob.age would seem to say that you are taking another reference. so you shouldn't have to use an ampersand on later r-values.
and also, what if you want to copy a, and not take a reference of it? hmm.
how about:
&a = &bob.age &a = 32 bob.age == 32 b = a b = 30 &c = &b &c = 40 b == 40 a == 32 bob.age == 32
so the rules are:
hmm.. maybe it would make more sense to do this:
a = &bob.age &a = 32 bob.age == 32 b = a b = 30 c = &b &c = 40
bob.age == 32 a == 32 b == 40 c == 40
c = 50 c = 23 c == 23 b == 40
so:
what about when calling functions? if you call the function with an ampersand on the argument, like f(&x), and f()'s signature expects a reference, then assignments into this reference act actually assign into the reference. However, if f()s signature expects a non-reference, this is an error; you should pass as f(x).
if otoh you are calling a function for mutation in-place, then use the ampersand to assign the result into the reference; in this case not using the ampersand is illegal to prevent mistakes
a = 30 b = &a c = &a d = a
a++
hmmm this is kinda dumb because "a++" and "&c++" do the same thing. So really a should have to be a reference too!
so maybe you can only take a reference of something that is already a reference
a = 30 b = &a
&a = 30
maybe we have to use C notation, with two operators for ref and deref, after all?
or just always use ampersands for reference vars, and dont let links be broken?
or.. i guess this is how Python references work.. a top-level reassignment breaks the link, but accessing a member goes thru the ref. e.g.:
alice.age = 10 bob.age = 20 &a = alice.age &b = &a &c = bob.age &d = alice &e = &d &f = bob &b = &c &e = &f
&a = 30 &b = 40 &c = 50 &d.age = 60 &e.age = 70 &f.age = 80
alice.age == 10 bob.age == 20 &a == 30 &b == 40 &c == 50 &d.age == 60 &e.age == 80 &f.age == 80
hmm..
how about:
so &a = b assigns b into the reference a; &a = &b either copies b and takes a reference to the copy, or if b is a reference, copies b into a (links the references)
the only thing we lose is the ability to take a reference to a reference..
If we want to do that, C's notation might be clearer:
alice.age = 10 bob.age = 20
alice.age == 10 bob.age == 20
huh.. that's interesting.. we never used &.. that's because we're not allowed to take references of non-references..
--
--
maybe we should use * for deref and use & for something else, to match C (see jasperDataNotes1):
alice.age = 10 bob.age = 20
alice.age == 10 bob.age == 20
since we aren't allowed to take a ref to a non-ref (that would cause side effects)
hmm.. then again what if we want to create a handle? oh.. i got it..:
alice.age = 10 bob.age = 20
hmm i dunno if that's good b/c
handle_a = 30
i fear we may be looking at this in the wrong way.. we want a sigil to represent a warning that a variable might be changed by a side effect from elsewhere. If one node has a reference to another, then the deref of the first node can be changed by changing the second, and the second can be changed by changing the deref of the first. Whether one node references another, or the other references the first, is besides the point. Both of them need this sigil.
Furthermore, we do NOT need the sigil if the side effect exposure is only to another node in the same graph.
Perhaps instead of talking about references we should talk about binding and unbinding nodes across graphs.
References can be a different, more complicated concept (i think they can just be represented in arcs between structures...hmmm...arcs between graphs...).
So maybe:
alice.age = 10 bob.age = 20 &a = alice.age bind(b,a) &c = bob.age unbind(b,a) bind(b,c)
&a = 30 &b = 40 &c = 50
alice.age == 10 bob.age == 20 &a == 30 &b == 50 &c == 50
hmmm...arcs between graphs... are bind and unbind merely operations on some metagraph which has the ability to refer to various other graphs? could such metagraphs be first class? are they side-effectful?
another way to look at it.. there is really only one graph in the whole program between all mutable objects (which also includes all of their immutable values). any stateful variables in the program are just a subset of this graph. when two nodes are bound, that just means that there is really only one node in this graph, but that there are multiple other nodes that point to it. when two nodes in different variables are bound, that just means that each of these variables contains an arc to the one node; in the larger graph, these two variables are just subsets. So, in this viewpoint, &x just means that &x is a subset of the total graph such that (a) it is mutable, and (b) it contains or might contain at least one arc to a node outside of itself.
so, instead of 'bind' and 'unbind', we just point arcs from two other nodes at the same node (we could still provide bind and unbind for convenience). we have operations to take a part of the total graph defined by boundaries and put it in its own variable; we have operations to combine the graphs in two variables into a third; we have operations to make copy-on-write copies of the part of a graph in a variable.
do the variables have any independent notion of what subset of the graph they correspond to? maybe it would be better if not. So, when i say you take 'part of a graph', either you just literally assign a node to a variable and the variable 'contains' everything reachable from there, or you have some operation to copy-on-write and sever below a boundary. In any case, functions on a graph often take a boundary argument. But then isn't this an argument for having the root node 'know' the current boundary and apply it before functions get to look, rather than placing the burden on every other function to take one?
so maybe each variable has a 'boundary mode' which is a choice of boundary label. we can also have 'anonymous boundary creation' which creates a boundary with an unknown label but immediately assigns that label to the specified variable's boundary mode.
should we have a different sigil for mutable variables that have side-effects on others but that cannot themselves experience side effects from others?
actually i think those shouldn't need a & at all. if you pass in an array to something that thinks it got a pure value and sorts it in place, but you maintain a reference to each element and their original array position so that after sorting you can calculate an argsort, what's the problem there?
--
haskell runST: lets you do a computation with state then after you're done throw away the state and have a pure result "Encapsulating it all" -- http://research.microsoft.com/en-us/um/people/simonpj/papers/haskell-retrospective/HaskellRetrospective-2.pdf
--
nimrod has var/const/let, rust has mut/static/let
idea is mutable variable, compile-time evaluated constant (error if cannot be evaluated at compile time), single-assignment variable
-- section 2.2 of http://www.lysator.liu.se/c/bwk-on-pascal.html complains that a system without closures, in which you only have variables with lexical scope, so in place of closures you must define a persistent semi-global variable, is annoying.
--
mb have not just one but TWO sigils for impure data, e.g. one for 'others can affect this' (this may be aliased) and one for 'this can affect others' (this holds an alias or pointer to others). both are like impure functions, the first is nondeterministic, the second is side effects
--
mb each data has an 'home base' node in one net, and the sigils are 'input' or 'output' from/to other nets
in this case maybe there is only one sigial, not too, representing when the node is merely a 'symlink' to, or equivalently, 'alias' of, another, real node. note that 'partials' are aliases, e.g. if N is a net, then if you do y = N.a, y can either be a C.O.W. copy of N.a, or an alias into N.
--
if you have an alias, can you still put in a boundary without affecting the original?
--
perhaps alias-ness and boundary should be per-perspective
--
if alias-ness is per-perspective, then the compiler can't do some optimizations on pure functions without statically knowing the perspectives, e.g. in the presence of dynamic choices of perspective
--
see 'Pure functions' in http://dlang.org/function.html
--
whether or not data is aliased depends on the current object boundaries in effect
e.g. every variable in scope will be included on some list like Python's locals() or globals(). But the references from the list of in-scope variables shouldn't 'count' as aliasing.
--
could use the Plan 9/Inferno 'everything is a file' approach to APIs:
" Filesystems, again!
There are some things that Acme can do that other editors would require a series of hacks for, though. Since the focus in Inferno is on filesystem-based interfaces, Acme does, of course, provide one. Running Acme’s win command, or just executing wm/sh& from inside Acme, will give you a shell that can see /mnt/acme. Like any other piece of the namespace, you can export(4) the /mnt/acme filesystem as well.
What can you do with this filesystem? Since Acme exposes anything one might care to do as part of the filesystem, really you can do anything you can do in Acme: highlight text, undo changes, execute a search, etc. You can completely control the editor from the shell, or even remotely from across the internet. The editor as a whole can be controlled from the top level of the filesystem, and there is a directory for each open Acme window, for controlling that window specifically, getting the contents of buffers, etc. Opening up Acme and then reading /mnt/acme/1/body will read the in-editor text of the first window which can be useful if the text is not saved or even associated with a file. Writing to it will put the text into the window, so arbitrary scripts can be used to manipulate text. There’s a special directory new that opens a new window when it is touched, so the output of a command can be opened up in a new editor window by redirecting its output to /mnt/acme/new/body. "
--
instead of distinguishing things which ARE aliased or contain aliases, could distinguish things that COULD BE aliased or contain aliases, e.g. like variables vs. values
so, a value can not contain any variables. but a variable can contain values. the values in a variable can be changed (swapped with other values). part of a variable can be taken as an alias or as a copy or as a value, or even as a move (rather, a swap). copying a variable into a value can either be forced immediately (if the other party is going to change it outside of this process's Jasper runtime), or copy-on-write.
---
this whole thing is a good read but i'll also discuss excerpts:
http://blog.paralleluniverse.co/post/64210769930/spaceships2
---
" Local Actor State
In Erlang, actor state is set by recursively calling the actor function with the new state as an argument. In Pulsar, we can do the same. Here’s an example from the Pulsar tests:
(is (= 25 (let [actor (spawn #(loop [i (int 2) state (int 0)] (if (== i 0) state (recur (dec i) (+ state (int (receive)))))))] (! actor 13) (! actor 12) (join actor))))
However, Clojure is all about managing state correctly. Since only the actor can set its own state, and because an actor cannot run concurrently with itself, mutating a state variable directly shouldn’t be a problem. Every Pulsar actor has a state field that can be read like this @state and written with set-state!. Here’s another example from the tests:
(is (= 25 (let [actor (spawn #(do (set-state! 0) (set-state! (+ @state (receive))) (set-state! (+ @state (receive))) @state))] (! actor 13) (! actor 12) (join actor))))
Finally, what if we want several state fields? What if we want some or all of them to be of a primitive type? This, too, poses no risk of race conditions because all state fields are written and read only by the actor, and there is no danger of them appearing inconsistent to an observer. Pulsar supports this as an experimental feature (implemented with deftype), like so:
(is (= 25 (let [actor (spawn (actor [^int sum 0] (set! sum (int (+ sum (receive)))) (set! sum (int (+ sum (receive)))) sum))] (! actor 13) (! actor 12) (join actor))))
These are three different ways of managing actor state. Eventually, we’ll settle on just one or two (and are open to discussion about which is preferred). "
---
want some sort of way to say 'this subroutine has access to these containers of state', where 'these containers of state' might be subsets like {STDERR}, {STDERR, STDOUT}, {STDERR, database connection}, {STDERR, reference variables &P and &Q, database connection}, {STDERR, reference variable &Q, STM domain &R, non-uniform memory domain &S, read-only access to TCP port &p , read-only access to IPC/intrathread channel &c}, etc.
--
in general you want to be careful about persistent state, so jasper should require a sigil when you access a non-local/persistent 'mutable variable' as opposed to just an immutable value. this includes when you call a function that accesses or changes such state, e.g. an object method, or a function with a closure.
however, you don't necessarily care about any state changes made by a subroutine you call, just state changes in those parts of world state that you care about.
e.g. if subroutine A calls internal subroutine B that temporarily creates its own persistent state via a closure, but this closure is always deleted before A returns, then A's caller doesn't care
most of the time you don't care if a supposedly pure function triggers a debug routine writes to a log file, or prints to STDERR
you don't care if a subroutine that you call offloads most of its work to a cluster supercomputer that it accesses over the network in order to compute the pure function that you need
in most cases you don't care if your call to the random number generator affects its internal state, even if another part of your application will later call that same random number generator and be affected by the change in internal state
so maybe we need to give jasper routines a way to express which parts of state they care about, and make the stateful sigil relative to that.
--
" Clojure has transients, which basically means "inside this function, use a mutable value under the hood while building up the value, but make it immutable before it's returned". " -- http://augustl.com/blog/2014/an_immutable_operating_system/
---
nock vs human language: in Nock, the "subject" means state. In human language, the "subject" is often "I". is there some sense or set of conditions in which state = I?
--
Hoon paradigm for handling 'subjects' (state) might be inspiration for ways to manage state even in other noncombinatorial, languages. (dunno yet if its good, have to learn Hoon first)
--
" You can create a goroutine with any function, even a closure. But be careful: a questionable design decision was to make closures capture variables by reference instead of by value. To use an example from Go's FAQ, this innocent looking code actually contains a serious race:
values := []string{"a", "b", "c"}
for _, v := range values {
go func() {
fmt.Println(v)
done <- true
}()
}
The for loop and goroutines share memory for the variable v, so the loop's modifications to the variable are seen within the closure. For a language that exhorts us to "do not communicate by sharing memory," it sure makes it easy to accidentally share memory! (This is one reason why the default behavior of Apple's blocks extension is to capture by value.) " -- http://ridiculousfish.com/blog/posts/go_bloviations.html#go_concurrency
--
do 'bits of state' share a lot of characteristics with 'rooms' in MMO worlds or in VR, or with the autonomous 'worlds' in hyperlinked MMOs such as the opensim hypergrid?
should we call them 'rooms' or 'worlds'?
--
places you put ppl in: rooms, worlds, cities, countries, houses, buildings, towns, places
places you put inanimate objs in: boxes, shelves, cabinets, drawers, carts, trays, containers, basket, bag
agents vs inanimate: agents move on their own, respond to stimuli, have goals/wants/ beliefs
words for animate animals: agent, actor, person, entity, animal
should we have 'plants' and 'animals'?
--
argues that actors are sufficient for separating purely functional stuff, and easier to understand, so monads are not needed:
http://gbracha.blogspot.com/2011/01/maybe-monads-might-not-matter.html?m=1
--
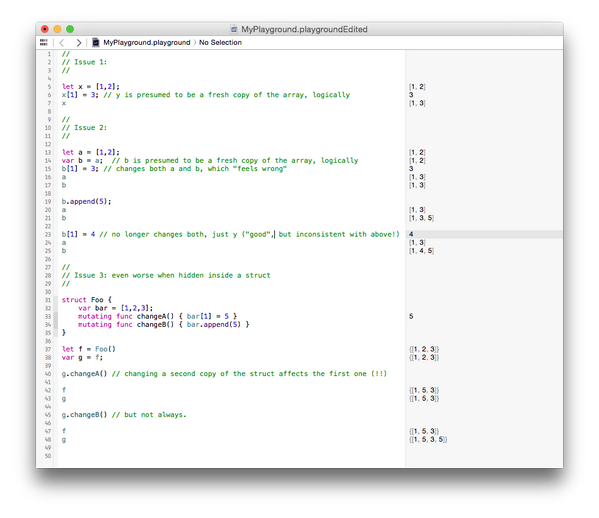 https://twitter.com/dwarfland/status/476310789763395584/photo/1
https://twitter.com/dwarfland/status/476310789763395584/photo/1
illustration of (Python-like) confusing use of references in Swift:
let x = [1,2]; x[1] = 3; x [1,3]
let a = [1,2] var b = a b[1] = 3 a [1,3] b [1,3]
b.append[5] a [1,3] b [1,3,5] note inconsistency with the above
even worse when hidden inside a struct struct Foo { var bar = [1,2,3]; mutating func changeA() {bar[1] = 5} mutating func changeB() {bar.append(5) }
let f = Foo(); var g = f;
g.changeA()
f {[1,5,3]} g {[1,5,3]}
g.changeB()
f {[1,5,3]} g {[1,5,3,5]}
note (bayle): this is the same behavior as Python but even more confusing if you though Swift's 'let' meant an immutable value type, in contrast to Swift's 'var' which would permit reference types, e.g. if you thought that things defined with 'let' would be referentially transparent. Actually it appears that 'let' just means you can't reassign to that variable, which isn't as conceptually useful and which is confusing.
---
mb have multimethods (and unattached functions in general), but then for encapsulating state (or rather, for non-referentially transparent operations), always use single-dispatch objects with methods like beautiful Io? (i mean, Io has single-dispatch objects, not that Io has both of these)
so addition could be a normal function, as could sprintf, but printf would be an object method
note that aliasable referencence variables are non-referentially transparent and hence must be objects
(purely stochastic functions are technically non-referentially transparent but we'll treat them as if they were; what we are really concerned about is spooky action at a distance, e.g. aliasing)
if you do this, though, then what about accesses to aliased reference variables which are 'within one of the current monads'? this should logically be done lazily, because accesses to something 'within one of the current monads' should not 'count' as aliased reference right? but in that case since there we may have (commutative) multiple monads, this doesn't jive with the 'one receiver' for non-referentially transparent things (although maybe it does, since each such thing's 'receiver' just means either that the thing itself is accessed only via a API/set of methods, or that accesses to it are syntactic sugar for calls to methods of its monad?).
--
this suggests a way to have a subset of commutative monads in an OOP-like way. a monad would correspond to a portion of state encapsulated in an object, with a set of methods (in some cases these methods could be accessed explicitly, in others you what looks like fields but such that accesses to these fields are syntactic sugar for getter and setter methods on the object). To say a function is 'in' the monad means two things; (a) there is a 'taint' on the type, (b) the function body can call the monad methods (possibly we could have a dynamic scoping mechanism so that you don't have to type the monad's name all the time).
so, e.g. in the IO monad we have:
deffunction f(int k) using monads IO i, IntState? s: i.printf('hi') x = s.lookup_int('x') y = i.ask_user_to_input_int() new_x = x + y + k s.change_int('x', new_x) s.commit()
so really all this is, is passing in those two objects as parameters:
deffunction f(int k, IO i, IntState? s) i.printf('hi') x = s.lookup('x') y = i.ask_user_to_input_int() new_x = x + y s.change('x', new_x) s.commit()
and if you have dynamic scoping then mb you could leave out the 'i.'s and 's.'s, as if you could leave out the 'self.' in Python
with the addition that we keep track of the 'type taint' of using i and s, and that this possibly has some impact on when we do laziness/strictness.
in Haskell what would happen is that we have, instead of a bunch of object parameters, a tower of monads. (i think) Each tail of lines within the 'do' syntax corresponds to a function that takes the previous state and computes a new state. This tail is passed to the monad lowest on the ladder to determine what to do. Then if that monad doesn't do anything, it passes it up the ladder. This 'passing up the ladder' is not built-in, it is explicitly implemented via a monad transformer.
hmm so we haven't quite captured monads, because in the above we've provided no way for any of the monads to alter control flow. e.g. the above doesn't give any way to do e.g. a backtracking monad which so i guess the above is only really a special case of monads, which in Haskell is done by monads just to use monads for as much as possible, but which in an OOP language could be implemented as above.
the remaining generality, e.g. letting the monad itself control execution via converting the function into a long expression using the monadic 'bind' function, is what makes monads non-commutative.
but at least this shows that some of the monads in haskell are really simple things that don't use the full power of monads, and are commutative because of that, and can be conceptualized in a simpler way using OOP
--
